

xAI ogłoszono Grok 4 Fastzoptymalizowana pod względem kosztów wersja rodziny Grok, która według firmy zapewnia wydajność zbliżoną do flagowych modeli, jednocześnie obniżając cenę, aby osiągnąć taką wydajność dzięki 98% w porównaniu z Grok 4. Nowy model został zaprojektowany z myślą o wyszukiwaniu o wysokiej przepustowości i korzystaniu z narzędzi agentowych. Obejmuje okno kontekstowe o pojemności 2 milionów tokenów oraz oddzielne warianty „rozumujące” i „nierozumujące”, co pozwala programistom dostosować obliczenia do swoich potrzeb.
Główne funkcje i korzyści
Ekonomiczny model wnioskowania: Grok 4 Fast powstał na bazie rodziny Grok 4, ze szczególnym uwzględnieniem efektywności tokenów i wykorzystania narzędzi w czasie rzeczywistym. xAI informuje, że model wymaga około O 40% mniej „myślących” tokenów Średnio. Analiza sztuczna — która śledzi opóźnienia, prędkość wyjściową i stosunek ceny do wydajności w wielu publicznych modelach — plasuje Grok 4 Fast wysoko na granicy inteligencji i kosztów, a wczesne testy potwierdzają wysoką prędkość wyjściową i korzystny stosunek ceny do jakości.
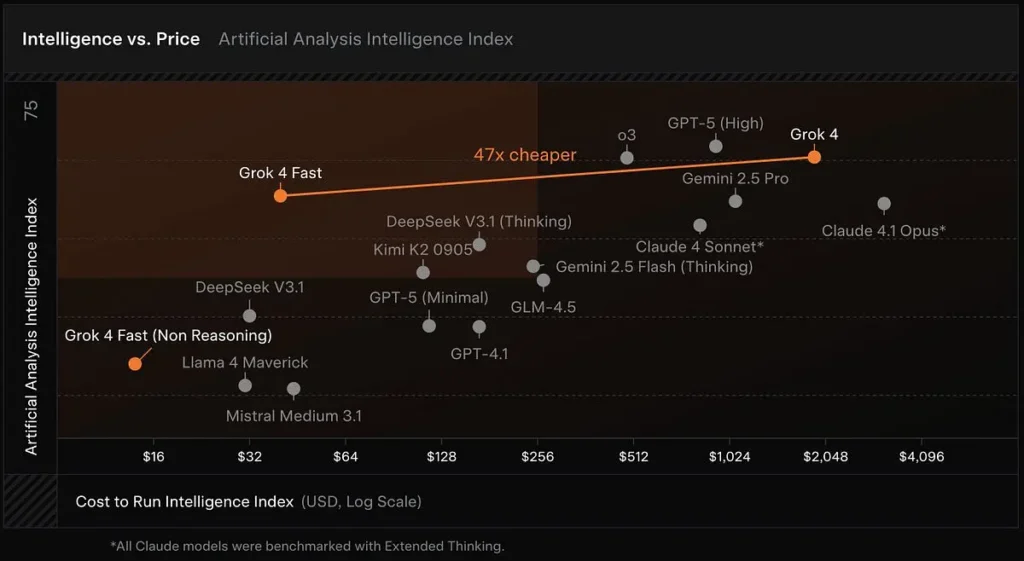
Duże okna kontekstowe: Grok 4 Fast został zaprojektowany do wyszukiwania o wysokiej przepustowości i korzystania z narzędzi agentowych. Zawiera okno kontekstowe o pojemności 2 milionów tokenów oraz oddzielne warianty „rozumujące” i „nierozumujące”, dzięki czemu programiści mogą dostosować obliczenia do swoich potrzeb.
Możliwości natywnego korzystania z narzędzi: Grok 4 Fast zapewnia „najnowocześniejsze możliwości wyszukiwania w sieci i X”, które usprawniają pobieranie, nawigację i syntezę treści internetowych podczas przepływów pracy agentów — co sprawia, że Grok 4 Fast jest praktycznym narzędziem wyszukiwania dla aplikacji wymagających gromadzenia informacji w czasie rzeczywistym i wnioskowania na podstawie długich dokumentów. Wiodąca wydajność w wielu testach porównawczych wyszukiwania, w tym:
- BrowseComp (zh): 51.2% (w porównaniu do 45.0% Groka 4)
- X Bench Deepsearch (zh): 74.0% (w porównaniu do 66.0% Groka 4)
Zunifikowana architektura: Ten sam model obsługuje zarówno tryby wnioskowania, jak i niewnioskowania, eliminując potrzebę oddzielnego przełączania modeli. Niższe opóźnienia i niższe koszty sprawiają, że nadaje się on do zastosowań w czasie rzeczywistym (takich jak wyszukiwanie, odpowiadanie na pytania i pomoc badawcza).
Porównanie wydajności (główne testy)
W prywatnych testach LMArena, którymi dzielił się xAI, grok-4-fast-search (nazwa kodowa menlo) wariant zajmuje pierwsze miejsce w Search Arena z oceną ELO wynoszącą 1,163, podczas gdy wariant tekstowy (tahoe) znajduje się w pierwszej dziesiątce rankingu Text Arena — wyników, które xAI wykorzystuje do uzasadnienia swoich twierdzeń na temat wydajności wyszukiwania.
Grok 4 Szybko dorównuje Grok 4 lub niewiele ustępuje mu w wielu testach porównawczych (na przykład: GPQA Diamond, AIME 2025 i HMMT 2025), a jednocześnie przewyższa poprzednie, mniejsze modele w zadaniach rozumowania — to dowód, którego xAI używa do uzasadnienia twierdzenia o „porównywalnej wydajności”.
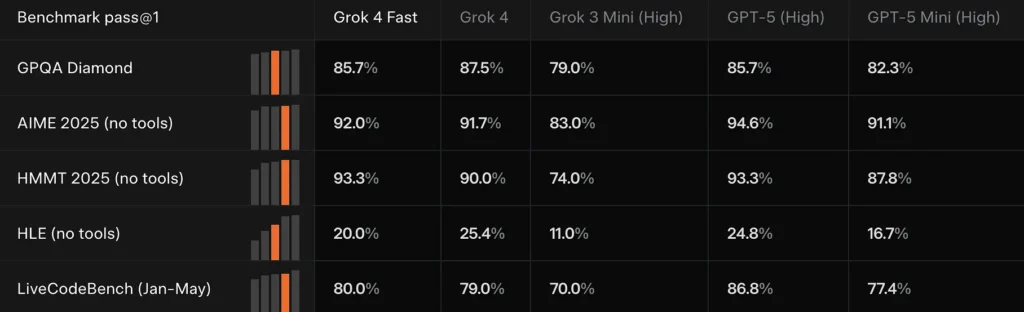
Porównaj wyniki
W porównaniu do Grok 4: Tańszy i mniej wymagający obliczeniowo, ale o podobnej wydajności.
W porównaniu do Grok 3 Mini: Większa moc, zdolność do złożonego rozumowania i wyszukiwania w czasie rzeczywistym.
W porównaniu do GPT-5/Gemini/Claude: Dzięki niezwykle wysokiej wydajności tokenów i możliwościom narzędziowym jest liderem pod względem opłacalności i niektórych zadań wyszukiwania.
Ceny i dostępność
Kontekst i tokeny: Dwa modele smaków: grok-4-fast-reasoning oraz grok-4-fast-non-reasoning, każdy z kontekstem 2M.
Opublikowane (lista) cen w poście o premierze (przykładowe poziomy):
- Tokeny wejściowe: 0.20 USD / 1 mln (<128 tys.) — 0.40 USD / 1 mln (≥128 tys.)
- Tokeny wyjściowe: 0.50 USD / 1 mln (<128 tys.) — 1.00 USD / 1 mln (≥128 tys.)
- Zapisane w pamięci podręcznej tokeny wejściowe: 0.05 USD / 1 mln.
(Dokładne zasady rozliczeń i wszelkie promocje ograniczone czasowo można znaleźć w ogłoszeniu xAI.)
Dostępność dostawcy: xAI podaje informacje o krótkoterminowej bezpłatnej dostępności za pośrednictwem OpenRouter i Vercel AI Gateway, a ogólną dostępność za pośrednictwem interfejsu API xAI.
Co to oznacza dla użytkowników i zespołów
- Duże oszczędności kosztów w zastosowaniach produkcyjnych — połączenie niższych cen za token i mniejszej liczby tokenów „myślących” oznacza, że zespoły mogą uruchamiać więcej zapytań lub przepływy pracy o szerszym kontekście za ułamek kosztów Grok 4, co znacząco obniża bariery dla eksperymentów i skalowalnych wdrożeń. (Twierdzenie poparte informacjami o kosztach/wydajności xAI oraz analizami kosztów przeprowadzonymi przez firmy zewnętrzne).
- Działa z bardzo długimi dokumentami i rozumowaniem wieloetapowym — Dzięki tokenom 2M możliwe jest przetwarzanie całych książek, dużych baz kodów lub długich dokumentacji prawnej/technicznej w ramach jednej sesji, co zwiększa dokładność i spójność zadań wymagających kontekstu długoterminowego (wyszukiwanie dokumentów, podsumowywanie, generowanie długich kodów, asystenci badawczy).
- Szybsze wyniki o mniejszym opóźnieniu dla aplikacji interaktywnych — jako wariant „szybki”, został zaprojektowany z myślą o szybszej przepustowości tokenów i niższych opóźnieniach, co jest korzystne dla interfejsów użytkownika czatu, asystentów kodowania i pętli agentów w czasie rzeczywistym, gdzie liczy się responsywność. (Badania porównawcze sztucznej inteligencji i dostawców podkreślają szybkość wyjściową jako czynnik różnicujący).
- Dobry stosunek ceny do wydajności w przypadku zadań wymagających rozumowania porównawczego — dla zespołów, które oceniają modele na podstawie pionierskich akademickich testów porównawczych, Grok 4 Fast oferuje mocny kompromis: dokładność zbliżoną do pionierskiej przy znacznie niższych kosztach, co czyni je atrakcyjnym rozwiązaniem dla laboratoriów badawczych i firm, które często korzystają z drogich pakietów testów porównawczych.
Wnioski:
Grok 4 Fast pozycjonuje xAI jako platformę konkurencyjną pod względem stosunku ceny do wydajności oraz w aplikacjach agentów skoncentrowanych na wyszukiwaniu. Jeśli deklaracje firmy dotyczące wydajności i weryfikacji potwierdzą się w niezależnych testach w poszczególnych domenach, Grok 4 Fast może zmienić oczekiwania dotyczące kosztów wdrożeń LLM o wysokiej wydajności i obsłudze narzędzi — szczególnie w przypadku aplikacji, które opierają się na pobieraniu danych z Internetu w czasie rzeczywistym i wieloetapowym korzystaniu z narzędzi.
Jak zacząć
CometAPI to ujednolicona platforma API, która agreguje ponad 500 modeli AI od wiodących dostawców — takich jak seria GPT firmy OpenAI, Gemini firmy Google, Claude firmy Anthropic, Midjourney, Suno i innych — w jednym, przyjaznym dla programistów interfejsie. Oferując spójne uwierzytelnianie, formatowanie żądań i obsługę odpowiedzi, CometAPI radykalnie upraszcza integrację możliwości AI z aplikacjami. Niezależnie od tego, czy tworzysz chatboty, generatory obrazów, kompozytorów muzycznych czy oparte na danych potoki analityczne, CometAPI pozwala Ci szybciej iterować, kontrolować koszty i pozostać niezależnym od dostawcy — wszystko to przy jednoczesnym korzystaniu z najnowszych przełomów w ekosystemie AI.
Deweloperzy mogą uzyskać dostęp Grok-4-fast (model: grok-4-fast-reasoning” / “grok-4-fast-reasoning) poprzez CometAPI, najnowsza wersja modelu jest zawsze aktualizowany na oficjalnej stronie internetowej. Na początek zapoznaj się z możliwościami modelu w Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. Interfejs API Comet zaoferuj cenę znacznie niższą niż oficjalna, aby ułatwić Ci integrację.
Gotowy do drogi?→ Zarejestruj się w CometAPI już dziś !