

3 marca 2026 r. Google wprowadziło Gemini 3.1 Flash-Lite, najnowszego członka rodziny Gemini 3, zaprojektowanego specjalnie jako silnik o wysokiej przepustowości, niskich opóźnieniach i wysokiej opłacalności kosztowej dla obciążeń deweloperskich i korporacyjnych. Google pozycjonuje Flash-Lite jako „najszybszy i najbardziej opłacalny kosztowo” model w linii Gemini 3: lekką odmianę, której celem jest dostarczanie interakcji strumieniowych, przetwarzania w tle na dużą skalę oraz zadań produkcyjnych o wysokiej częstotliwości (na przykład tłumaczenie, ekstrakcja, generowanie interfejsów UI i masowa klasyfikacja) w znacznie niższej cenie niż odpowiedniki Pro.
Poniżej wyjaśniamy, czym jest Flash-Lite.
Czym jest Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite to członek rodziny Google Gemini 3, który świadomie poświęca część najgłębszych zdolności rozumowania na rzecz szybkości i efektywności kosztowej. Jest natywnie multimodalny w linii Gemini (potrafi przyjmować tekst, obrazy i inne modalności jako wejście), lecz został dostrojony i wdrożony z myślą o maksymalnej przepustowości mierzonej tokenami na sekundę oraz znacząco niższym rozliczaniu per token dla obciążeń wymagających szybkiej, powtarzalnej inferencji zamiast maksymalnej głębokości kognitywnej. Model jest opisywany jako wywiedziony z architektury 3.1 Pro, ale zoptymalizowany pod kątem przepustowości, opóźnień i kosztów.
Kluczowe kompromisy projektowe
Oznaczenie „Lite” sygnalizuje inżynieryjny akcent modelu:
- Przepustowość ponad ciężkie rozumowanie: Flash-Lite celowo redukuje obliczenia na token, aby zapewnić szybszy Time-to-First-Token (TTFT) i stałe tempo generowania wyjścia. Dzięki temu idealnie nadaje się do potoków, w których każde żądanie musi być obsłużone szybko i na skalę (np. filtry bezpieczeństwa, asystenci czasu rzeczywistego, generowanie na dużą skalę).
- Efektywność kosztowa przy dużych wolumenach: Obniżając obliczenia per token, model może być oferowany w niższych cenach za milion tokenów, co redukuje koszt krańcowy w aplikacjach wielkoskalowych (np. miliony do miliardów tokenów miesięcznie). Cennik w preview Google pokazuje istotną różnicę względem poziomu Pro.
- Jakość dostrojona do pragmatycznych zadań: Według wczesnych podsumowań wyników, Flash-Lite utrzymuje mocne rezultaty w standardowej klasyfikacji, zadaniach wielojęzycznych i wielu zadaniach multimodalnych, ale nie jest pozycjonowany, by pokonywać Pro w najbardziej złożonych benchmarkach wieloetapowego rozumowania czy generowania kodu, gdzie kluczowa jest głębia.
Takie obciążenia wymagają niezawodnych wyników i wysokiej przepustowości, ale nie zawsze potrzebują złożonych, wieloetapowych zdolności rozumowania modeli flagowych.
Kluczowe funkcje Gemini 3.1 Flash-Lite
1. Niska latencja i szybki czas do pierwszego tokena
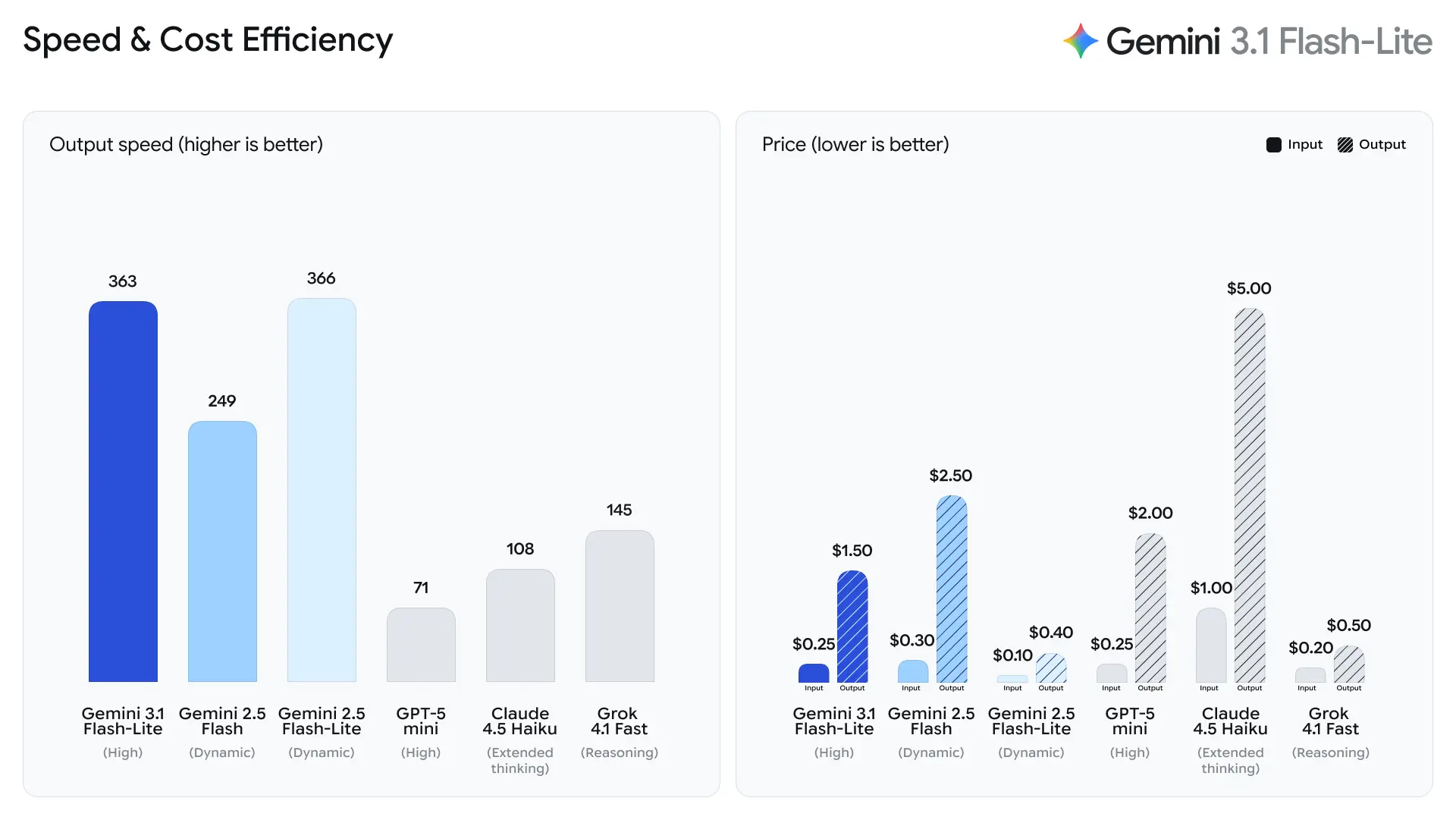
Google podkreśla time-to-first-answer token jako główną metrykę dla Flash-Lite. Firma raportuje ~2.5× szybszy czas do pierwszego tokena w porównaniu z Gemini 2.5 Flash oraz do 45% szybsze generowanie wyjścia — usprawnienia, które bezpośrednio wpływają na postrzeganą responsywność przez użytkowników końcowych i koszty przepustowości po stronie zaplecza. Te zyski sprawiają, że Flash-Lite świetnie sprawdza się w funkcjach interaktywnych (np. chatboty osadzone w aplikacjach) i potokach o wysokim QPS, gdzie liczą się mikrosekundy.
To usprawnienie znacząco wzmacnia aplikacje czasu rzeczywistego, takie jak:
- konwersacyjne AI
- asystenci wyszukiwania zasilani AI
- interaktywne chatboty
- usługi tłumaczeń na żywo
Niższa latencja poprawia doświadczenie użytkownika, skracając czas oczekiwania i umożliwiając bardziej płynne interakcje.
2. Kosztowo efektywne ceny tokenów
Koszty inferencji AI są często liczone per token, więc wycena jest kluczowa przy wdrożeniach na dużą skalę.
Gemini 3.1 Flash-Lite wprowadza wysoce konkurencyjną strukturę cen:
| Typ tokena | Cena |
|---|---|
| Tokeny wejściowe | $0.25 za 1M tokenów |
| Tokeny wyjściowe | $1.50 za 1M tokenów |
To obniżka w porównaniu z wcześniejszymi modelami Flash, dzięki czemu model jest atrakcyjny dla organizacji obsługujących duże obciążenia.
Dla porównania:
| Model | Cena wejściowa | Cena wyjściowa |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Ta strategia cenowa pozwala deweloperom uruchamiać AI na skalę bez drastycznego zwiększania kosztów operacyjnych.
Jeśli szukasz jeszcze lepszej ceny, to Gemini Flash-Lite oferuje 20% zniżki na CometAPI.
3. „Thinking levels” (sterowalna głębokość inferencji)
Gemini 3.1 Flash-Lite zawiera funkcję „thinking levels” — konfigurowalny przez dewelopera parametr, który instruuje model, by preferował szybsze, płytsze przetwarzanie w zadaniach trywialnych oraz głębsze rozumowanie w zadaniach trudniejszych. Ma to praktyczne znaczenie, ponieważ umożliwia dynamiczne kompromisy koszt/latencja dla każdego żądania bez konieczności przełączania modeli.
Deweloperzy mogą konfigurować głębokość rozumowania modelu tak, by odpowiadała złożoności zadania. Thinking levels: obsługuje cztery poziomy: Minimal, Low, Medium oraz High.
To dynamiczne podejście pozwala aplikacjom optymalizować zużycie zasobów, zachowując jakość tam, gdzie ma to znaczenie. Praktyczna strategia wygląda mniej więcej tak:
- Minimal/Low: Odpowiednie dla zadań o wysokiej współbieżności, ale logicznie prostych, takich jak tłumaczenie, klasyfikacja i analiza sentymentu, z priorytetem maksymalnej szybkości i minimalnego kosztu.
- Medium: Odpowiednie dla większości zadań produkcyjnych, łącząc jakość i efektywność.
- High: Odpowiednie dla zadań wymagających głębokiego rozumowania, takich jak generowanie interfejsów użytkownika, tworzenie symulacji i wykonywanie złożonych instrukcji.
4. Zdolność multimodalna przy lekkim śladzie zasobowym
Choć Flash-Lite jest zoptymalizowany pod kątem szybkości i kosztu, zachowuje multimodalne fundamenty linii Gemini 3: potrafi przyjmować obrazy jako wejście do klasyfikacji lub lekkiego rozumowania multimodalnego, gdy wymaga tego przypadek użycia — jednak należy oczekiwać, że ekonomiczny projekt będzie preferował krótsze, ograniczone operacje multimodalne zamiast bardzo dużych przepływów pracy z przewagą obrazów. Podobnie jak inne modele Gemini, Gemini 3.1 Flash-Lite obsługuje wejścia multimodalne, umożliwiając deweloperom przetwarzanie różnych typów danych.
Obsługiwane wejścia obejmują:
- Tekst
- Obrazy
- Wideo
- Audio
- PDF-y
Zdolność modelu do analizy wielu typów informacji umożliwia nowe przypadki użycia, takie jak:
- zautomatyzowane przetwarzanie dokumentów
- ekstrakcja danych wizualnych
- podsumowywanie multimediów
Wcześniejsze modele Gemini również wykazywały silne zdolności rozumowania multimodalnego w różnych benchmarkach wizualnych i wiedzy.
Wyniki wydajności — konkretne liczby i ich znaczenie
Ogłoszenie Google i dokumentacja produktu przedstawiają kilka punktów danych z benchmarków, które mają pomóc kupującym zrozumieć pozycję Flash-Lite w ekosystemie.
Metryki szybkości istotne dla deweloperów
- 2.5× szybszy czas do pierwszego tokena względem Gemini 2.5 Flash (wewnętrzne porównanie podane przez Google).
- 45% szybsze generowanie wyjścia względem Gemini 2.5 Flash.
To metryki inżynierii wydajności, a nie metryki jakości ocenianej przez ludzi; odzwierciedlają ulepszenia w mikroarchitekturze czasu wykonania, batchowaniu i optymalizacjach stosu inferencji, które redukują latencję przy krótkich odpowiedziach. Szybsze czasy do pierwszego tokena zmniejszają postrzegane opóźnienie w aplikacjach interaktywnych i zwiększają ogólną przepustowość na serwer, co może obniżyć całkowite koszty obliczeń przy tym samym QPS.
Tokeny na sekundę (t/s) i przepustowość
Według danych testowych Artificial Analysis, 3.1 Flash-Lite osiągnął prędkość generowania 388.8 tokenów na sekundę (mediana dla modeli w tym samym przedziale cenowym to jedynie 96.7 tokena/sek.). Ta szybkość jest najwyższej klasy wśród modeli w swojej kategorii.
Jednak Artificial Analysis zwróciło też uwagę na problem: latencja pierwszego tokena (TTFT) w 3.1 Flash-Lite wynosi 5.18 sekundy, co jest relatywnie wysoką wartością dla modeli inferencyjnych w tym samym przedziale cenowym (mediana to 1.82 sekundy). Dodatkowo model wygenerował 53 miliony tokenów w trakcie ewaluacji, co jest stosunkowo wysokie względem średniej wynoszącej 20 milionów. Oznacza to, że jeśli Twój scenariusz jest bardzo wrażliwy na latencję pierwszego tokena lub ma rygorystyczne wymagania co do zwięzłości wyjścia, możesz potrzebować zoptymalizować poziom myślenia i prompty.
Wyniki benchmarków dla rozumowania i faktualności
Google dołączyło porównania między modelami, pokazujące, że Gemini 3.1 Flash-Lite osiąga dobre wyniki względem konkurentów i wcześniejszych wariantów Gemini w zagregowanych zadaniach rozumowania/faktualności:
- Arena.ai Elo: Gemini 3.1 Flash-Lite rzekomo osiągnął Elo 1432 w rankingu Arena — złożonej klasyfikacji head-to-head pokazującej konkurencyjną wydajność w bezpośrednich porównaniach.
- GPQA Diamond: 86.9% (miara odporności na pytania/odpowiedzi).
- MMMU Pro: 76.8% (wielomodalna/wielozadaniowa metryka używana wewnętrznie/zewnętrznie przez niektóre laboratoria).
- LiveCodeBench (umiejętności kodowania): 72.0%
- CharXiv Reasoning (rozumowanie graficzne): 73.2%
- Video-MMMU (zrozumienie wideo): 84.8%
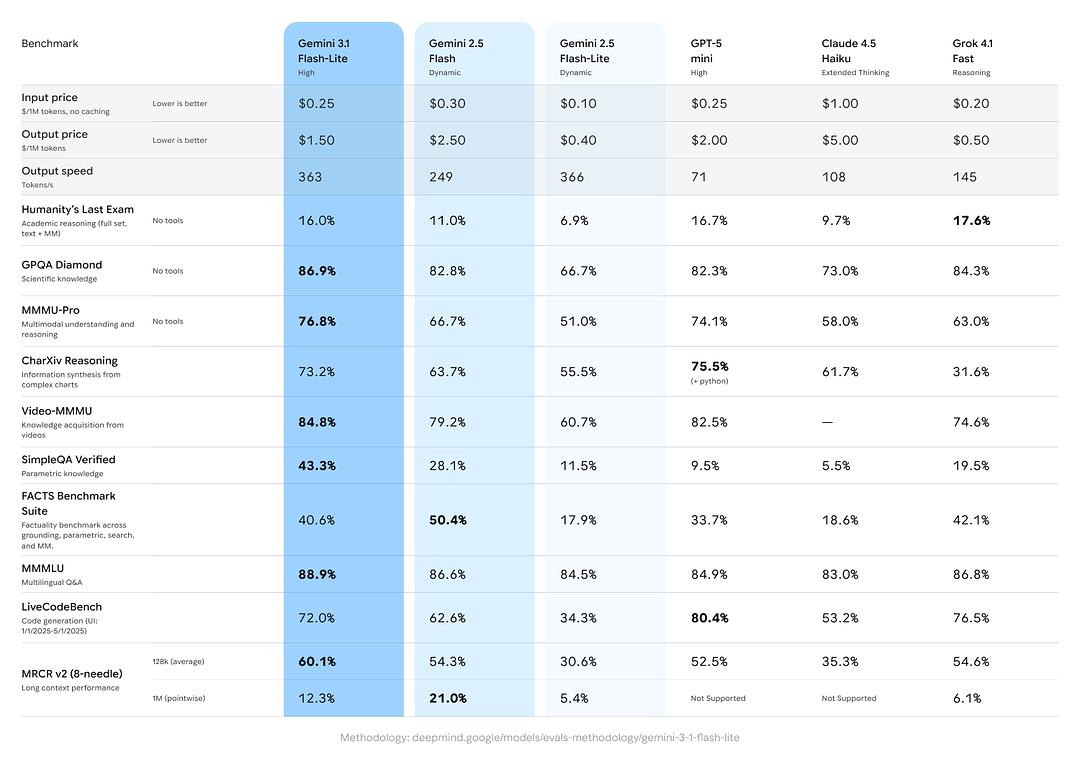
Gemini 3.1 Flash-Lite przewyższa starszy Gemini 2.5 Flash w kilku z tych metryk, zapewniając jednocześnie znacznie lepszą szybkość/koszt.
Zastosowania odpowiednie dla Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite jest projektowany z myślą o jasno określonych, praktycznych obciążeniach, w których decydują wysoka przepustowość i niższy koszt per token:
Agenci konwersacyjni o wysokiej częstotliwości i interfejsy strumieniowe
Chatboty czasu rzeczywistego, strumienie transkrypcji + tłumaczeń oraz współpracujące interfejsy, które wyświetlają częściowe odpowiedzi podczas generowania przez model, korzystają z wyjścia strumieniowego Flash-Lite i niskiego czasu do pierwszego tokena.
Przetwarzanie danych w trybie wsadowym (RAG, potoki transformacji)
Masowe przetwarzanie dokumentów: ekstrakcja encji, tagowanie metadanych, klasyfikacja i tłumaczenia wykonywane na milionach dokumentów — Gemini 3.1 Flash-Lite obniża koszt inferencji, zapewniając akceptowalną dokładność dla wyników szablonowych lub opartych na regułach.
Obliczenia brzegowe lub w tle
Obciążenia, które nieprzerwanie przetwarzają napływającą telemetrię lub niestrukturalne dane (np. potoki klasyfikacji moderacji treści, automatyczne generowanie raportów), dobrze pasują do tego modelu, ponieważ Gemini 3.1 Flash-Lite minimalizuje koszt jednostkowy.
Narzędzia deweloperskie i wsadowe uzupełnianie kodu
W funkcjach takich jak szkielety wieloplikowe, lintowanie kodu na dużą skalę i generowanie szablonów, przewagi szybkości Gemini 3.1 Flash-Lite redukują opóźnienia i koszt w narzędziach deweloperskich, gdzie absolutnie maksymalna głębia rozumowania nie jest wymagana.
Porównanie Gemini 3.1 Flash-Lite z innymi modelami Gemini i konkurencją
W ramach rodziny Gemini
- Gemini 3.1 Pro: najwyższe możliwości w złożonym rozumowaniu i wieloetapowym planowaniu; znacząco droższy i wolniejszy per token, ale lepszy do głębokich, niuansowych zadań.
- Gemini 3.1 Flash (non-Lite): celuje w kompromis między surową przepustowością a możliwościami — Flash-Lite idzie dalej w dół stosu obliczeniowego, optymalizując pod przepustowość.
W porównaniu z konkurencyjnymi „szybkimi” modelami
Gemini 3.1 Flash-Lite dorównuje lub przewyższa kilka szybkich/mini modeli w wielu metrykach przepustowości i jakości — jednak niezależni analitycy ostrzegają, że bezpośrednie porównania są wrażliwe na metodologię ewaluacji i dobór zbiorów danych. Należy oczekiwać, że Gemini 3.1 Flash-Lite będzie wysoce konkurencyjny pod względem przepustowości i kosztu, pozostając w okolicach środka stawki w najwyższych metrykach rozumowania.
Wnioski — miejsce Flash-Lite w stosie AI
Gemini 3.1 Flash-Lite to celowo zaprojektowana oferta: efektywny, skupiony na przepustowości członek rodziny Gemini 3, który pozwala zespołom wymienić część obliczeń na przykład na dramatyczną poprawę opóźnień i kosztów. Dla firm i deweloperów budujących potoki o dużej skali — tłumaczenia, przetwarzanie wsadowe, interfejsy strumieniowe i zadania agentyczne o umiarkowanej złożoności — Flash-Lite stanowi rozsądny silnik bazowy. Dla organizacji wymagających absolutnie najwyższej wierności rozumowania odpowiednim wyborem pozostają modele Pro.
Jeśli Twoje obciążenie polega głównie na wielu krótkich, powtarzalnych inferencjach lub potrzebujesz szybkiego wyjścia strumieniowego w dużej skali, warto pilotażowo sprawdzić Flash-Lite. Jeśli obciążenie opiera się na głębokim rozumowaniu wieloetapowym, zaplanuj podejście hybrydowe: kieruj ruch przepustowości do Flash-Lite, a wartościowe, złożone zapytania eskaluj do modeli Pro.
Deweloperzy mogą uzyskać dostęp do Gemini 3.1 Flash Lite za pośrednictwem CometAPI już teraz. Aby zacząć, poznaj możliwości modelu w Playground i zapoznaj się z API guide po szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś(-aś) się do CometAPI i otrzymałeś(-aś) klucz API. CometAPI oferuje cenę znacznie niższą od oficjalnej, aby ułatwić integrację.
Gotowy(-a) do startu?→ Zarejestruj się do Gemini 3.1 Flash lite już dziś !
Jeśli chcesz poznać więcej wskazówek, poradników i nowości o AI, obserwuj nas na VK, X i Discord!