
grok-code-fast-1 jest xAI skoncentrowany na szybkości i ekonomiczny model kodowania agentowego Zaprojektowany do obsługi integracji IDE i zautomatyzowanych agentów kodujących. Podkreśla małe opóźnienie, zachowania agentów (wywołania narzędzi, ślady rozumowania krok po kroku) oraz kompaktowy profil kosztów dla codziennych przepływów pracy programistów.
Najważniejsze cechy (w skrócie)
- Wysoka przepustowość / niskie opóźnienie: skoncentrowano się na bardzo szybkim generowaniu tokenów i szybkim uzupełnianiu ich w celu wykorzystania w środowisku IDE.
- Wywoływanie funkcji agenta i narzędzia: obsługuje wywołania funkcji i zewnętrzną orkiestrację narzędzi (uruchamianie testów, lintery, pobieranie plików), aby umożliwić agentom kodowanie wieloetapowe.
- Duże okno kontekstowe: Zaprojektowany do obsługi dużych baz kodów i kontekstów wieloplikowych (dostawcy wymieniają okna kontekstowe o rozmiarze 256 tys. w adapterach rynkowych).
- Widoczne rozumowanie / ślady: odpowiedzi mogą zawierać ślady rozumowania krok po kroku, mające na celu umożliwienie inspekcji i debugowania decyzji agenta.
Szczegóły techniczne
Architektura i szkolenia: xAI twierdzi, że grok-code-fast-1 został zbudowany od podstaw z nową architekturą i korpusem przedtreningowym bogatym w treści programistyczne; następnie model został poddany obróbce potreningowej na podstawie wysokiej jakości, rzeczywistych zestawów danych pull-request/kodu. Ten proces inżynieryjny ma na celu… praktyczne wewnętrzne przepływy pracy agentów (IDE + użycie narzędzi).
Podawanie i kontekst: grok-code-fast-1 Typowe wzorce użycia zakładają strumieniowe przesyłanie danych, wywołania funkcji i wstrzykiwanie bogatego kontekstu (przesyłanie/kolekcje plików). Kilka platform chmurowych i adapterów platformowych już obsługuje obsługę szerokiego kontekstu (256 tys. kontekstów w niektórych adapterach).
Cechy użytkowe: Statystyki ślady rozumowania (model przedstawia sposób planowania/użycia narzędzi), wskazówki dotyczące szybkiej inżynierii i przykładowe integracje oraz wczesne integracje z partnerami (np. GitHub Copilot, Cursor).
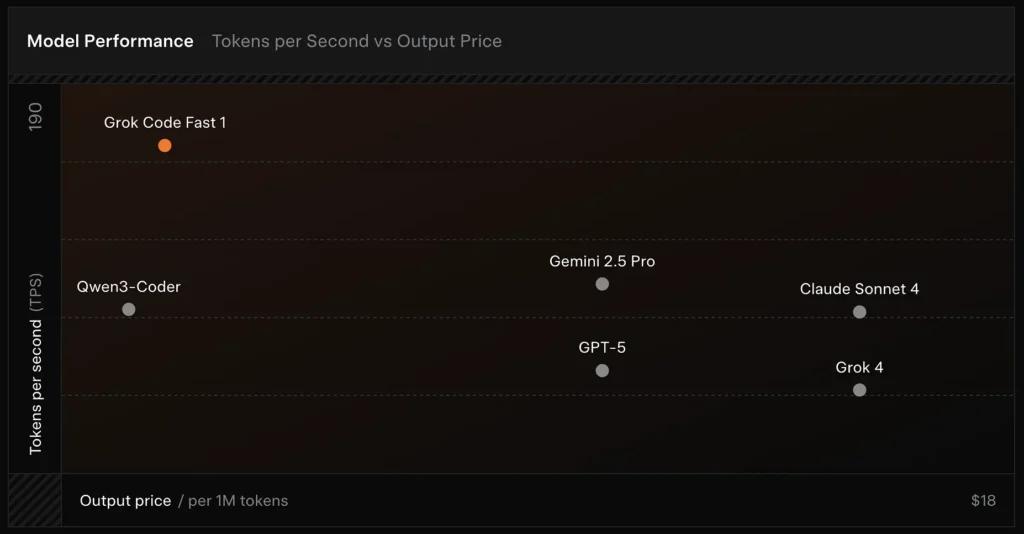
Wydajność benchmarku (w jakim zakresie uzyskuje się wyniki)
Zweryfikowano przez SWE-Bench: xAI raportuje 70.8% wynik w ich wewnętrznym zestawieniu SWE-Bench-Verified — benchmarku powszechnie stosowanego do porównywania modeli inżynierii oprogramowania. Niedawna praktyczna ocena wykazała średnia ocena człowieka ≈ 7.6 w mieszanym pakiecie kodowania — konkurencyjny w porównaniu z niektórymi modelami o wysokiej wartości (np. Gemini 2.5 Pro), ale ustępując większym modelom multimodalnym/modelom „najlepszego rozumu”, takim jak Claude Opus 4 i Grok 4 firmy xAI, w przypadku zadań wymagających wysokiego poziomu trudności. Testy porównawcze wykazują również zróżnicowanie w zależności od zadania: doskonały w przypadku typowych poprawek błędów i zwięzłego generowania kodu, słabszy w przypadku niektórych problemów niszowych lub specyficznych dla bibliotek (przykład Tailwind CSS).
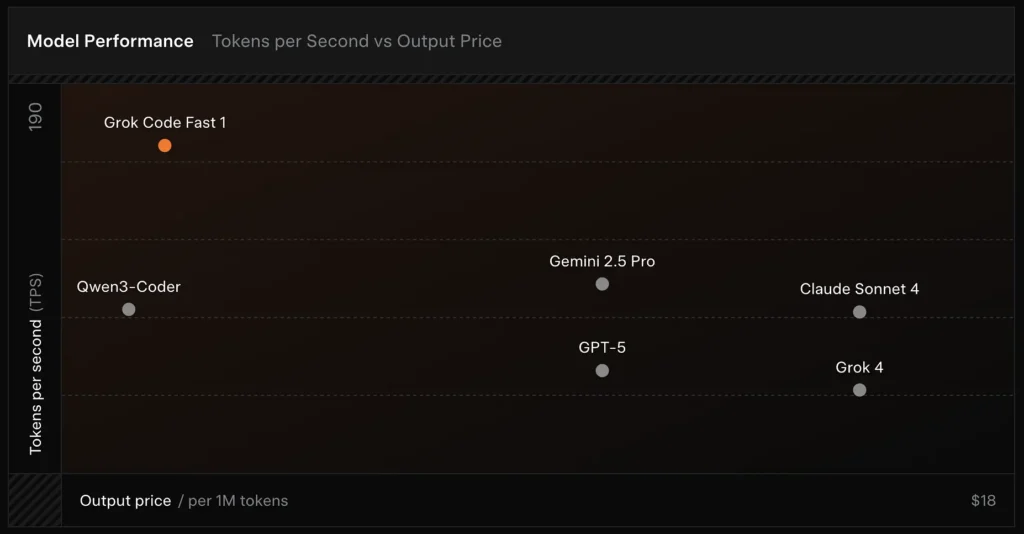
Porównanie :
- vs Grok 4: Grok-code-fast-1 oferuje pewną absolutną poprawność i głębsze rozumowanie za znacznie niższy koszt i szybsza przepustowość; Grok 4 pozostaje opcją o większych możliwościach.
- vs Claude Opus / klasa GPT: Modele te często rozwiązują złożone, kreatywne lub wymagające trudnego rozumowania zadania; Grok-code-fast-1 dobrze sprawdza się w przypadku zadań deweloperskich o dużej objętości i rutynowych, w których opóźnienia i koszty mają znaczenie.
Ograniczenia i ryzyko
Dotychczas zaobserwowane ograniczenia praktyczne:
- Luki w domenach: spadki wydajności w przypadku niszowych bibliotek lub nietypowo sformułowane problemy (przykładami są skrajne przypadki Tailwind CSS).
- Kompromis między kosztami rozumowania a kosztami tokena: Ponieważ model może emitować wewnętrzne tokeny rozumowania, wysoce agentywne/rozwlekłe rozumowanie może zwiększyć długość wyjścia wnioskowania (i jego koszt).
- Dokładność / przypadki skrajne: choć silny w zadaniach rutynowych, Grok-code-fast-1 może halucynacje lub wygenerować niepoprawny kod dla nowych algorytmów lub opisów problemów antagonistycznych; może on działać gorzej niż najlepsze modele oparte na rozumowaniu w wymagających algorytmicznych testach porównawczych.
Typowe przypadki użycia
- Pomoc IDE i szybkie prototypowanie: szybkie uzupełnianie, przyrostowe pisanie kodu i interaktywne debugowanie.
- Zautomatyzowane przepływy pracy agentów/kodu: agenci, którzy organizują testy, uruchamiają polecenia i edytują pliki (np. pomocnicy CI, recenzenci botów).
- Codzienne zadania inżynierskie: generowanie szkieletów kodu, refaktoryzacji, sugestii dotyczących selekcji błędów i tworzenia rusztowań projektów składających się z wielu plików, gdzie niskie opóźnienia znacząco usprawniają pracę programistów.
Jak wywołać API grok-code-fast-1 z CometAPI
grok-code-fast-1 Ceny API w CometAPI, 20% zniżki od ceny oficjalnej:
- Żetony wejściowe: 0.16$/M żetonów
- Tokeny wyjściowe: 2.0/M tokenów
Wymagane kroki
- Zaloguj się do pl.com. Jeśli jeszcze nie jesteś naszym użytkownikiem, zarejestruj się najpierw
- Pobierz klucz API uwierzytelniania dostępu do interfejsu. Kliknij „Dodaj token” przy tokenie API w centrum osobistym, pobierz klucz tokena: sk-xxxxx i prześlij.
Użyj metody
- Wybierz "
grok-code-fast-1” punkt końcowy do wysłania żądania API i ustawienia treści żądania. Metoda żądania i treść żądania są pobierane z naszej witryny internetowej API doc. Nasza witryna internetowa udostępnia również test Apifox dla Twojej wygody. - Zastępować za pomocą aktualnego klucza CometAPI ze swojego konta.
- Wpisz swoje pytanie lub prośbę w polu treści — model odpowie właśnie na tę wiadomość.
- . Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź.
CometAPI zapewnia w pełni kompatybilne API REST, co umożliwia bezproblemową migrację. Kluczowe szczegóły Dokumentacja API:
- Adres URL bazowy: https://api.cometapi.com/v1/chat/completions
- Nazwy modeli: "
grok-code-fast-1" - Poświadczenie: Token okaziciela poprzez
Authorization: Bearer YOUR_CometAPI_API_KEYnagłówek - Typ zawartości:
application/json.
Integracja API i przykłady
Fragment kodu Pythona dla Zakończenie czatu połączenie przez CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Zobacz także Grok 4