API audio GPT-4o: Zjednoczony /chat/completions rozszerzenie punktu końcowego, które akceptuje zakodowane w Opus dane audio (i tekstowe) i zwraca syntezowaną mowę lub transkrypty z konfigurowalnymi parametrami (model=gpt-4o-audio-preview-<date>, speed, temperature) do interakcji głosowych wsadowych i strumieniowych.
Podstawowe informacje o GPT-4o Audio
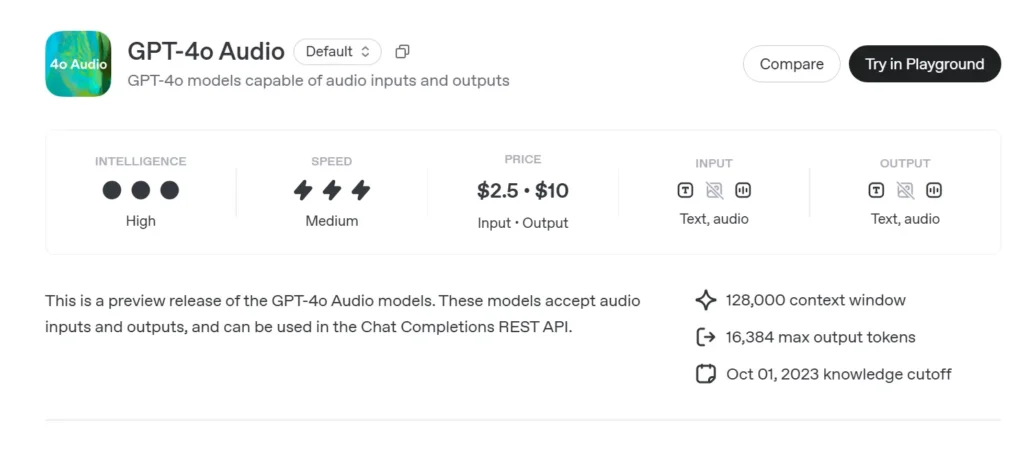
Podgląd dźwięku GPT-4o (gpt-4o-audio-preview-2025-06-03) jest najnowszą wersją OpenAI model dużego języka zorientowany na mowę udostępniane poprzez standard Interfejs API uzupełniania czatów zamiast kanału Realtime o ultraniskim opóźnieniu. Zbudowany na tym samym fundamencie „omni” co GPT-4o, ten wariant specjalizuje się w wejście i wyjście mowy o wysokiej wierności do rozmów turowych, tworzenia treści, narzędzi ułatwień dostępu i przepływów pracy agentów, które nie wymagają milisekundowego czasu. Dziedziczy wszystkie mocne strony modeli GPT-4-class w zakresie rozumowania tekstowego, dodając jednocześnie kompleksowa transmisja mowy (S2S) rurociągi, deterministyczne wywoływanie funkcjii nowe speed parametr do sterowania prędkością głosu.
Zestaw podstawowych funkcji audio GPT-4o
• Zunifikowane przetwarzanie mowy na mowę – Dźwięk jest bezpośrednio przekształcany w semantycznie bogate tokeny, na podstawie których przeprowadzane są obliczenia i resyntezowane bez korzystania z zewnętrznych usług STT/TTS, co daje spójna barwa głosu, prozodia i zachowanie kontekstu.
• Ulepszone przestrzeganie instrukcji – Strojenie z czerwca 2025 r. przynosi +19 pp zaliczenie na 1 miejscu w zakresie zadań wymagających poleceń głosowych w porównaniu z wersją bazową GPT-2024o z maja 4 r., co zmniejszyło halucynacje w takich obszarach, jak obsługa klienta i tworzenie treści.
• Wywołanie stabilnego narzędzia – Model generuje ustrukturyzowany JSON który jest zgodny ze schematem wywoływania funkcji OpenAI, umożliwiając wyzwalanie interfejsów API zaplecza (wyszukiwanie, rezerwacje, płatności) >95% trafności argumentów.
• speed Parametr (0.25–4×) – Programiści mogą modulować odtwarzanie mowy w celu nauki w wolnym tempie, normalnej narracji lub szybkich trybów „słyszalnego przeglądania”, bez resynteza tekstu zewnętrznie.
• Zmiana kierunku z uwzględnieniem przerw – Choć wersja zapoznawcza nie jest tak oparta na opóźnieniach jak wariant Realtime, obsługuje częściowe przesyłanie strumieniowe:tokeny są emitowane natychmiast po ich obliczeniu, co pozwala użytkownikom na wcześniejsze przerwanie obliczeń, jeśli zajdzie taka potrzeba.
Architektura techniczna GPT-4o
• Transformator jednopoziomowy – Podobnie jak wszystkie pochodne GPT-4o, podgląd audio wykorzystuje zunifikowany koder-dekoder gdzie tekst i tokeny akustyczne przechodzą przez identyczne bloki uwagi, promując uziemienie międzymodalne.
• Hierarchiczna tokenizacja audio – Surowe 16 kHz PCM → łatki log-mel → grube kody akustyczne → tokeny semantyczne. Ta wielostopniowa kompresja osiąga 40–50-krotna redukcja przepustowości zachowując niuanse, umożliwiając tworzenie wielominutowych klipów w każdym oknie kontekstowym.
• Kwantowane wagi NF4 – Wnioskowanie jest podawane w 4-bitowy normalny float precyzja, zmniejszenie pamięci GPU o połowę w porównaniu do fp16 i utrzymanie 70+ strumieniowych plików RTF (w czasie rzeczywistym) na węzłach A100-80 GB.
• Uwaga strumieniowa i buforowanie KV – Osadzone obrotowe okna przesuwne utrzymują kontekst przez ~30 s mowy, jednocześnie zachowując O(L) wykorzystanie pamięci, idealne dla redaktorów podcastów lub narzędzi wspomagających czytanie.
Wersjonowanie i nazewnictwo — Podgląd utworu z kompilacjami oznaczonymi datą
| identyfikator | Kanał | Cel | Data wydania | Stabilność |
|---|---|---|---|---|
| gpt-4o-audio-podgląd-2025-06-03 | Interfejs API uzupełniania czatów | Interakcje dźwiękowe w turach, zadania agentów | Czerwiec 03 2025 | Podgląd (zachęcamy do wyrażania opinii) |
Kluczowe elementy nazwy:
- gpt-4o – Rodzina omni-multimodalna.
- audio – Zoptymalizowany pod kątem zastosowań mowy.
- zapowiedź – Kontrakt API może ewoluować, ale nie jest jeszcze powszechnie dostępny.
- 2025-06-03 – Podsumowanie szkolenia i wdrożenia w celu zapewnienia odtwarzalności.
Jak wywołać GPT-4o Audio API API z CometAPI
GPT-4o Audio API Cennik API w CometAPI:
- Żetony wejściowe: 2 USD / mln żetonów
- Tokeny wyjściowe: 8 USD / mln tokenów
Wymagane kroki
- Zaloguj się do pl.com. Jeśli jeszcze nie jesteś naszym użytkownikiem, zarejestruj się najpierw
- Pobierz klucz API uwierzytelniania dostępu do interfejsu. Kliknij „Dodaj token” przy tokenie API w centrum osobistym, pobierz klucz tokena: sk-xxxxx i prześlij.
- Uzyskaj adres URL tej witryny: https://api.cometapi.com/
Metody użytkowania
- Wybierz "
gpt-4o-audio-preview-2025-06-03” punkt końcowy do wysłania żądania i ustawienia treści żądania. Metoda żądania i treść żądania są pobierane z naszej dokumentacji API witryny. Nasza witryna udostępnia również test Apifox dla Twojej wygody. - Zastępować za pomocą aktualnego klucza CometAPI ze swojego konta.
- Wpisz swoje pytanie lub prośbę w polu treści — model odpowie właśnie na tę wiadomość.
- . Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź.
Informacje na temat dostępu do modelu w interfejsie API Comet można znaleźć tutaj Dokumentacja API.
Informacje o cenie modelu w interfejsie API Comet można znaleźć tutaj https://api.cometapi.com/pricing.
Przepływ pracy API — Uzupełnienia czatu z częściami audio i haczykami funkcyjnymi
- Format wejściowy -
audio/*MIME lubbase64Fragmenty WAV osadzone wmessages[].content. - Opcje wyjściowe -
•mode: "text"→ czysty tekst do napisów.
•mode: "audio"→ zwraca Streaming Ładunek Opus lub µ-law ze znacznikami czasu. - Wywołanie funkcji - Dodaj
functions:schemat; model emitujerole: "function"z argumentami JSON; programista wykonuje wywołanie narzędzia i opcjonalnie przesyła wynik z powrotem. - Rate Control – Zestaw
voice.speed=1.25aby przyspieszyć odtwarzanie; bezpieczny zakres 0.25–4.0. - Limity tokenów/audio – 128 k kontekstu (~4 min mowy) przy uruchomieniu; 4096 tokenów audio / 8192 tokenów tekstowych w zależności od tego, co nastąpi pierwsze.
Przykładowy kod i integracja API
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Najważniejsze:
- model:
"gpt-4o-audio-preview-2025-06-03" - audio wprowadź klucz użytkownik wiadomość o wysłaniu strumienia binarnego
- prędkość: : Sterowanie stawka za głos między wolnym (0.5) a szybkim (2.0)
- temperatura:Saldo kreatywność vs konsystencja
Wskaźniki techniczne — Opóźnienie, jakość, dokładność
| metryczny | Podgląd dźwięku | GPT-4o (tylko tekst) | Delta |
|---|---|---|---|
| Opóźnienie pierwszego tokena (jednorazowe) | 1.2 s Średnia | 0.35 s | +0.85 sek. |
| MOS (naturalność mowy, 5 pkt.) | 4.43 | - | - |
| Zgodność z instrukcją (głos) | 92% | 73% | +19 s |
| Dokładność wywołania funkcji Arg | 95.8% | 87% | +8.8 s |
| Współczynnik błędów słów (niejawny STT) | 5.2% | n / a | - |
| Pamięć GPU / strumień (A100-80GB) | 7.1 GB | 14 GB (fp16) | −49% |
Testy porównawcze przeprowadzone za pomocą strumieniowego przesyłania ukończeń czatów, wielkość partii = 1.
Zobacz także Interfejs API w czasie rzeczywistym GPT-4o