

OpenAI opublikowało podgląd badań gpt-oss-safeguard, rodzina modeli wnioskowania o otwartej wadze zaprojektowana tak, aby umożliwić programistom egzekwowanie własne polityki bezpieczeństwa w czasie wnioskowania. Zamiast dostarczać stały klasyfikator lub moduł moderacji typu „czarna skrzynka”, nowe modele są precyzyjnie dostrojone powód z polityki dostarczonej przez dewelopera, emitują łańcuch myślowy (CoT) wyjaśniający ich rozumowanie i generują ustrukturyzowane wyniki klasyfikacji. Zapowiedziany jako wstęp do badań, model gpt-oss-safeguard jest prezentowany jako para modeli rozumowania —gpt-oss-safeguard-120b oraz gpt-oss-safeguard-20b—dostrojony na podstawie rodziny gpt-oss i specjalnie zaprojektowany do wykonywania zadań klasyfikacji bezpieczeństwa i egzekwowania zasad podczas wnioskowania.
Czym jest gpt-oss-safeguard?
gpt-oss-safeguard to para modeli wnioskowania o otwartej wadze i wyłącznie tekstowych, które zostały po przeszkoleniu z rodziny gpt-oss zinterpretować politykę napisaną w języku naturalnym i oznaczyć tekst zgodnie z tą politykąCechą charakterystyczną tej polityki jest to, że podane w momencie wnioskowania (polityka jako dane wejściowe), a nie wbudowane w statyczne wagi klasyfikatorów. Modele te są przeznaczone głównie do zadań klasyfikacji bezpieczeństwa, np. moderacji wielu polityk, klasyfikacji treści w różnych systemach regulacyjnych lub kontroli zgodności z politykami.
Dlaczego ma to znaczenie
Tradycyjne systemy moderacji zazwyczaj opierają się na (a) stałych zestawach reguł przyporządkowanych klasyfikatorom trenowanym na przykładach z etykietami lub (b) heurystykach/wyrażeniach regularnych do wykrywania słów kluczowych. gpt-oss-safeguard próbuje zmienić paradygmat: zamiast ponownie trenować klasyfikatory przy każdej zmianie polityki, użytkownik dostarcza tekst polityki (na przykład regulamin akceptowalnego użytkowania w firmie, regulamin platformy lub wytyczne regulatora), a model analizuje, czy dany element treści narusza tę politykę. Zapewnia to elastyczność (zmiany polityki bez ponownego trenowania) i interpretowalność (model generuje swój ciąg rozumowania).
Oto jej główna filozofia — „Zastąpienie zapamiętywania rozumowaniem, a zgadywania wyjaśnianiem”.
Oznacza to nowy etap w zabezpieczaniu treści, przejście od „pasywnego uczenia się reguł” do „aktywnego rozumienia reguł”.
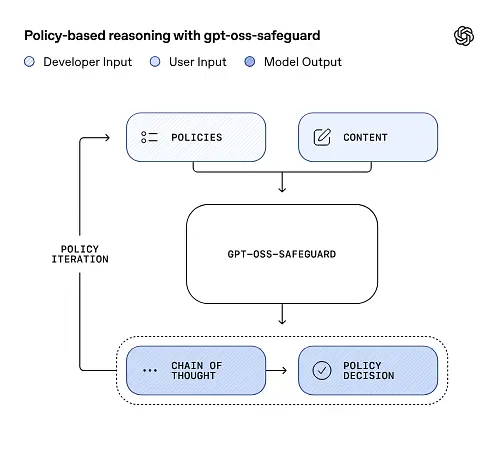
gpt-oss-safeguard może bezpośrednio odczytywać zasady bezpieczeństwa zdefiniowane przez programistów i stosować je przy podejmowaniu decyzji w trakcie wnioskowania.
Jak działa gpt-oss-safeguard?
Rozumowanie oparte na polityce jako danych wejściowych
W momencie wnioskowania należy podać dwie rzeczy: tekst polityki i treść kandydata do oznaczenia. Model traktuje politykę jako podstawową instrukcję, a następnie przeprowadza analizę krok po kroku, aby określić, czy treść jest dozwolona, niedozwolona, czy wymaga dodatkowych kroków moderacji. W procesie wnioskowania model:
- generuje ustrukturyzowany wynik obejmujący wniosek (etykieta, kategoria, pewność) oraz czytelny dla człowieka ślad rozumowania wyjaśniający, dlaczego wyciągnięto taki wniosek.
- pobiera politykę i treść, która ma zostać sklasyfikowana,
- wewnętrznie rozumuje poprzez klauzule polityki, wykorzystując kroki przypominające ciąg myśli, i
Na przykład:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Odpowie:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Łańcuch myśli (CoT) i ustrukturyzowane wyniki
gpt-oss-safeguard może generować pełny ślad CoT w ramach każdego wnioskowania. CoT ma być weryfikowalny — zespoły ds. zgodności mogą odczytać, dlaczego model doszedł do wniosku, a inżynierowie mogą wykorzystać ślad do diagnozowania niejednoznaczności zasad lub trybów awarii modelu. Model obsługuje również ustrukturyzowane wyjścia— na przykład plik JSON zawierający werdykt, sekcje dotyczące naruszeń zasad, wynik ważności i sugerowane działania naprawcze — co ułatwia integrację z procesami moderacji.
Regulowane poziomy „wysiłku rozumowania”
Aby zrównoważyć opóźnienie, koszt i dokładność, modele obsługują konfigurowalny wysiłek wnioskowania: niski / średni / wysokiWiększy nakład pracy zwiększa głębię łańcucha myślowego i generalnie prowadzi do bardziej solidnych, ale wolniejszych i bardziej kosztownych wniosków. Pozwala to programistom na selekcję obciążeń – stosuj niski nakład pracy dla rutynowych treści, a wysoki dla przypadków brzegowych lub treści wysokiego ryzyka.
Jaka jest struktura modelu i jakie wersje istnieją?
Rodzina modelowa i linia
gpt-oss-safeguard są po treningu warianty wcześniejszych wersji OpenAI gpt-oss Modele otwarte. Rodzina zabezpieczeń obejmuje obecnie dwa dostępne rozmiary:
- gpt-oss-safeguard-120b — model składający się ze 120 miliardów parametrów, przeznaczony do zadań rozumowania o wysokiej dokładności, który nadal działa na pojedynczym procesorze graficznym o pojemności 80 GB w zoptymalizowanych czasach wykonania.
- gpt-oss-safeguard-20b — model składający się z 20 miliardów parametrów, zoptymalizowany pod kątem wnioskowania o niższych kosztach oraz środowisk brzegowych i lokalnych (w niektórych konfiguracjach może działać na urządzeniach VRAM o pojemności 16 GB).
Notatki dotyczące architektury i charakterystyki środowiska wykonawczego (czego się spodziewać)
- Aktywne parametry na token: Podstawowa architektura gpt-oss wykorzystuje techniki, które redukują liczbę parametrów aktywowanych na token (mieszanka gęstej i rzadkiej uwagi / stylu mieszanego z eksperckimi w macierzystym gpt-oss).
- w praktyce klasa 120B pasuje do pojedynczych dużych akceleratorów, a klasa 20B jest zaprojektowana do działania w konfiguracjach 16 GB VRAM w zoptymalizowanym czasie wykonania.
Modele zabezpieczające były nie przeszkolony w zakresie dodatkowych danych biologicznych lub dotyczących cyberbezpieczeństwa, a analizy najgorszych scenariuszy niewłaściwego użycia przeprowadzone dla wydania gpt-oss w przybliżeniu odnoszą się do wariantów zabezpieczających. Modele te służą do klasyfikacji, a nie generowania treści dla użytkowników końcowych.
Jakie są cele gpt-oss-safeguard
Gole
- Elastyczność polityki: pozwól programistom definiować dowolne zasady w języku naturalnym i pozwól modelowi stosować je bez konieczności zbierania niestandardowych etykiet.
- Wyjaśnienie: ujawnić rozumowanie, aby decyzje mogły być weryfikowane, a polityka powtarzana.
- Dostępność: zapewnić alternatywę o otwartym charakterze, dzięki której organizacje mogą lokalnie przeprowadzać analizę bezpieczeństwa i sprawdzać wewnętrzne elementy modelu.
Porównanie z klasycznymi klasyfikatorami
Zalety kontra tradycyjne klasyfikatory
- Brak przekwalifikowania w związku ze zmianami polityki: Jeśli polityka moderacji ulegnie zmianie, zaktualizuj dokument polityki, zamiast zbierać etykiety i ponownie szkolić klasyfikator.
- Bogatsze rozumowanie: Wyniki CoT mogą ujawnić subtelne interakcje między politykami i dostarczyć uzasadnienia narracyjnego przydatnego dla recenzentów.
- Możliwość dostosowania: Pojedynczy model może stosować wiele różnych zasad jednocześnie podczas wnioskowania.
Wady w porównaniu z tradycyjnymi klasyfikatorami
- Maksymalne limity wydajności dla niektórych zadań: W ocenie OpenAI wskazano, że wysokiej jakości klasyfikatory trenowane na dziesiątkach tysięcy oznaczonych przykładów mogą przewyższyć gpt-oss-safeguard W przypadku specjalistycznych zadań klasyfikacyjnych. Gdy celem jest dokładność surowej klasyfikacji i dane są oznaczone, dedykowany klasyfikator przeszkolony na tym rozkładzie może być lepszym rozwiązaniem.
- Opóźnienie i koszt: Wnioskowanie z wykorzystaniem CoT jest obliczeniowo intensywne i wolniejsze niż w przypadku lekkiego klasyfikatora. Może to sprawić, że oparte wyłącznie na zabezpieczeniach procesy będą kosztowne na dużą skalę.
Krótko mówiąc: gpt-oss-safeguard najlepiej stosować tam, gdzie zwinność polityki i możliwość audytu są priorytetami lub gdy oznaczonych danych jest niewiele — i jako uzupełniający komponent w hybrydowych procesach, niekoniecznie jako natychmiastowy zamiennik klasyfikatora zoptymalizowanego pod kątem skali.
Jak gpt-oss-safeguard wypadł w ocenach OpenAI?
OpenAI opublikowało wyniki bazowe w 10-stronicowym raporcie technicznym podsumowującym ewaluacje wewnętrzne i zewnętrzne. Najważniejsze wnioski (wybrane wskaźniki nośności):
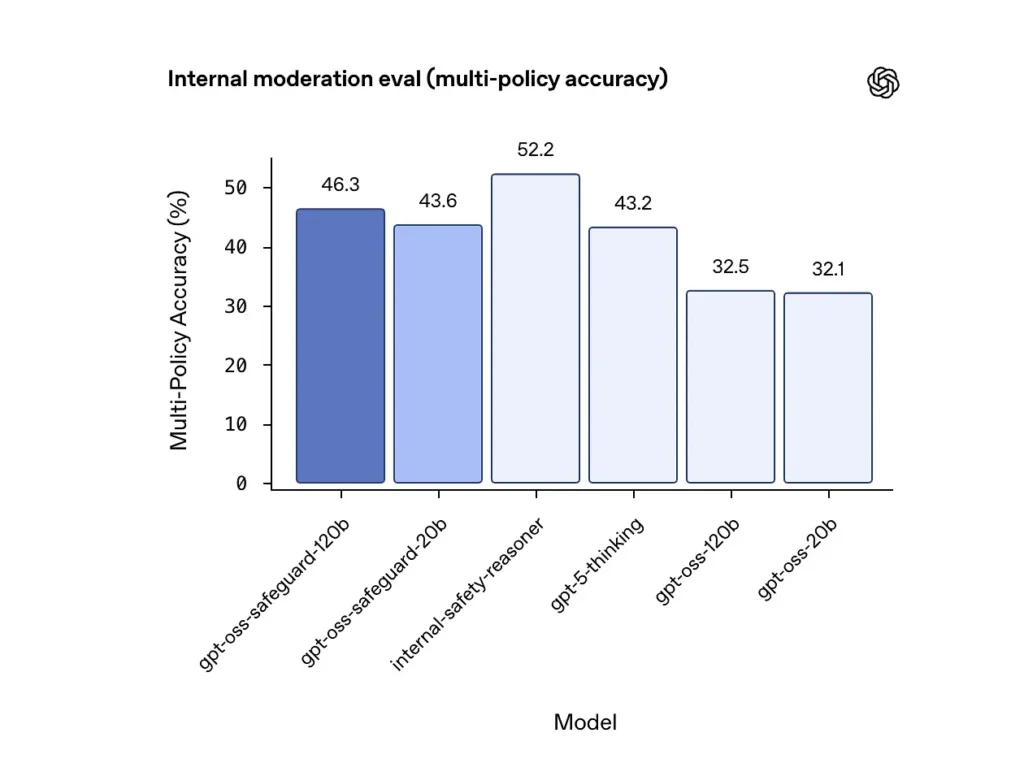
Dokładność wielopolitykowa (ocena wewnętrzna)
OpenAI oceniło dokładność wielu polityk, podając modelowi wielokrotność polityki jednocześnie i uznając prognozę za poprawną tylko wtedy, gdy pasowała do złotych etykiet cała kolekcja polityki. Wyniki:
- gpt-oss-safeguard-120b: 46.3% dokładność wielopolityczna
- gpt-oss-safeguard-20b: 43.6%
- Dla porownania: gpt-5-myślenie: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: % 32.1.
Wewnętrzny zespół „rozumowania bezpieczeństwa” OpenAI uzyskał wynik 52.2% w tym samym teście. Te wyniki pokazują, że modele zabezpieczeń znacznie przewyższają swoje modele bazowe gpt-oss w zadaniu wielopolitykowym, a nawet przewyższyły większy model bazowy gpt-5 w wewnętrznym pomiarze wielopolitykowym.
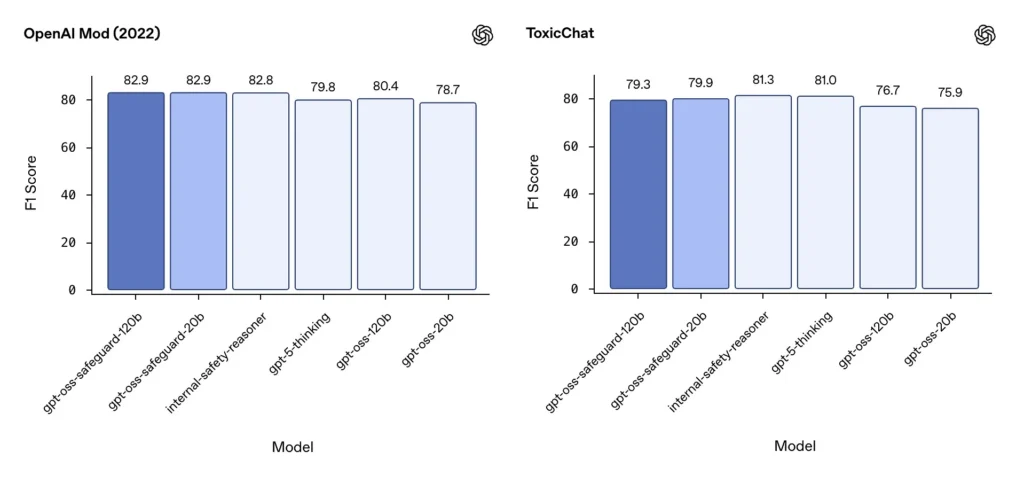
Moderacja F1 (zewnętrzne testy porównawcze)
W zestawie danych moderacji OpenAI z 2022 r. i publicznym teście porównawczym ToxicChat modele gpt-oss-safeguard uzyskały solidne wyniki F1:
- Modyfikacja OpenAI (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Wyniki te plasują gpt-oss-safeguard blisko lub nieznacznie za wyspecjalizowanymi wewnętrznymi systemami OpenAI w niektórych testach porównawczych i ogólnie przed niedostrojonymi odpowiednikami gpt-oss.
Zaobserwowane ograniczenia
OpenAI wskazuje na dwa praktyczne ograniczenia:
- Klasyfikatory trenowane na dużych, oznaczonych zestawach danych specyficznych dla danego zadania nadal mogą działać lepiej niż modele zabezpieczające gdy jedynym celem jest dokładność klasyfikacji.
- Koszty obliczeniowe i opóźnienia: Rozumowanie CoT wydłuża czas wnioskowania i zwiększa zużycie mocy obliczeniowej, co komplikuje skalowanie do ruchu na poziomie platformy, chyba że zostanie połączone z klasyfikatorami triażowymi i asynchronicznymi potokami.
Parytet wielojęzyczny
gpt-oss-safeguard działa na równi z podstawowymi modelami gpt-oss w testach w stylu MMMLU w wielu językach, co wskazuje, że udoskonalone warianty zabezpieczeń zachowują szerokie możliwości wnioskowania.
W jaki sposób zespoły mogą uzyskać dostęp do gpt-oss-safeguard i go wdrożyć?
OpenAI udostępnia wagi w ramach Apache 2.0 i łączy modele do pobrania (Hugging Face). Ponieważ gpt-oss-safeguard jest modelem o otwartej wadze, lokalne i samodzielne wdrożenie (zalecane ze względu na prywatność i personalizację)
- Pobierz wagi modeli (z OpenAI / Hugging Face) i hostuj je na własnych serwerach lub maszynach wirtualnych w chmurze. Apache 2.0 umożliwia modyfikację i wykorzystanie komercyjne.
- Czas pracy:Używaj standardowych środowisk uruchomieniowych wnioskowania, które obsługują duże modele transformatorów (ONNX Runtime, Triton lub zoptymalizowane środowiska uruchomieniowe dostawców). Środowiska uruchomieniowe społeczności, takie jak Ollama i LM Studio, już dodają obsługę rodzin gpt-oss.
- sprzęt komputerowy: 120B zazwyczaj wymaga procesorów graficznych o dużej pamięci (np. 80 GB A100/H100 lub shardingu multi-GPU), natomiast 20B może być tańszy w użyciu i oferuje opcje zoptymalizowane pod kątem konfiguracji VRAM 16 GB. Zaplanuj pojemność pod kątem szczytowej przepustowości i kosztów oceny wielu polityk.
Środowiska wykonawcze zarządzane i stron trzecich
Jeśli uruchomienie własnego sprzętu jest niepraktyczne, Interfejs API Comet Szybko dodaje obsługę modeli gpt-oss. Platformy te mogą ułatwiać skalowanie, ale ponownie wprowadzają kompromisy związane z ujawnieniem danych stron trzecich. Przed wyborem zarządzanych środowisk wykonawczych należy ocenić kwestie prywatności, umowy SLA i kontrolę dostępu.
Skuteczne strategie moderacji z gpt-oss-safeguard
1) Użyj hybrydowego procesu (triaż → uzasadnienie → rozstrzygnięcie)
- Warstwa triażowa: Małe, szybkie klasyfikatory (lub reguły) odfiltrowują trywialne przypadki. Zmniejsza to obciążenie kosztownego modelu zabezpieczeń.
- Warstwa ochronna: uruchom gpt-oss-safeguard w przypadku kontroli niejednoznacznych, wysokiego ryzyka lub obejmujących wiele zasad, gdy niuanse zasad mają znaczenie.
- Orzeczenie ludzkie: Eskaluj przypadki skrajne i odwołania, przechowując CoT jako dowód przejrzystości. Ta hybrydowa konstrukcja równoważy przepustowość i precyzję.
2) Inżynieria polityki (nie inżynieria natychmiastowa)
- Traktuj zasady jak artefakty oprogramowania: twórz ich wersje, testuj je na zestawach danych i zadbaj o to, aby były jawne i hierarchiczne.
- Stwórz zasady z przykładami i kontrprzykładami. W miarę możliwości dołącz instrukcje ujednoznaczniające (np. „Jeśli intencja użytkownika jest wyraźnie eksploracyjna i historyczna, oznacz ją jako X; jeśli intencja jest operacyjna i realizowana w czasie rzeczywistym, oznacz ją jako Y”).
3) Dynamicznie skonfiguruj wysiłek rozumowania
- Zastosowanie niewielki wysiłek do przetwarzania masowego i duży wysiłek w przypadku oznaczonych treści, odwołań lub treści o dużym wpływie (prawne, medyczne, finansowe).
- Dostosuj progi na podstawie opinii użytkowników, aby znaleźć optymalny stosunek ceny do jakości.
4) Sprawdź CoT i zwróć uwagę na halucynacje
CoT jest cenny, ale może powodować halucynacje: ślad to racjonalne uzasadnienie wygenerowane przez model, a nie prawda. Rutynowo audytuj wyniki CoT; instrumenty wykrywają halucynacje lub niespójne rozumowanie. OpenAI dokumentuje halucynacje jako obserwowane wyzwanie i sugeruje strategie łagodzenia.
5) Tworzenie zestawów danych na podstawie operacji systemu
Rejestruj decyzje dotyczące modelu i poprawki wprowadzane przez człowieka, aby tworzyć oznaczone zbiory danych, które mogą usprawnić klasyfikatory triażowe lub stanowić podstawę do zmian w polityce. Z czasem niewielki, wysokiej jakości oznaczony zbiór danych wraz z wydajnym klasyfikatorem często zmniejsza zależność od pełnego wnioskowania CoT w przypadku rutynowych treści.
6) Monitoruj obliczenia i koszty; stosuj przepływy asynchroniczne
W przypadku aplikacji konsumenckich o niskim opóźnieniu należy rozważyć asynchroniczne kontrole bezpieczeństwa z krótkoterminowym, konserwatywnym UX (np. tymczasowe ukrycie treści do czasu weryfikacji) zamiast synchronicznego wykonywania pracochłonnego CoT. OpenAI zauważa, że Safety Reasoner wykorzystuje wewnętrznie asynchroniczne przepływy do zarządzania opóźnieniami w usługach produkcyjnych.
7) Weź pod uwagę prywatność i miejsce wdrożenia
Ponieważ wagi są otwarte, możesz przeprowadzać wnioskowanie w całości lokalnie, aby zachować zgodność z rygorystycznymi zasadami zarządzania danymi lub ograniczyć narażenie na działanie interfejsów API innych firm, co jest niezwykle cenne w przypadku branż regulowanych.
Wnioski:
gpt-oss-safeguard to praktyczne, przejrzyste i elastyczne narzędzie rozumowanie dotyczące bezpieczeństwa oparte na polityceŚwieci, kiedy potrzebujesz decyzje podlegające audytowi, powiązane z wyraźnymi zasadami, gdy Twoje zasady często się zmieniają lub gdy chcesz przeprowadzać kontrole bezpieczeństwa na miejscu. To jest nie Cudowna kula, która automatycznie zastąpi wyspecjalizowane klasyfikatory o dużej objętości — własne oceny OpenAI pokazują, że dedykowane klasyfikatory trenowane na dużych, oznaczonych korpusach mogą przewyższać te modele pod względem dokładności w przypadku wąskich zadań. Zamiast tego, należy traktować gpt-oss-safeguard jako strategiczny komponent: mechanizm wnioskowania z możliwością wyjaśnienia, stanowiący serce wielowarstwowej architektury bezpieczeństwa (szybka selekcja → wnioskowanie z możliwością wyjaśnienia → nadzór ludzki).
Jak zacząć
CometAPI to ujednolicona platforma API, która agreguje ponad 500 modeli AI od wiodących dostawców — takich jak seria GPT firmy OpenAI, Gemini firmy Google, Claude firmy Anthropic, Midjourney, Suno i innych — w jednym, przyjaznym dla programistów interfejsie. Oferując spójne uwierzytelnianie, formatowanie żądań i obsługę odpowiedzi, CometAPI radykalnie upraszcza integrację możliwości AI z aplikacjami. Niezależnie od tego, czy tworzysz chatboty, generatory obrazów, kompozytorów muzycznych czy oparte na danych potoki analityczne, CometAPI pozwala Ci szybciej iterować, kontrolować koszty i pozostać niezależnym od dostawcy — wszystko to przy jednoczesnym korzystaniu z najnowszych przełomów w ekosystemie AI.
Najnowsza integracja gpt-oss-safeguard wkrótce pojawi się w CometAPI, więc bądźcie czujni! Podczas gdy finalizujemy przesyłanie modelu gpt-oss-safeguard, programiści mogą uzyskać do niego dostęp API GPT-OSS-20B oraz API GPT-OSS-120B poprzez CometAPI, najnowsza wersja modelu jest zawsze aktualizowany na oficjalnej stronie internetowej. Na początek zapoznaj się z możliwościami modelu w Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. Interfejs API Comet zaoferuj cenę znacznie niższą niż oficjalna, aby ułatwić Ci integrację.
Gotowy do drogi?→ Zarejestruj się w CometAPI już dziś !
Jeśli chcesz poznać więcej wskazówek, poradników i nowości na temat sztucznej inteligencji, obserwuj nas na VK, X oraz Discord!