

Google DeepMind bugün Gemini 2.5 ailesine önemli genişletmeler duyurdu ve Gemini 2.5 Pro ve Gemini 2.5 Flash'ın kararlı sürümlerini yepyeni Gemini 2.5 Flash‑Lite modelinin önizlemesiyle birlikte duyurdu. Bu güncellemeler, Google'ın çeşitli iş yükleri için maliyet, hız ve performansı dengeleyen bir dizi AI modeli sunma konusundaki sürekli bağlılığını yansıtıyor.
Kararlı Sürümler: Gemini 2.5 Pro ve Flash
Google, 17 Haziran 2025'te Gemini 2.5 Pro ve Gemini 2.5 Flash'ın genel kullanıma sunulduğunu duyurdu. Pro varyantı maksimum muhakeme gücü sunar ve gelişmiş kod üretimi, bilimsel analiz ve büyük ölçekli veri sentezi gibi yüksek karmaşıklıktaki görevler için tasarlanmıştır. Buna karşılık, Gemini 2.5 Flash, düşük gecikme gerektiren günlük kullanımlar için optimize edilmiş orta düzey bir seçenek sunar; sohbet robotları, özetleme ve büyük ölçekte içerik oluşturma için idealdir.
Genel Bakış: Gemini -2.5 Ailesindeki Üç Model
| Model | Durum | Güçlü | İdeal Kullanım Durumları |
|---|---|---|---|
| Gemini 2.5 Flaş‑Lite (Ön izleme) | Önizleme | En hızlı ve en ucuz; çok modlu; kontrol edilebilir akıl yürütme; araç destekli | Sohbet robotları, özetleme, arama gibi yüksek hacimli görevler |
| İkizler 2.5 Flaş | Kararlı | Dengeli: düşük gecikme, iyi muhakeme, çok modlu | Gerçek zamanlı görüşmeler, müşteri desteği |
| İkizler 2.5 Pro | Kararlı | En yetenekli: derin muhakeme, geniş bağlam, çok modlu | Araştırma, karmaşık kodlama, bilimsel görevler |
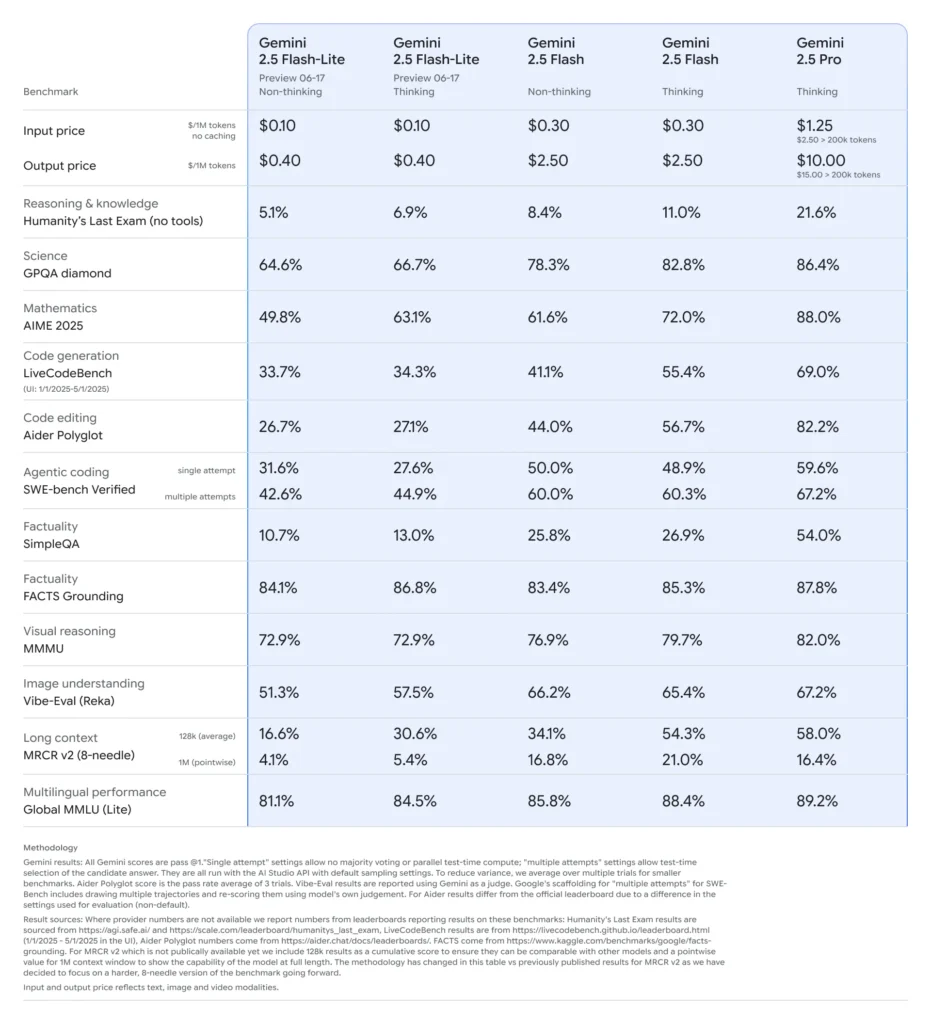
Gemini 2.5 Flash‑Lite: Önizleme Öne Çıkanlar
Ultra düşük gecikme ve maliyet tasarrufu:Çeviri, sınıflandırma ve özetleme gibi yüksek hacimli, gerçek zamanlı uygulamalar için tasarlanmıştır. Hem 2.0 Flash‑Lite hem de tam Flash sürümüne kıyasla daha hızlı çıkarım ve daha düşük çağrı başına maliyet sunar.
Geliştirilmiş temel performans: Kod oluşturma, mantık, matematik, çok modlu akıl yürütme ve bilim alanlarındaki kıyaslamalarda önceki Flash‑Lite modellerinden daha iyi performans gösterir.
Maliyet ve verimlilik: Flash‑Lite fiyatlandırması (önizleme): 0.10 milyon giriş belirteci başına ~$1 ve 0.40 milyon çıkış belirteci başına ~$1—Flash'tan ($0.30/$2.50) ve Pro'dan ($1.25/$10) önemli ölçüde daha ucuz.
Tam Gemini -2.5 yetenekleri:
- Kontrol edilebilir düşünme: Kullanıcılar, derinlik karşılığında hızı feda etmek için "düşünme bütçeleri" (token sınırları) ayarlayabilirler; Flash‑Lite gerektiğinde bunu açabilir.
- Çok Modlu Giriş: Metin, resim, ses ve videoyu (bir saatlik klipler dahil) destekler; grafikleri, kullanıcı arayüzünü, sahneleri ve olay özetlerini ayrıştırma yeteneklerine sahiptir.
- Araç Entegrasyonu: Flash ve Pro'nun yetenekleriyle eşleşen Google Arama, kod yürütme ve milyon belirteçli bağlam penceresini içerir.
Fiyat-Performans Eğrisi Üzerinde Konumlandırma
Google, Flash‑Lite'ın yüksek hızını ve düşük maliyetini şu şekilde konumlandırıyor: Pareto sınırı, yani dünya çapında en uygun maliyetli ve aynı zamanda en yetenekli modeller arasında yer alıyor (). Karşılaştırmalı değerlendirmelerde, Flash‑Lite en iyi değeri temsil eder: akıllı ama uygun fiyatlı.
Flash ve Pro Hakkında
- İkizler 2.5 Flaş: Kararlı, düşük gecikmeli, çok modlu düşünme modeli. Pro'nun altında konumlandırılmış ancak yetenek açısından GPT-4 ile hemen hemen aynı seviyede, üstün hız ve maliyet verimliliğine sahip ().
- İkizler 2.5 Pro: Google'ın en gelişmiş modeli. Saatler süren video/ses, karmaşık kod ve matematik ve büyük bağlamlı akıl yürütmeyi işlemesiyle ünlüdür. Ayrıca, uzun vadeli istikrarlı bir amiral gemisi AI olarak hizmet etmek için seçici "düşünme bütçeleri" ve iyileştirilmiş kod kalitesi sunar.
Dağıtım ve Fiyatlandırma
- Uygunluk: Her üç modele de şu adresten erişilebilir: Google AI Stüdyosu, Google Cloud Vertex AI, Ve Gemini uygulaması .
- Maliyet Yapısı (Vertex AI'nın 16 Haziran 2025'ten itibaren fiyatlandırması):
- başına: $1.25/1M giriş, $10/1M çıkış (200K token'dan daha yüksek)
- flaş: $0.15/1M giriş, $3.50/1M çıkış "düşünme" modunda—ve günlük 1,500 ücretsiz topraklanmış istemi içerir ()
- Flaş-Lite (önizleme): ~$0.10/$0.40 1M token başına
Başlamak
CometAPI, tutarlı bir uç nokta altında, yerleşik API anahtarı yönetimi, kullanım kotaları ve faturalama panolarıyla yüzlerce AI modelini bir araya getiren birleşik bir REST arayüzü sağlar. Birden fazla satıcı URL'sini ve kimlik bilgilerini bir arada yürütmek yerine.
Geliştiriciler erişebilir Gemini 2.5 Flash-Lite (önizleme) API'si içinden Kuyrukluyıldız API'si, listelenen en son modeller makalenin yayınlanma tarihi itibarıyladır. Başlamak için, modelin yeteneklerini keşfedin Oyun Alanı ve danışın API kılavuzu Ayrıntılı talimatlar için. Erişimden önce, lütfen CometAPI'ye giriş yaptığınızdan ve API anahtarını edindiğinizden emin olun. Kuyrukluyıldız API'si Entegrasyonunuza yardımcı olmak için resmi fiyattan çok daha düşük bir fiyat teklif ediyoruz.