

Claude Opus 4.5 to najnowszy model klasy „Opus” firmy Anthropic (wydany pod koniec listopada 2025 r.). Jest pozycjonowany jako model najwyższej klasy do profesjonalnego inżynieringu oprogramowania, agentowych przepływów pracy o długim horyzoncie oraz zadań o wysokiej stawce w przedsiębiorstwach, a Anthropic celowo wycenił go tak, by wysoka zdolność była bardziej dostępna dla użytkowników produkcyjnych. Poniżej wyjaśniam, czym jest Claude Opus 4.5 API, jak model wypada w rzeczywistych benchmarkach inżynierskich, jak dokładnie działa jego cennik (API i subskrypcja), jak to się ma do starszych modeli Anthropic i konkurentów (OpenAI, Google Gemini) oraz praktyczne najlepsze praktyki uruchamiania obciążeń produkcyjnych w sposób opłacalny. Dołączam też kod pomocniczy oraz mały zestaw do benchmarków i kalkulacji kosztów, który możesz skopiować i uruchomić.
What is the Claude Opus 4.5 API?
Claude Opus 4.5 to najnowszy model klasy Opus: model o wysokich możliwościach, multimodalny, dostrojony specjalnie do profesjonalnego inżynieringu oprogramowania, agentowego użycia narzędzi (tj. wywoływania i komponowania zewnętrznych narzędzi) oraz zadań polegających na korzystaniu z komputera. Zachowuje rozszerzone zdolności „extended-thinking” (transparentne, krok-po-kroku wewnętrzne rozumowanie, które można strumieniować) i dodaje precyzyjne kontrolki czasu wykonania (w szczególności parametr effort). Anthropic pozycjonuje ten model jako odpowiedni do agentów produkcyjnych, migracji/refaktoryzacji kodu i przepływów pracy w przedsiębiorstwach, które wymagają solidności i mniejszej liczby iteracji.
Core API capabilities and developer UX
Opus 4.5 obsługuje:
- Standardową generację tekstu + wysoką wierność wykonywania instrukcji.
- Tryby Extended Thinking / wieloetapowego rozumowania (przydatne do kodowania, długich dokumentów).
- Użycie narzędzi (wyszukiwanie w sieci, wykonywanie kodu, niestandardowe narzędzia), pamięć i cache’owanie podpowiedzi.
- „Claude Code” i przepływy agentowe (automatyzacja wieloetapowych zadań w kodbazach).
How does Claude Opus 4.5 perform?
Opus 4.5 jest stanem sztuki w benchmarkach inżynierii oprogramowania — deklaruje ~80,9% na SWE-bench Verified, a także mocne wyniki w benchmarkach „computer-use” takich jak OSWorld. Opus 4.5 potrafi dorównać lub przewyższać Sonnet 4.5 przy niższym zużyciu tokenów (tj. jest bardziej efektywny tokenowo).
Benchmarki inżynierskie (SWE-bench / Terminal Bench / Aider Polyglot): Anthropic raportuje, że Opus 4.5 prowadzi na SWE-bench Verified, poprawia Terminal Bench o ~15% względem Sonnet 4.5 i wykazuje +10,6% na Aider Polyglot w porównaniach wewnętrznych z Sonnet 4.5.
Długotrwałe, autonomiczne kodowanie: Anthropic: Opus 4.5 utrzymuje stabilną wydajność w 30-minutowych autonomicznych sesjach kodowania i rzadziej wpada w ślepe zaułki w wieloetapowych przepływach. To powtarzane wewnętrzne ustalenie z ich testów agentów.
Ulepszenia zadań w świecie rzeczywistym (Vending-Bench / BrowseComp-Plus itd.): Anthropic podaje +29% na Vending-Bench (zadania długohoryzontalne) względem Sonnet 4.5 oraz poprawę metryk wyszukiwania agentowego na BrowseComp-Plus.
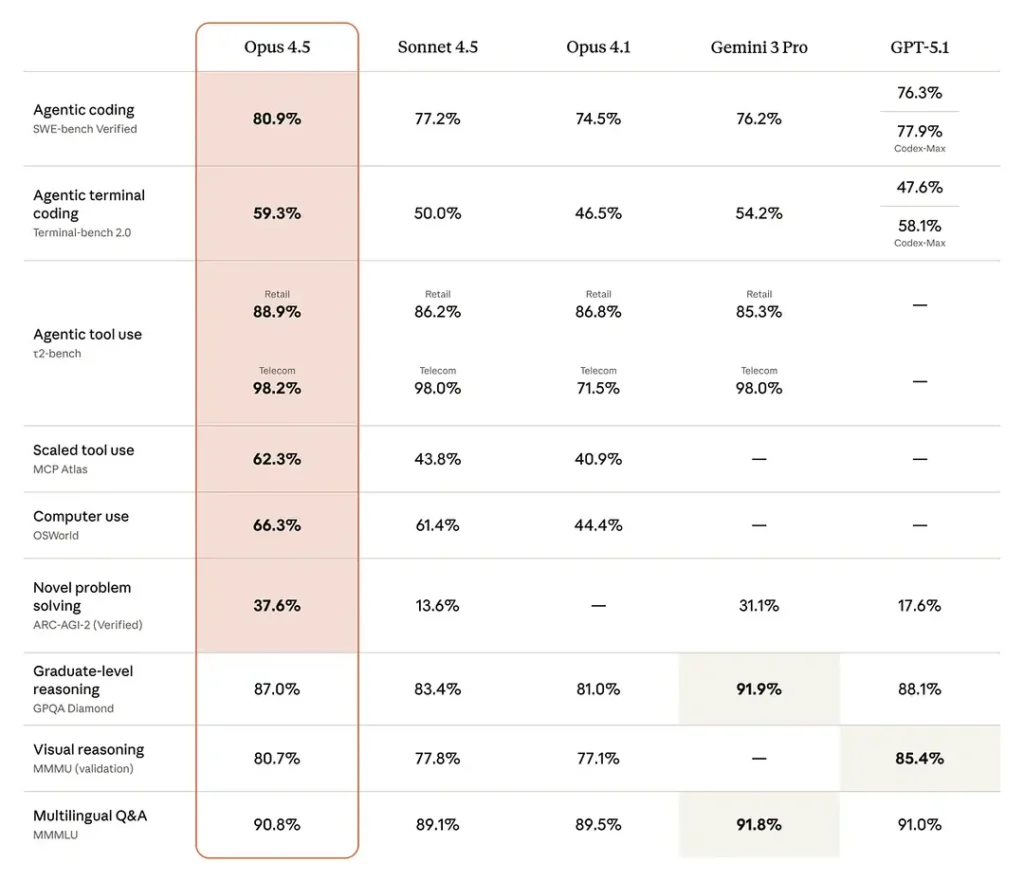
Kilka konkretnych wniosków z raportowania:
- Prowadzenie w kodowaniu: Opus 4.5 często pokonuje wcześniejsze warianty Opus/Sonnet i wiele ówczesnych modeli konkurencji w agregatach benchmarków inżynierii oprogramowania (SWE-bench Verified i warianty Terminal-bench).
- Automatyzacja biurowa: recenzenci podkreślają lepsze generowanie arkuszy kalkulacyjnych i tworzenie prezentacji PowerPoint — usprawnienia, które zmniejszają nakład pracy edycyjnej dla analityków i zespołów produktowych.
- Niezawodność agenta i narzędzi: Opus 4.5 poprawia działanie w wieloetapowych przepływach agentowych i przy długotrwałych zadaniach, zmniejszając liczbę niepowodzeń w potokach z wieloma wywołaniami.
How Much Does Claude Opus 4.5 Cost?
To centralne pytanie, które zadałeś. Poniżej rozbijam to na strukturę cen API, poziomy subskrypcji, przykładowe kalkulacje kosztów oraz co to oznacza w praktyce.
API Pricing Structure — what Anthropic published
Anthropic dla Opus 4.5 ustalił cenę API na:
- Wejście (tokeny): 5 USD za 1 000 000 tokenów wejściowych
- Wyjście (tokeny): 25 USD za 1 000 000 tokenów wyjściowych
Anthropic wyraźnie przedstawił tę cenę jako celową obniżkę, aby wydajność klasy Opus była szerzej dostępna. Identyfikator modelu dla deweloperów to łańcuch claude-opus-4-5-20251101.
W CometAPI, Claude Opus 4.5 API kosztuje 4 USD / 1M tokenów wejściowych i 20 USD / 1M tokenów wyjściowych dla Opus 4.5, około 20% taniej niż oficjalna cena Google.
Pricing table (simplified, USD per million tokens)
| Model | Input ($ / MTok) | Output ($ / MTok) | Notes |
|---|---|---|---|
| Claude Opus 4.5 (base) | $5.00 | $25.00 | Cena katalogowa Anthropic. |
| Claude Opus 4.1 | $15.00 | $75.00 | Starsze wydanie Opus — wyższe ceny katalogowe. |
| Claude Sonnet 4.5 | $3.00 | $15.00 | Tańsza rodzina do wielu zadań. |
Ważna uwaga: to są ceny oparte na tokenach (nie per-żądanie). Rozliczenie następuje na podstawie tokenów zużytych przez Twoje żądania — zarówno wejściowych (podpowiedź + kontekst), jak i wyjściowych (tokeny wygenerowane przez model).
Subscription plans and app tiers (consumer/Pro/Team)
API świetnie nadaje się do niestandardowych rozwiązań, podczas gdy plan subskrypcji Claude bundluje dostęp do Opus 4.5 z narzędziami UI, eliminując obawy o rozliczanie per-token w scenariuszach interaktywnych. Plan bezpłatny (0 USD) jest ograniczony do podstawowego czatu i modelu Haiku/Sonnet i nie zawiera Opus.
Plan Pro (20 USD miesięcznie lub 17 USD rocznie) oraz plan Max (100 USD za osobę miesięcznie, zapewniający 5–20 razy większe limity niż Pro) odblokowują Opus 4.5, Claude Code, wykonywanie plików i nielimitowane projekty.
How do I optimize token usage?
- Używaj
effortadekwatnie: wybierzlowdla rutynowych odpowiedzi,hightylko gdy to konieczne. - Preferuj strukturalne wyjścia i schematy, aby uniknąć rozwlekłej wymiany.
- Korzystaj z Files API, aby nie wysyłać ponownie dużych dokumentów w podpowiedzi.
- Kompaktuj lub streszczaj kontekst programowo przed wysłaniem.
- Zapisuj w pamięci podręcznej powtarzające się odpowiedzi i używaj ich, gdy podpowiedzi są identyczne lub podobne.
Praktyczna zasada: instrumentuj zużycie wcześnie (śledź tokeny na żądanie), wykonaj testy obciążeniowe z reprezentatywnymi podpowiedziami i licz koszt na udane zadanie (nie koszt na token), aby optymalizacje celowały w realny ROI.
Quick sample code: call Claude Opus 4.5 + compute cost
Poniżej gotowe do skopiowania przykłady: (1) curl, (2) Python z SDK Anthropic oraz (3) mały pomocnik w Pythonie, który liczy koszt na podstawie zmierzonych tokenów wejścia/wyjścia.
Ważne: przechowuj klucz API bezpiecznie w zmiennej środowiskowej. Przykłady zakładają, że ustawiono
ANTHROPIC_API_KEY. Użyty identyfikator modelu toclaude-opus-4-5-20251101(Anthropic).
1) cURL example (simple prompt)
curl https://api.anthropic.com/v1/complete \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model":"claude-opus-4-5-20251101",
"prompt":"You are an assistant. Given the following requirements produce a minimal Python function that validates emails. Return only code.",
"max_tokens": 600,
"temperature": 0.0
}'
2) Python (anthropic SDK) — basic request
# pip install anthropic
import os
from anthropic import Anthropic, HUMAN_PROMPT, AI_PROMPT
client = Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
prompt = HUMAN_PROMPT + "Given the following requirements produce a minimal Python function that validates emails. Return only code.\n\nRequirements:\n- Python 3.10\n- Use regex\n" + AI_PROMPT
resp = client.completions.create(
model="claude-opus-4-5-20251101",
prompt=prompt,
max_tokens_to_sample=600,
temperature=0.0
)
print(resp.completion) # model output
Uwaga: nazwy i sygnatury wywołań w Pythonowym SDK Anthropic mogą się różnić; powyżej zastosowano wzorce powszechne w ich publicznym SDK i dokumentacji — sprawdź dokumentację zainstalowanej wersji dla dokładnych nazw metod. GitHub+1
3) Cost calculator (Python) — compute cost from tokens
def compute_claude_cost(input_tokens, output_tokens,
input_price_per_m=5.0, output_price_per_m=25.0):
"""
Compute USD cost for Anthropic Opus 4.5 given token counts.
input_price_per_m and output_price_per_m are dollars per 1,000,000 tokens.
"""
cost_input = (input_tokens / 1_000_000) * input_price_per_m
cost_output = (output_tokens / 1_000_000) * output_price_per_m
return cost_input + cost_output
# Example: 20k input tokens and 5k output tokens
print(compute_claude_cost(20000, 5000)) # => ~0.225 USD
Wskazówka: mierz tokeny dla rzeczywistych żądań używając logów serwera / telemetrii dostawcy. Jeśli potrzebujesz dokładnego zliczania lokalnie, użyj tokenizera zgodnego ze schematem tokenizacji Claude lub polegaj na licznikach tokenów po stronie dostawcy, gdy są dostępne.
When should you choose Opus 4.5 vs cheaper models?
Używaj Opus 4.5, gdy:
- Masz krytyczne dla misji obciążenia inżynierskie, gdzie poprawność za pierwszym podejściem ma realną wartość (złożone generowanie kodu, sugestie architektoniczne, długie przebiegi agentowe).
- Zadania wymagają orkiestracji narzędzi lub głębokiego, wieloetapowego rozumowania w ramach jednego przepływu. Programowalne wywołania narzędzi to kluczowy wyróżnik.
- Chcesz ograniczyć pętle przeglądu przez człowieka — wyższa trafność pierwszej odpowiedzi może zmniejszyć czas pracy ludzi, a przez to całkowity koszt.
Rozważ Sonnet / Haiku lub modele konkurencji, gdy:
- Twój przypadek to gadatliwe, dużej skali, niskiego ryzyka streszczenia, gdzie liczą się tańsze tokeny i większa przepustowość. Sonnet (zbalansowany) lub Haiku (lekki) mogą być bardziej opłacalne.
- Potrzebujesz najniższego kosztu per-token i akceptujesz kompromisy w zakresie możliwości/dokładności (np. proste streszczenia, podstawowi asystenci).
How should I design prompts for Opus 4.5?
Jakie role wiadomości i strategie prefill działają najlepiej?
Użyj wzorca trzyczęściowego:
- System (rola: system): globalne instrukcje — ton, ograniczenia, rola.
- Assistant (opcjonalnie): gotowe przykłady lub treści „priming”.
- User (rola: user): bieżące żądanie.
Wypełnij wiadomość systemową ograniczeniami (format, długość, polityka bezpieczeństwa, schemat JSON, jeśli chcesz wyjścia strukturalne). Dla agentów dołącz specyfikacje narzędzi i przykłady użycia, aby Opus 4.5 mógł poprawnie je wywoływać.
Jak używać kompakcji kontekstu i cache’owania podpowiedzi, by oszczędzać tokeny?
- Kompakcja kontekstu: skondensuj starsze części rozmowy do zwięzłych podsumowań, które model wciąż może wykorzystać. Opus 4.5 wspiera automatyzację kompakcji kontekstu bez utraty kluczowych bloków rozumowania.
- Cache’owanie podpowiedzi: zapisuj odpowiedzi modelu dla powtarzających się podpowiedzi (Anthropic udostępnia wzorce cache’owania podpowiedzi, aby zmniejszyć opóźnienie/koszt).
Obie funkcje redukują ślad tokenowy długich interakcji i są zalecane dla długotrwałych przepływów agentowych i asystentów produkcyjnych.
Best Practices: Getting Opus-level results while controlling cost
1) Optymalizuj podpowiedzi i kontekst
- Minimalizuj zbędny kontekst — wysyłaj tylko potrzebną historię. Przy długiej wymianie przycinaj i streszczaj wcześniejszą rozmowę.
- Używaj retrieval/embedding + RAG, by pobierać tylko dokumenty potrzebne do konkretnego zapytania (zamiast wysyłać całe korpusy jako tokeny podpowiedzi). Dokumentacja Anthropic zaleca RAG i cache’owanie podpowiedzi, by zmniejszyć wydatki tokenowe.
2) Buforuj i używaj ponownie odpowiedzi, gdzie to możliwe
Cache’owanie podpowiedzi: jeśli wiele żądań ma identyczne lub niemal identyczne podpowiedzi, zapisuj wyjścia i serwuj wersje z pamięci podręcznej zamiast ponownie wywoływać model za każdym razem. Dokumenty Anthropic wyraźnie wskazują cache’owanie podpowiedzi jako optymalizację kosztową.
3) Dobierz właściwy model do zadania
- Używaj Opus 4.5 do zadań krytycznych, wysokowartościowych, gdzie koszt pracy ludzkiej jest wysoki.
- Używaj Sonnet 4.5 albo Haiku 4.5 do zadań dużej skali i niższego ryzyka. Taka mieszana strategia modeli daje lepszy stosunek ceny do wydajności w całym stosie.
4) Kontroluj maksymalną liczbę tokenów i strumieniowanie
Ogranicz max_tokens_to_sample dla wyjść, gdy nie potrzebujesz pełnej rozwlekłości. Korzystaj ze strumieniowania tam, gdzie jest wspierane, aby wcześniej zatrzymywać generację i oszczędzać tokeny wyjściowe.
Final thoughts: is Opus 4.5 worth adopting now?
Opus 4.5 to istotny krok naprzód dla organizacji, które potrzebują rozumowania o wyższej wierności, niższych kosztów tokenów przy długich interakcjach oraz bezpieczniejszego, bardziej odpornego zachowania agentów. Jeśli Twój produkt opiera się na utrzymanym rozumowaniu (złożone zadania kodowe, autonomiczni agenci, głęboka synteza badań lub intensywna automatyzacja w Excelu), Opus 4.5 daje dodatkowe pokrętła (effort, extended thinking, ulepszoną obsługę narzędzi), by dostroić go do wydajności i kosztów w świecie rzeczywistym.
Deweloperzy mogą uzyskać dostęp do Claude Opus 4.5 API przez CometAPI. Aby zacząć, poznaj możliwości modelu CometAPI w Playground i zapoznaj się z przewodnikiem API po szczegółowe instrukcje. Przed skorzystaniem upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby ułatwić integrację.
Gotowi do działania?→ Zarejestruj się w CometAPI już dziś!
Jeśli chcesz więcej wskazówek, przewodników i nowości o AI, obserwuj nas na VK, X i Discord!