

GLM-5 to nowy model bazowy Zhipu AI o otwartych wagach, zorientowany na agentów, zbudowany z myślą o długohoryzontowym kodowaniu i agentach wieloetapowych. Jest dostępny przez kilka hostowanych interfejsów API (w tym CometAPI i endpointy dostawców) oraz jako wydanie badawcze z kodem i wagami; można go zintegrować za pomocą standardowych wywołań REST zgodnych z OpenAI, strumieniowania i SDK.
Czym jest GLM-5 od Z.ai?
GLM-5 to flagowy, piątej generacji model bazowy Z.ai zaprojektowany dla inżynierii agentowej: planowania w długim horyzoncie, wieloetapowego użycia narzędzi i projektowania kodu/systemów na dużą skalę. Publicznie wydany w lutym 2026, GLM-5 to model typu Mixture-of-Experts (MoE) z ~744 miliardami łącznych parametrów i aktywnym zbiorem parametrów rzędu 40B na jedno przejście w przód; wybory architektoniczne i treningowe priorytetyzują spójność w długim kontekście, wywoływanie narzędzi oraz opłacalne kosztowo wnioskowanie dla obciążeń produkcyjnych. Te decyzje projektowe pozwalają GLM-5 prowadzić wydłużone przepływy pracy agentów (np.: przeglądaj → planuj → pisz/testuj kod → iteruj), zachowując kontekst przy bardzo długich wejściach.
Najważniejsze aspekty techniczne:
- Architektura MoE: ~744B parametrów łącznie / ~40B aktywnych; skalowany pretraining (~28.5T tokenów raportowane), aby zmniejszyć dystans do czołowych modeli zamkniętych.
- Obsługa długiego kontekstu i optymalizacje (deep sparse attention, DSA) dla niższego kosztu wdrożenia względem naiwnego gęstego skalowania.
- Wbudowane możliwości agentowe: wywoływanie narzędzi/funkcji, obsługa sesji ze stanem oraz zintegrowane wyjścia (zdolność tworzenia artefaktów
.docx,.xlsx,.pdfw ramach przepływów pracy agentów w interfejsach dostawców). - Dostępność w formie open-weights (wagi publikowane w hubach modeli) oraz opcje hostowanego dostępu (API dostawców, mikrousługi inferencyjne).
Jakie są główne zalety GLM-5?
Planowanie agentowe i pamięć długohoryzontowa
Architektura i dostrajanie GLM-5 priorytetowo traktują spójne rozumowanie wieloetapowe i pamięć w całych przepływach pracy — co jest korzystne dla:
- agentów autonomicznych (pipeline’y CI, orkiestratory zadań),
- dużych generacji/refaktoryzacji kodu obejmujących wiele plików oraz
- przetwarzania dokumentów wymagającego utrzymania dużych historii.
Duże okna kontekstu
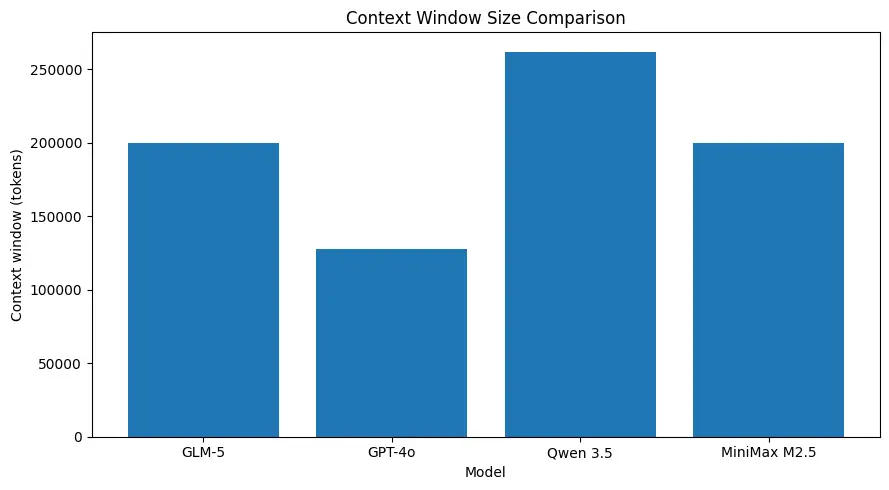
GLM-5 obsługuje bardzo duże rozmiary kontekstu (rzędu ~200k tokenów według opublikowanych specyfikacji), co pozwala utrzymać większą część sesji w jednym żądaniu i ogranicza potrzebę agresywnego dzielenia na fragmenty lub zewnętrznej pamięci w wielu zastosowaniach. (Zobacz wykres porównawczy poniżej.)
Wysoka skuteczność w kodowaniu zadań na poziomie systemowym
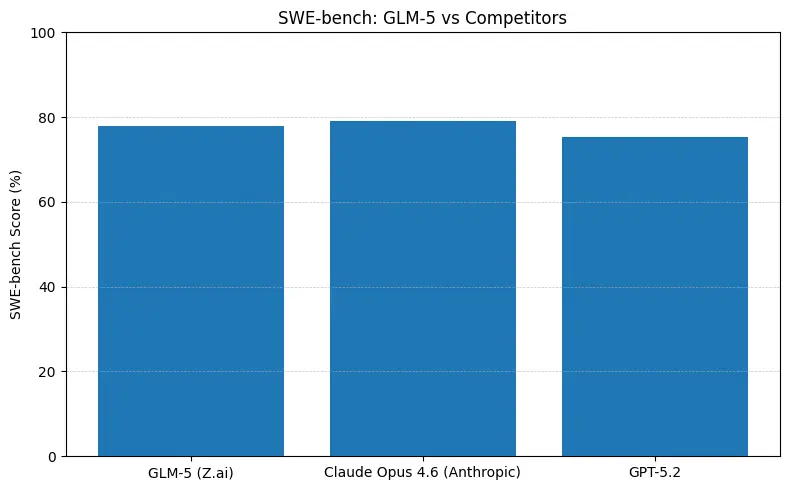
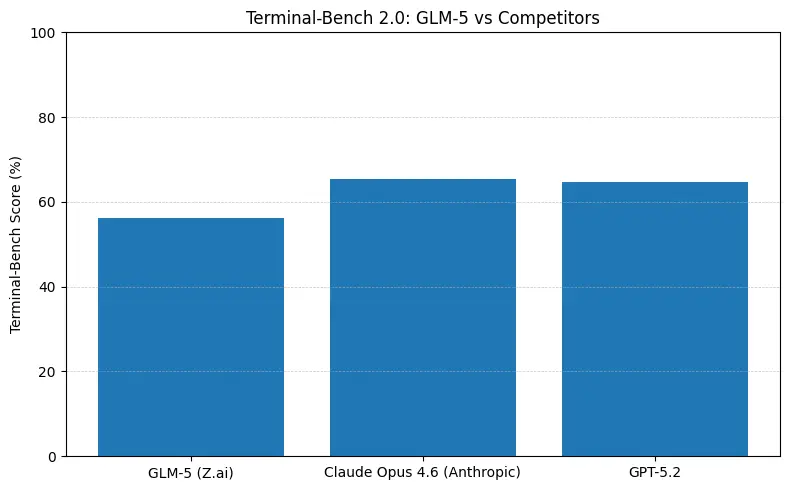
GLM-5 wykazuje czołową wydajność open-source w benchmarkach inżynierii oprogramowania (SWE-bench oraz praktyczne zestawy kod + agent). Na SWE-bench-Verified raportuje ~77.8%; w testach agentów w stylu kodowanie/terminal (Terminal-Bench 2.0) wyniki skupiają się w połowie przedziału 50% — co stanowi dowód praktycznych umiejętności kodowania zbliżających się do modeli własnościowych klasy frontier. Te metryki oznaczają, że GLM-5 nadaje się do zadań takich jak generowanie kodu, automatyczna refaktoryzacja, rozumowanie między plikami oraz scenariusze asystenta CI/CD.
Kompromisy koszt/efektywność
Ponieważ GLM-5 wykorzystuje MoE oraz innowacje „sparse” attention, dąży do obniżenia kosztu inferencji na jednostkę możliwości w porównaniu z siłowym gęstym skalowaniem. CometAPI oferuje konkurencyjne ceny, które czynią GLM-5 atrakcyjnym dla agentowych obciążeń o wysokiej przepustowości.
Jak korzystać z API GLM-5 przez CometAPI?
Krótka odpowiedź: traktuj CometAPI jak bramkę zgodną z OpenAI — ustaw bazowy URL i klucz API, wybierz glm-5 jako model, a następnie wywołaj endpoint chat/completions. CometAPI udostępnia REST zgodny ze stylem OpenAI (endpointy typu /v1/chat/completions) oraz SDK i przykładowe projekty, które upraszczają migrację.
Poniżej praktyczny, produkcyjny „cookbook”: uwierzytelnianie, podstawowe wywołanie czatu, strumieniowanie, wywoływanie funkcji/narzędzi oraz obsługa kosztów/odpowiedzi.
Podstawowe kroki dostępu do GLM-5 przez CometAPI:
- Zarejestruj się w CometAPI, uzyskaj klucz API.
- Znajdź dokładny identyfikator modelu GLM-5 w katalogu CometAPI (
"glm-5"w zależności od listingu). - Wyślij uwierzytelnione żądanie POST do endpointu chat/completions CometAPI (w stylu OpenAI).
Szczegóły bazowe (wzorce CometAPI): platforma obsługuje ścieżki w stylu OpenAI, takie jak https://api.cometapi.com/v1/chat/completions, uwierzytelnianie Bearer, parametr model, wiadomości system/user, strumieniowanie oraz przykłady curl/python w dokumentacji.
Przykład: szybkie wywołanie czatu w Pythonie (requests) z GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Przykład: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Strumieniowe odpowiedzi (praktyczny wzorzec)
CometAPI obsługuje strumieniowanie w stylu OpenAI (SSE / chunked). Najprostsze podejście w Pythonie to ustawić "stream": true i iterować po danych odpowiedzi w miarę ich napływu. Jest to ważne, gdy potrzebujesz niskiej latencji częściowego wyjścia (budowa asystentów deweloperskich w czasie rzeczywistym, interfejsów ze strumieniowaniem).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Odnośnik: strumieniowanie w stylu OpenAI i dokumentacja zgodności CometAPI.
Wywoływanie funkcji/narzędzi (jak wywołać zewnętrzne narzędzie)
GLM-5 obsługuje wzorce wywoływania funkcji lub narzędzi zgodne z konwencjami OpenAI/agregatorów (bramka przekazuje ustrukturyzowane wywołania funkcji w odpowiedzi modelu). Przykład użycia: poproś GLM-5 o wywołanie lokalnego narzędzia „run_tests”; model zwróci ustrukturyzowaną instrukcję, którą możesz sparsować i wykonać.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Gdy model zwróci ładunek function_call, wykonaj narzędzie po stronie serwera, następnie przekaż wynik narzędzia z powrotem jako wiadomość z rolą "tool" i kontynuuj rozmowę. Ten wzorzec umożliwia bezpieczne wywoływanie narzędzi i stanowe przepływy agentów. Zobacz dokumentację i przykłady CometAPI po konkretne pomocniki SDK.
Praktyczne parametry i strojenie
function_call: używaj do włączania ustrukturyzowanego wywoływania narzędzi i bezpieczniejszych przepływów wykonywania.
temperature: 0–0.3 dla deterministycznych rezultatów na poziomie systemu (kod, infrastruktura), wyżej dla ideacji.
max_tokens: ustaw pod oczekiwaną długość wyjścia; GLM-5 obsługuje bardzo długie wyjścia w środowiskach hostowanych (limity zależą od dostawcy).
top_p / nucleus sampling: przydatne do ograniczania mało prawdopodobnych ogonów.
stream: true dla interfejsów interaktywnych.
Porównanie GLM-5 z Claude Opus od Anthropic i innymi modelami frontier
Krótka odpowiedź: GLM-5 zmniejsza dystans do czołowych modeli zamkniętych w benchmarkach agentowych i kodowych, oferując wdrożenia z otwartymi wagami i często lepszy koszt na token przy hostingu u agregatorów. Niuans: w niektórych bezwzględnych benchmarkach kodu (SWE-bench, warianty Terminal-Bench) Claude Opus (4.5/4.6) nadal prowadzi o kilka punktów w wielu opublikowanych rankingach — jednak GLM-5 jest bardzo konkurencyjny i przewyższa wiele innych modeli otwartych.
Co liczby znaczą w praktyce
- SWE-bench (~poprawność kodu / inżynieria): Claude Opus wykazuje marginalną przewagę (≈79% vs GLM-5 ≈77.8%) w publikowanych rankingach; dla wielu realnych zadań ta różnica przełoży się na mniej ręcznych poprawek, ale niekoniecznie na inną decyzję architektoniczną dla prototypowania lub skalowanych agentowych przepływów pracy.
- Terminal-Bench (zadania agentowe w wierszu poleceń): Opus 4.6 prowadzi (≈65.4% vs GLM-5 ≈56.2%) — jeśli potrzebujesz solidnej automatyzacji terminala i najwyższej niezawodności w zadaniach out-of-distribution w powłoce, Opus często jest lepszy na marginesie.
- Agentowe i długohoryzontowe: GLM-5 wypada bardzo dobrze w długohoryzontowych symulacjach biznesowych (Vending-Bench 2 saldo $4,432 raportowane) i wykazuje silną spójność planowania dla wieloetapowych przepływów. Jeśli Twój produkt to długo działający agent (finanse, operacje), GLM-5 jest mocny.
Jak projektować prompty i systemy, aby uzyskiwać niezawodne wyniki GLM-5?
Wiadomości systemowe i jawne ograniczenia
Nadaj GLM-5 ścisłą rolę i ograniczenia, zwłaszcza dla zadań z kodem lub wywoływaniem narzędzi. Przykład:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Proś o testy i krótkie uzasadnienie dla każdej nietrywialnej zmiany.
Dekomponuj złożone zadania
Zamiast „napisz cały produkt”, poproś o:
- zarys projektu,
- sygnatury interfejsów,
- implementację i testy,
- końcowy skrypt integracyjny.
Takie stopniowe rozbicie ogranicza halucynacje i daje deterministyczne punkty kontrolne do weryfikacji.
Używaj niskiej temperatury dla deterministycznego kodu
Prosząc o kod, ustaw temperature = 0–0.2 i max_tokens na bezpieczną wartość górną. Dla kreatywnego pisania lub burzy mózgów projektowych podnieś temperaturę.
Najlepsze praktyki integracji GLM-5 (przez CometAPI lub bezpośrednich hostów)
Inżynieria promptów i prompty systemowe
- Używaj jednoznacznych instrukcji w roli systemu, które definiują role agentów, polityki dostępu do narzędzi i ograniczenia bezpieczeństwa. Przykład: „Jesteś architektem systemów: proponuj zmiany tylko wtedy, gdy testy jednostkowe przechodzą lokalnie; wypisz dokładne polecenia CLI do uruchomienia.”
- W zadaniach kodowych podaj kontekst repozytorium (listy plików, kluczowe fragmenty kodu) i dołącz wyniki testów jednostkowych, jeśli są dostępne. Obsługa długiego kontekstu przez GLM-5 pomaga — ale zawsze umieszczaj najpierw kontekst kluczowy (rola, zadanie), a potem materiały pomocnicze.
Sesja i zarządzanie stanem
- Używaj identyfikatorów sesji dla długich rozmów agentów i utrzymuj skompaktowaną „pamięć” poprzednich kroków (streszczenia), aby zapobiegać puchnięciu kontekstu. CometAPI i podobne bramki zapewniają pomocniki sesji/stanu — ale kompakcja stanu na poziomie aplikacji jest kluczowa dla długo działających agentów.
Narzędzia i wywołania funkcji (bezpieczeństwo + niezawodność)
- Udostępniaj wąski, audytowalny zestaw narzędzi. Nie zezwalaj na dowolne wykonywanie poleceń powłoki bez nadzoru człowieka. Używaj ustrukturyzowanych definicji funkcji i waliduj ich argumenty po stronie serwera.
- Zawsze loguj wywołania narzędzi i odpowiedzi modelu dla śledzenia i debugowania po incydentach.
Kontrola kosztów i batching
- Dla agentów o dużej skali kieruj przetwarzanie w tle do tańszych wariantów modeli, gdy akceptowalne są kompromisy jakości (CometAPI pozwala przełączać modele po nazwie). Grupuj podobne żądania i zmniejszaj
max_tokenstam, gdzie to możliwe. Monitoruj stosunek tokenów wejściowych do wyjściowych — tokeny wyjściowe są często droższe.
Inżynieria opóźnień i przepustowości
- Używaj strumieniowania dla sesji interaktywnych. Dla zadań agentów w tle preferuj asynchroniczne środowiska uruchomieniowe, kolejki workerów i ograniczniki szybkości. Jeśli hostujesz samodzielnie (open weights), dostrój topologię akceleratorów do architektury MoE — opcje FPGA / Ascend / wyspecjalizowane układy mogą przynieść oszczędności kosztów.
Uwagi końcowe
GLM-5 to praktyczny krok w kierunku inżynierii agentowej z otwartymi wagami: duże okna kontekstu, zdolności planowania i wysoka wydajność w kodzie czynią go atrakcyjnym dla narzędzi deweloperskich, orkiestracji agentów i automatyzacji na poziomie systemowym. Użyj CometAPI do szybkiej integracji lub ogrodu modeli w chmurze do zarządzanego hostingu; zawsze weryfikuj na swoim obciążeniu i intensywnie instrumentuj pod kątem kosztów i kontroli halucynacji.
Programiści mogą uzyskać dostęp do GLM-5 za pośrednictwem CometAPI już teraz. Na początek poznaj możliwości modelu w Playground i zapoznaj się z przewodnikiem API po szczegółowe instrukcje. Przed dostępem upewnij się, że zalogowałeś(-aś) się do CometAPI i uzyskałeś(-aś) klucz API. CometAPI oferuje cenę znacznie niższą niż cena oficjalna, aby ułatwić integrację.
Gotowy/a do działania?→ Sign up fo M2.5 today !
Jeśli chcesz poznawać więcej porad, przewodników i nowości o AI, obserwuj nas na VK, X i Discord!