

Wydanie GLM-5, ujawnionego w tym tygodniu przez chińskie Zhipu AI (publicznie markowane jako Z.AI / zai-org w wielu kanałach deweloperskich), stanowi kolejny krok w przyspieszającym tempie publikacji dużych modeli. Nowy model pozycjonowany jest jako flagowiec Zhipu: większy skalą, dostrojony do zadań agentowych o długim horyzoncie oraz zbudowany z wyborami inżynieryjnymi mającymi na celu obniżenie kosztu wnioskowania przy zachowaniu długiego kontekstu. Wczesne raporty branżowe i notatki praktyków sugerują istotne zyski w kodowaniu, wieloetapowym rozumowaniu i orkiestracji agentów w porównaniu z wcześniejszymi iteracjami GLM — a w niektórych testach rzuca wyzwanie nawet Claude 4.5.
Czym jest GLM-5 i kto go zbudował?
GLM-5 to najnowsze duże wydanie w rodzinie GLM: obszerny, open-source’owy model bazowy opracowany i opublikowany przez Z.ai (zespół stojący za serią GLM). Ogłoszony na początku lutego 2026 r., GLM-5 jest przedstawiany jako model następnej generacji, specjalnie dostrojony do zadań „agentowych” — tj. wieloetapowych przepływów pracy o długim horyzoncie, w których model musi planować, wywoływać narzędzia, wykonywać zadania i utrzymywać kontekst dla długich rozmów lub zautomatyzowanych agentów. Wydanie wyróżnia się nie tylko projektem modelu, ale także sposobem i miejscem treningu: Z.ai wykorzystało mieszankę krajowego chińskiego sprzętu i łańcuchów narzędzi w ramach dążenia do samowystarczalności.
Zgłaszane parametry architektury i treningu obejmują:
- Skalowanie parametrów: GLM-5 skalowany do około 744B parametrów (z mniejszą liczbą „aktywnych” ekspertów wskazywaną w niektórych notach technicznych, np. 40B aktywnych), w porównaniu z wcześniejszymi rozmiarami rodziny GLM-4 rzędu 355B/32B aktywnych.
- Dane do pretrenowania: Rozmiar korpusu treningowego wzrósł rzekomo z ~23 bilionów tokenów (generacja GLM-4) do ~28.5 biliona tokenów dla GLM-5.
- Rzadka uwaga / DeepSeek Sparse Attention (DSA): Schemat rzadkiej uwagi mający zachować długi kontekst przy jednoczesnym obniżeniu kosztu obliczeń podczas wnioskowania.
- Akcent projektowy: wybory inżynieryjne skoncentrowane na orkiestracji agentów, rozumowaniu w długim kontekście oraz opłacalnym kosztowo wnioskowaniu.
Pochodzenie i pozycjonowanie
GLM-5 bazuje na linii obejmującej GLM-4.5 (wydany w połowie 2025 r.) oraz kilka iteracyjnych aktualizacji, takich jak 4.7. Z.ai pozycjonuje GLM-5 jako skok od „vibe coding” (szybkie, jednostopniowe generowanie kodu) w stronę „agentic engineering”: trwałego rozumowania, orkiestracji wielu narzędzi i syntezy systemów w długich oknach kontekstowych. Materiały publiczne podkreślają, że GLM-5 zaprojektowano do obsługi złożonych zadań inżynierii systemów — budowania, koordynowania i utrzymywania wieloetapowych zachowań agentów, a nie tylko odpowiadania na odizolowane pytania.
Jakie są nowe funkcje w GLM-5?
Najważniejsze zmiany architektoniczne
- Ogromne rzadkie skalowanie (MoE): GLM-5 przechodzi na znacznie większą, rzadką architekturę Mixture-of-Experts. Publiczne dane ze stron deweloperskich i niezależnych opracowań podają, że model ma około 744B łącznych parametrów przy ~40B aktywnych na token — istotny krok naprzód względem konfiguracji GLM-4.5 ~355B / 32B aktywnych. Takie rzadkie skalowanie pozwala uzyskać bardzo dużą pojemność całkowitą przy zachowaniu obliczeń per token na rozsądnym poziomie.
- DeepSeek Sparse Attention (DSA): Aby zachować zdolność długiego kontekstu bez liniowego wzrostu kosztu wnioskowania, GLM-5 integruje mechanizm rzadkiej uwagi (marka DeepSeek), który utrzymuje ważne dalekozasięgowe zależności w skali, jednocześnie ograniczając koszt uwagi dla ultradługich kontekstów.
Inżynieria agentowa jako fundamentalny cel projektowy
Jedną z głównych cech GLM-5 jest to, że został explicite zaprojektowany pod inżynierię agentową — co oznacza, że model ma służyć nie tylko do jednokrokowych czatów lub podsumowań, ale jako „mózg” wieloetapowych agentów, którzy potrafią planować, wywoływać narzędzia, zarządzać stanem i rozumować w długim kontekście. Z.ai pozycjonuje GLM-5 jako element pętli orkiestracji: rozbijanie złożonych problemów, wywoływanie zewnętrznych narzędzi/API i śledzenie długich zadań na wielu turach.
Dlaczego projektowanie agentowe ma znaczenie
Przepływy agentowe są kluczowe dla automatyzacji w świecie rzeczywistym: zautomatyzowani asystenci badawczy, autonomiczni inżynierowie oprogramowania, orkiestracja operacji i sterowanie symulacjami. Model zbudowany do takiego zastosowania potrzebuje silnego planowania, stabilnego wywoływania narzędzi oraz odporności przy tysiącach tokenów kontekstu.
Ulepszone kodowanie, rozumowanie i zachowanie w długim horyzoncie
GLM-5 akcentuje ulepszone generowanie kodu i rozumowanie. Z.ai deklaruje ukierunkowane poprawy zdolności modelu do pisania, refaktoryzacji i debugowania kodu, a także bardziej spójnego wieloetapowego rozumowania w długich interakcjach. Niezależne relacje z wczesnego dostępu i oceny partnerów wskazują, że model jest zauważalnie silniejszy w zadaniach deweloperskich niż wcześniejsze generacje GLM.
Praktyczne funkcje dla deweloperów
- Większe okna kontekstu umożliwiające pomieszczenie dokumentacji, baz kodu i stanu rozmowy.
- Prymitywy narzędziowe dla bezpiecznego wywoływania narzędzi i obsługi wyników.
- Lepsza wydajność few-shot i chain-of-thought do dekompozycji i wykonywania złożonych zadań.
- Funkcje agentowe i wywoływanie narzędzi: GLM-5 kładzie nacisk na natywne wsparcie dla agentów: wywoływanie funkcji/narzędzi, sesje z utrzymaniem stanu oraz lepsze zarządzanie długimi dialogami i sekwencjami użycia narzędzi. Ułatwia to budowę agentów integrujących wyszukiwanie w sieci, bazy danych lub automatyzację zadań.
Jak GLM-5 wypada w benchmarkach?
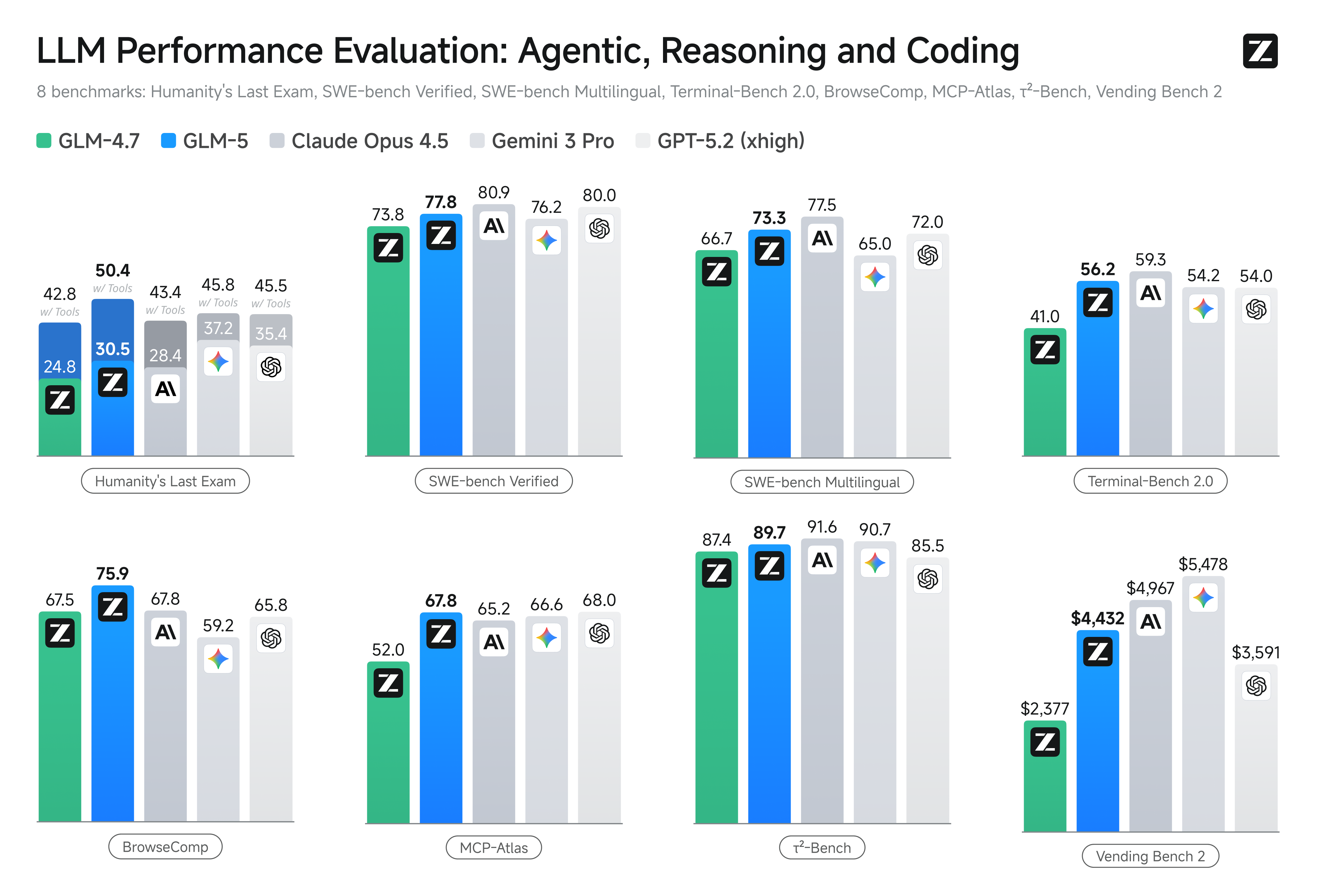
Najważniejsze wyniki w benchmarkach
- Benchmarki kodowania: GLM-5 zbliża się (a w niektórych przypadkach dorównuje) do wydajności mocno zoptymalizowanych modeli proprietarnych, takich jak Anthropic Claude Opus 4.5, w konkretnych zadaniach kodowania. Wyniki zależą od zadania (testy jednostkowe, kodowanie algorytmiczne, użycie API), ale stanowią wyraźną poprawę względem GLM-4.5.
- Testy rozumowania i agentowe: W zestawach oceny wieloetapowego rozumowania i zadań agentowych (np. planowanie wieloturowe, benchmarki dekompozycji zadań) GLM-5 osiągnął wyniki najlepsze w klasie wśród modeli open-source, a w niektórych metrykach przewyższył konkurencyjne modele zamknięte w wybranych zadaniach.
Jak uzyskać dostęp do GLM-5 i go wypróbować?
GLM-5 to piątej generacji duży model językowy od Zhipu AI (Z.ai), zbudowany w oparciu o architekturę Mixture-of-Experts (~745 B łącznie, ~44 B aktywnych) i ukierunkowany na silne rozumowanie, kodowanie oraz przepływy agentowe. Oficjalnie uruchomiony około 12 lutego 2026 r.
Obecnie istnieją dwa główne sposoby uzyskania dostępu:
A) Oficjalny dostęp przez API (Z.ai lub agregatory)
Samo Zhipu AI oferuje API dla swoich modeli, a GLM-5 można wywoływać przez te interfejsy.
Typowe kroki:
- Zarejestruj konto w Z.ai/Open BigModel API.
- Pobierz klucz API z panelu.
- Użyj punktu końcowego w stylu OpenAPI lub REST z nazwą modelu (np.
glm-5).
(Podobnie jak wywołuje się modele GPT od OpenAI). - Ustaw prompt i wyślij żądania HTTP.
👉 Strona cennika Z.ai pokazuje oficjalne ceny tokenów GLM-5, np.:
- ~$1.0 za milion tokenów wejściowych
- ~$3.2 za milion tokenów wyjściowych
B) Zewnętrzne „API wrappers” ——CometAPI
API takie jak CometAPI czy WaveSpeed opakowują wiele modeli AI (OpenAI, Claude, Z.ai itd.) za ujednoliconym interfejsem.
- Z usługami takimi jak CometAPI możesz wywoływać modele GLM, zmieniając jedynie identyfikator modelu.
(CometAPI obecnie wspiera GLM-5/GLM-4.7.) - glm-5 w CometAPI wyceniono na 20% ceny oficjalnej.
| Typ użycia | Cena |
|---|---|
| Tokeny wejściowe | ~$0.8 per 1M tokens |
| Tokeny wyjściowe | ~$2.56 per 1M tokens |
Dlaczego to ważne: Zachowujesz istniejący kod klienta kompatybilny z OpenAI i zmieniasz jedynie bazowy URL/ID modelu.
C) Samodzielny hosting przez Hugging Face / wagi
Istnieją nieoficjalne repozytoria wag GLM-5 (np. wersje nazwane glm-5/glm-5-fp8) widoczne w listach modeli Hugging Face.
Dzięki nim możesz:
- Pobrać wagi modelu.
- Użyć narzędzi takich jak vLLM, SGLang, xLLM lub Transformers, aby serwować lokalnie lub w swojej flocie GPU w chmurze.
Zalety: maksymalna kontrola, brak bieżących kosztów API.
Wady: ogromne wymagania obliczeniowe — prawdopodobnie wiele topowych GPU i pamięci (kilkaset GB), co czyni to niepraktycznym na małych systemach.
Więc — czy GLM-5 się opłaca i czy powinieneś zachować GLM-4.7?
Krótka odpowiedź (podsumowanie dla decydentów)
- Jeśli Twoja praca wymaga solidnego, wieloetapowego zachowania agentowego, produkcyjnego generowania kodu lub automatyzacji na poziomie systemu: GLM-5 warto ocenić natychmiast. Jego architektura, skala i strojenie priorytetyzują właśnie te rezultaty.
- Jeśli potrzebujesz ekonomicznych, wydajnych mikrousług (krótkie czaty, klasyfikacja, lekkie prompty): GLM-4.7 prawdopodobnie pozostaje najbardziej opłacalnym wyborem. GLM-4.7 zachowuje silny zestaw możliwości przy znacząco niższym koszcie per token w wielu ofertach dostawców i jest już sprawdzony bojowo.
Dłuższa odpowiedź (praktyczna rekomendacja)
Przyjmij warstwową strategię modeli: używaj GLM-4.7 do codziennych, wysokowolumenowych interakcji, a GLM-5 rezerwuj dla zadań inżynieryjnych o wysokiej wartości i orkiestracji agentów. Uruchom pilota GLM-5 na niewielkim wycinku produktu, który ćwiczy długi kontekst, integrację narzędzi i poprawność kodu; mierz zarówno zaoszczędzony czas inżynierski, jak i przyrostowy koszt modelu. Z czasem ocenisz, czy wzrost możliwości GLM-5 uzasadnia szerszą migrację.
Z CometAPI możesz przełączać się między GLM-4.7 a GLM-5 w dowolnym momencie.
Rzeczywiste przypadki użycia, w których GLM-5 błyszczy
1. Złożona orkiestracja agentów
Skupienie GLM-5 na wieloetapowym planowaniu i wywoływaniu narzędzi predestynuje go do systemów, które muszą koordynować wyszukiwanie, wywołania API i wykonywanie programów (na przykład: zautomatyzowani asystenci badawczy, iteracyjne generatory kodu lub wieloetapowi agenci obsługi klienta, którzy muszą konsultować bazy danych i zewnętrzne API).
2. Długie prace inżynierskie i rozumowanie na bazie kodu
Gdy potrzebujesz, by model analizował, refaktoryzował lub syntetyzował treści obejmujące wiele plików lub dużą bazę kodu, rozszerzony kontekst GLM-5 i rzadka uwaga są bezpośrednimi atutami — mniej trybów błędów spowodowanych uciętym kontekstem i lepsza spójność na długich odcinkach.
3. Synteza wymagająca dużej wiedzy
Analitycy i zespoły produktowe tworzące złożone raporty — wielosekcyjne opracowania badawcze, podsumowania prawne czy zgłoszenia regulacyjne — mogą skorzystać z ulepszeń modelu w stabilnym wieloetapowym rozumowaniu i ograniczeniu halucynacji w testach raportowanych przez dostawców.
4. Automatyzacja agentowa przepływów pracy
Zespoły budujące automatyzację, która musi orkiestrwać wiele systemów (np. planowanie + ticketing + potoki wdrożeń), mogą używać GLM-5 jako centralnego planisty i wykonawcy, wspartego frameworkami wywoływania narzędzi i warstwami bezpieczeństwa.
Podsumowanie
GLM-5 to ważne wydanie w szybko ewoluującym krajobrazie modeli z czołówki. Nacisk na inżynierię agentową, ulepszone kodowanie i rozumowanie oraz dostępność wag czynią go atrakcyjnym dla zespołów budujących systemy AI z długim horyzontem i obsługą narzędzi. Realne zyski w wybranych zadaniach i obiecujące kompromisy koszt/wydajność — ale kupujący powinni ocenić GLM-5 pod kątem własnych zadań i przeprowadzić kontrolowane benchmarki przed wdrożeniem produkcyjnym.
Deweloperzy mogą uzyskać dostęp do GLM-5 przez CometAPI już teraz. Na początek poznaj możliwości modelu w Playground i zapoznaj się z przewodnikiem API po szczegółowe instrukcje. Przed dostępem upewnij się, że zalogowałeś(-aś) się do CometAPI i uzyskałeś(-aś) klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby ułatwić integrację.
Ready to Go?→ Zarejestruj się do glm-5 już dziś !
Jeśli chcesz poznać więcej porad, przewodników i wiadomości o AI, śledź nas na VK, X i Discord!