

Chińska firma Z.ai (dawniej Zhipu AI) ponownie trafiła na pierwsze strony gazet dzięki premierze swojej serii GLM 4.5 opartej na otwartym kodzie źródłowym. Pozycjonowana jako ekonomiczna i wydajna alternatywa dla istniejących modeli wielojęzykowych, GLM‑4.5 obiecuje przekształcić ekonomię tokenów i zdemokratyzować dostęp do nich dla startupów, przedsiębiorstw i instytucji badawczych. Ten obszerny artykuł analizuje genezę serii GLM‑4.5, jej strukturę cenową i realną wartość – odpowiadając na dwa kluczowe pytania, które nurtują każdego interesariusza: ile to kosztuje i czy jest tego warte?
Czym jest seria GLM 4.5?
Seria GLM 4.5 firmy Z.ai opiera się na „agencyjnym” frameworku sztucznej inteligencji (AI), co oznacza, że model może autonomicznie rozkładać złożone zadania na mniejsze, sekwencyjne podzadania – zwiększając precyzję i redukując zbędne obliczenia. Stanowi to kontrast z bardziej monolitycznymi modelami LLM, które obsługują monity w jednym przebiegu. Według Z.ai, GLM 4.5 natywnie osadza wnioskowanie i planowanie działań w swojej podstawowej architekturze, umożliwiając wieloetapowe przepływy pracy, takie jak generowanie wizualizacji danych czy kompleksowe przetwarzanie dokumentów, bez zewnętrznej koordynacji.
Seria GLM 4.5, opracowana przez Z.ai, reprezentuje najnowszą generację dużych modeli językowych typu Mixture-of-Experts (MoE) o otwartym kodzie źródłowym, zaprojektowanych w celu ujednolicenia zaawansowanego wnioskowania, generowania kodu i możliwości agentów w ramach jednej architektury. Dostępna jest w dwóch głównych wersjach: flagowej GLM 4.5 (355 B parametrów całkowitych, 32 B aktywnych) i lżejszy GLM 4.5‑Air (łącznie 106 B, 12 B aktywnych). Oba warianty wykorzystują hybrydowy mechanizm wnioskowania – „tryb myślenia” do złożonego rozumowania wspomaganego narzędziami oraz „tryb bez myślenia” do szybkiego i prostego uzupełniania – obsługując szerokie spektrum przypadków użycia, od pełnego stosu oprogramowania po autonomiczne przepływy pracy agentów.
podstawowe specyfikacje techniczne:
- Parametry:GLM 4.5 obsługuje 355 miliardów parametrów, przy czym na każde wnioskowanie przypada 32 miliardy aktywnych parametrów, co pozwala zoptymalizować wykorzystanie sprzętu i przepustowość.
- **Mieszanina Ekspertów (MoE)**Seria wykorzystuje architekturę MoE, dynamicznie kierując tokeny do podsieci eksperckich w celu zwiększenia wydajności.
- Okno kontekstowe:Rozszerzone do 128 tys. tokenów na wybranych platformach (np. SiliconFlow), co umożliwia obsługę dużych dokumentów i baz kodów.
- Szybkość generacji:Wersje o dużej prędkości przekraczają 100 tokenów na sekundę, co czyni je odpowiednimi do zastosowań w czasie rzeczywistym.
- Hybrydowe tryby wnioskowaniaUżytkownicy mogą przełączać się między trybem „myślenia” (pełna aktywacja MoE w celu głębokiego rozumowania) i trybem „bez myślenia” (minimalna aktywacja w celu szybkich, natychmiastowych odpowiedzi), co daje twórcom oprogramowania szczegółową kontrolę nad wydajnością i szybkością.
Jakie warianty istnieją w ramach serii?
- GLM 4.5 (Standard): 355 B łącznie / 32 B aktywnych parametrów. Zaprojektowane głównie z myślą o zrównoważonej wydajności w zadaniach rozumowania, kodowania i agentów.
- GLM 4.5‑Air:Lekka wersja o parametrach całkowitych 106 B / aktywnych 12 B, dostosowana do scenariuszy z rygorystycznymi ograniczeniami sprzętowymi lub opóźnieniami, zapewniająca konkurencyjną dokładność w swojej klasie.
Ile kosztuje seria GLM 4.5?
Jakie są ceny tokenów wejściowych i wyjściowych?
Zgodnie z publicznymi informacjami cenowymi API ujawnionymi przez Z.ai, cena GLM 4.5 wynosi:
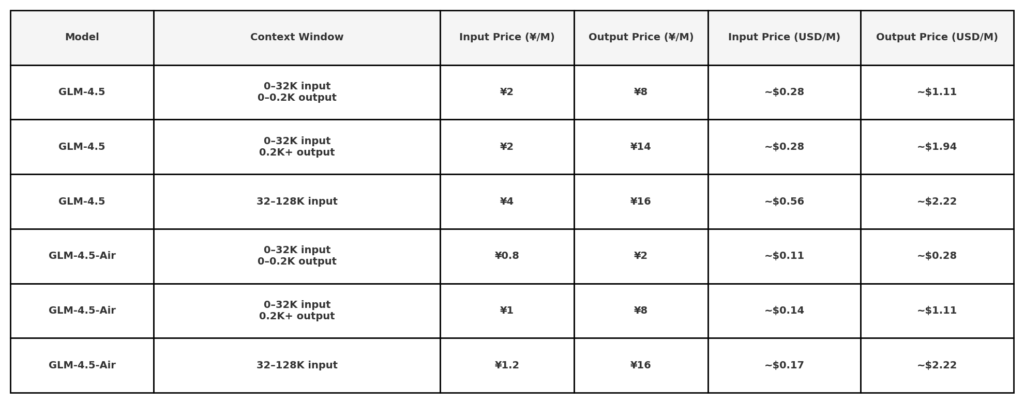
Uwaga: bardzo niskie stawki (0.11 USD/0.28 USD) mogą być ograniczone do krótkich serii tokenów lub określonych promocji. 50% zniżki na wszystkie modele przez ograniczony czas, ważna do 31 sierpnia 2025 r. Inne modele patrz strona z cenami biurowymi.
W przypadku CometAPI seria jest oferowana w ramach nieco innych poziomów cenowych, patrz Interfejs API GLM‑4.5:
| Model | przedstawiać | Cena |
glm-4.5 | Nasz najpotężniejszy model wnioskowania z 355 miliardami parametrów | Tokeny wejściowe 0.48 USD Tokeny wyjściowe 1.92 USD |
glm-4.5-air | Ekonomiczny, lekki, o dużej wydajności | Tokeny wejściowe 0.16 USD Tokeny wyjściowe 1.07 USD |
glm-4.5-x | Wysoka wydajność, silne rozumowanie, ultraszybka reakcja | Tokeny wejściowe 1.60 USD Tokeny wyjściowe 6.40 USD |
glm-4.5-airx | Lekka, wytrzymała, ultraszybka reakcja | Tokeny wejściowe 0.02 USD Tokeny wyjściowe 0.06 USD |
glm-4.5-flash | Wysoka wydajność, doskonała do kodowania wnioskowania i agentów | Tokeny wejściowe 3.20 USD Tokeny wyjściowe 12.80 USD |
Jak ceny GLM 4.5 wypadają w porównaniu z DeepSeek i Western LLM?
Podczas konferencji World AI Conference 2025 firma Z.ai wyraźnie przedstawiła GLM 4.5 jako konkurenta dla DeepSeek — poprzedniego lidera pod względem kosztów w Chinach — obiecując „ułamek kosztów tokena” i połowę sprzętu zajmującego powierzchnię użytkową modelu R1 firmy DeepSeek.
- Głębokie wyszukiwanie R1:Około 0.14 USD na wejściu i 0.60 USD na wyjściu na milion tokenów.
- GLM 4.5:Twierdzono, że obniża wydajność DeepSeek o 20–30% zarówno na wejściu, jak i wyjściu.
- Zachodnie standardy:GPT‑4 firmy OpenAI i Gemini firmy Google kosztują od 3 do 15 USD za milion tokenów, co plasuje GLM 4.5 jako redukcję kosztów o rząd wielkości.
Ta strategia cenowa odzwierciedla szerszy chiński model ekonomiczny oparty na sztucznej inteligencji: bardziej wydajne przetwarzanie, mniejsze modele i agresywna walka o zaniżanie cen w celu zdobycia udziału w rynku.
Czy seria GLM 4.5 jest warta swojej ceny?
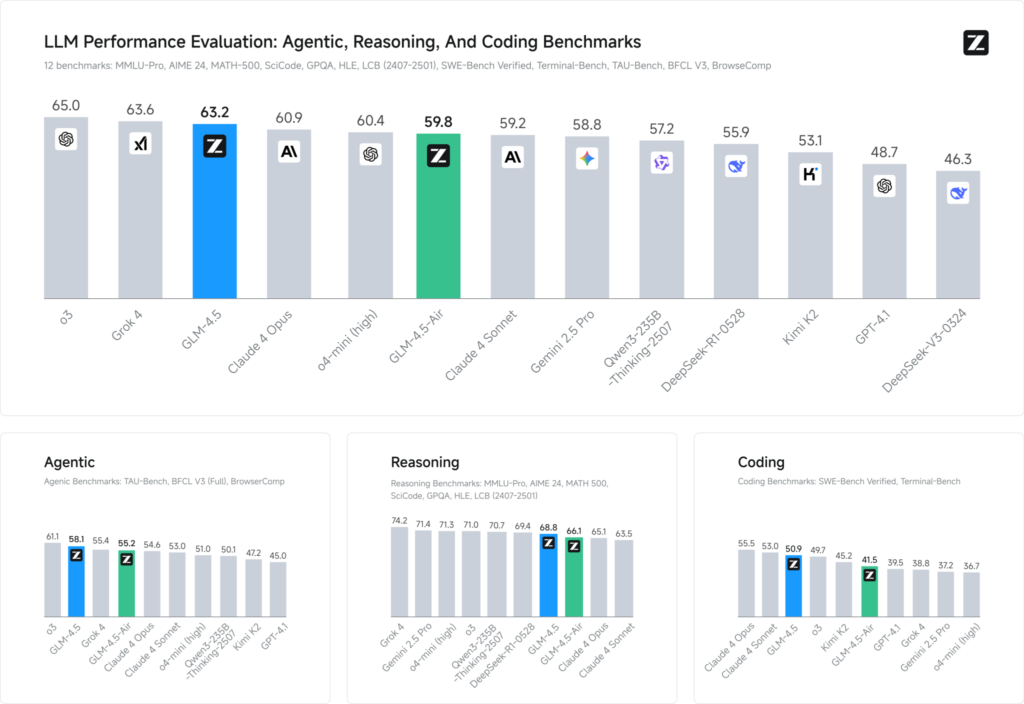
Oceny porównawcze przeprowadzone na 12 reprezentatywnych zestawach danych (obejmujących MMLU Pro, MATH 500, SciCode, Terminal‑Bench i TAU‑Bench) ujawniają, że GLM 4.5 zajmuje 3. miejsce w światowym rankingu, za Grok 4 firmy xAI i o3 firmy OpenAI — a jednocześnie zajmuje 1. miejsce wśród ofert open source.
W zadaniach kodowania (LiveCodeBench, SWE‑Bench), konstrukcja Mixture‑of‑Experts w GLM 4.5 przyczynia się do najwyższej jakości generowania kodu, a w wnioskowaniu (AIME 24, MMLU Pro) wieloetapowe planowanie zapewnia wysoką dokładność porównywalną z odpowiednikami o zamkniętym kodzie źródłowym. Lekka wersja Air utrzymuje konkurencyjne wyniki w swoim przedziale parametrów (skala 100 B), co czyni ją kuszącym wyborem dla wdrożeń brzegowych i systemów wbudowanych.
Benchmarki wydajności
- Indeks inteligencji:Wyniki GLM 4.5 66 w złożonym indeksie inteligencji (MMLU Pro, MATH 500, AIME 24), wyprzedzając wiele modeli open-source i komercyjnych średniej klasy.
- Opóźnienie wnioskowania: Średni czas do pierwszego tokena 0.89 sekund, konkurencyjny w przypadku złożonych zadań wymagających rozumowania, choć jego przepustowość jest nieco wolniejsza (≈45.7 tokenów/s) w porównaniu do niektórych zoptymalizowanych modeli o zamkniętym kodzie źródłowym.
- Przepływ pracy agenta:Wykazuje solidną znajomość wieloetapowego korzystania z narzędzi i dynamicznego generowania kodu, osiągając wskaźnik wygranych w bezpośrednich pojedynkach na poziomie ~54% przeciwko Kimi K2 oraz 81% przeciwko Qwen3‑Coder w niezależnych ocenach kodowania.
Jakie praktyczne przypadki użycia pokazują zwrot z inwestycji?
- Rozwój pełnego stosu:GLM‑4.5 może tworzyć szkielety całych aplikacji internetowych — od układów front-end w HTML/CSS/JavaScript po schematy baz danych back-end — poprzez wieloetapowe monity, co skraca cykle prototypowania z dni do godzin.
- Złożona analiza dokumentówRozszerzone okno kontekstowe o pojemności 128 KB pozwala firmom prawniczym, finansowym i naukowym analizować wielostronicowe umowy lub raporty badawcze na raz, zmniejszając tym samym obciążenie związane z segmentacją.
- Zautomatyzowane przepływy pracy agentów:Wnioskowanie hybrydowe pozwala na tworzenie autonomicznych skryptów (np. botów do scrapowania stron internetowych, agentów handlowych), które rozumują na podstawie wieloetapowych procesów z minimalną ingerencją człowieka.
Studia przypadków ilościowych sugerują do 60 procent skrócenie czasu pracy programistów w przypadku zadań skoncentrowanych na kodzie i 40 procent szybsze przetwarzanie analiz treści w formie dłuższej.
Jakie są potencjalne wady i kwestie do rozważenia?
Żadna technologia nie jest pozbawiona kompromisów. Potencjalni użytkownicy powinni być świadomi czynników regulacyjnych, operacyjnych i ekosystemowych.
Ograniczenia
Wsparcie i umowy SLA:Dostawcy oprogramowania typu open source mogą nie oferować umów SLA na poziomie korporacyjnym ani całodobowego wsparcia, w przeciwieństwie do odpowiedników komercyjnych.
Ograniczenia przepustowości:Chociaż okno kontekstowe jest ogromne, szybkość przetwarzania tokenów na sekundę jest niższa niż w przypadku niektórych odpowiedników o zamkniętym kodzie źródłowym zoptymalizowanych pod kątem wnioskowania, co może mieć wpływ na aplikacje czasu rzeczywistego.
Koszty operacyjne:Modele MoE z własnym hostingiem wymagają starannej organizacji (eksperckie trasowanie, zarządzanie pamięcią), aby uniknąć wąskich gardeł wydajnościowych i przekroczenia kosztów.
Jakie inwestycje infrastrukturalne są wymagane?
- Zasięg obliczeniowy: Nawet przy zachowaniu wydajności MoE, hosting standardowej wersji GLM‑4.5 wymaga procesorów GPU z pamięcią ≥80 GB i solidnych połączeń NVLink w celu zapewnienia wnioskowania o niskim opóźnieniu.
- Dokładne dostrajanie kosztów ogólnych: Dostosowanie modelu do zadań specyficznych dla danej domeny może wymagać znacznych cykli GPU, co zwiększa koszty początkowe, zanim oszczędności wynikające z rozliczeń za pomocą tokenów staną się realne.
- Konserwacja: Wdrożenia lokalne przenoszą odpowiedzialność za aktualizacje, poprawki zabezpieczeń i skalowanie z dostawcy na wewnętrzne zespoły DevOps.
Jak rozpocząć pracę z GLM‑4.5?
Rozpoczęcie integracji GLM‑4.5 wymaga wykonania kilku prostych kroków — szczególnie biorąc pod uwagę podręcznik open source i szerokie wsparcie ze strony podmiotów zewnętrznych.
Które interfejsy API i platformy obsługują GLM‑4.5?
- Interfejs API Comet API: W pełni zgodny z OpenAI punkt końcowy, zawierający zestawy SDK w językach Python, JavaScript i Java.
- Bezpośredni punkt końcowy Z.ai: Oferuje oficjalne wsparcie i funkcje wczesnego dostępu, takie jak koordynacja wielu agentów.
- Lustra społecznościowe: Szybko rozwijająca się liczba środowisk wykonawczych typu open source (np. Ollama, AutoGPT‑CLI), które umożliwiają wnioskowanie lokalne.
Gdzie programiści mogą znaleźć narzędzia i dokumentację?
- Oficjalna dokumentacja Z.ai: Kompleksowe przewodniki dotyczące instalacji, szybkiego projektowania i optymalizacji MoE.
- Repozytoria GitHub: Przykładowe notatniki do generowania kodu, generowania z wykorzystaniem funkcji pobierania rozszerzonego (RAG) oraz struktury agentów zgodne z głównymi narzędziami do orkiestracji.
- Fora społecznościowe: Aktywne fora dyskusyjne na platformach takich jak Hugging Face, gdzie praktycy dzielą się przepisami na udoskonalenie swoich produktów, bibliotekami podpowiedzi i testami wydajności.
Podsumowanie
Seria GLM‑4.5 śmiało stawia czoła dzisiejszemu, niezwykle konkurencyjnemu środowisku sztucznej inteligencji: niezrównana relacja ceny do wydajności dla deweloperów, przedsiębiorstw i instytucji badawczych. Dzięki cenom tokenów już od 0.11 USD za milion tokenów wejściowych i 0.28 USD za milion tokenów wyjściowych – dodatkowo obniżonym o 50% zniżką promocyjną – oraz wydajności porównywalnej z większymi, zastrzeżonymi modelami, a nawet je przewyższającej, GLM‑4.5 zapewnia znaczny zwrot z inwestycji (ROI) w aplikacje oparte na kodzie, zrozumienie długich formularzy i przepływy pracy oparte na agentach.
Jak zacząć
CometAPI to ujednolicona platforma API, która agreguje ponad 500 modeli AI od wiodących dostawców — takich jak seria GPT firmy OpenAI, Gemini firmy Google, Claude firmy Anthropic, Midjourney, Suno i innych — w jednym, przyjaznym dla programistów interfejsie. Oferując spójne uwierzytelnianie, formatowanie żądań i obsługę odpowiedzi, CometAPI radykalnie upraszcza integrację możliwości AI z aplikacjami. Niezależnie od tego, czy tworzysz chatboty, generatory obrazów, kompozytorów muzycznych czy oparte na danych potoki analityczne, CometAPI pozwala Ci szybciej iterować, kontrolować koszty i pozostać niezależnym od dostawcy — wszystko to przy jednoczesnym korzystaniu z najnowszych przełomów w ekosystemie AI.
Deweloperzy mogą uzyskać dostęp GLM-4.5 Air API oraz Interfejs API GLM‑4.5 przez Interfejs API CometNajnowsza wersja Claude Models podana jest na dzień publikacji artykułu. Na początek zapoznaj się z możliwościami modelu w… Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. Interfejs API Comet zaoferuj cenę znacznie niższą niż oficjalna, aby ułatwić Ci integrację.