

Rozpoczęcie pracy z Gemini 2.5 Flash-Lite za pośrednictwem CometAPI to ekscytująca okazja do wykorzystania jednego z najbardziej ekonomicznych, nisko-opóźnieniowych modeli generatywnej AI dostępnych obecnie na rynku. Ten przewodnik łączy najnowsze ogłoszenia Google DeepMind, szczegółowe specyfikacje z dokumentacji Vertex AI oraz praktyczne kroki integracji przy użyciu CometAPI, aby pomóc Ci szybko i skutecznie rozpocząć pracę.
Czym jest Gemini 2.5 Flash-Lite i dlaczego warto go rozważyć?
Przegląd rodziny Gemini 2.5
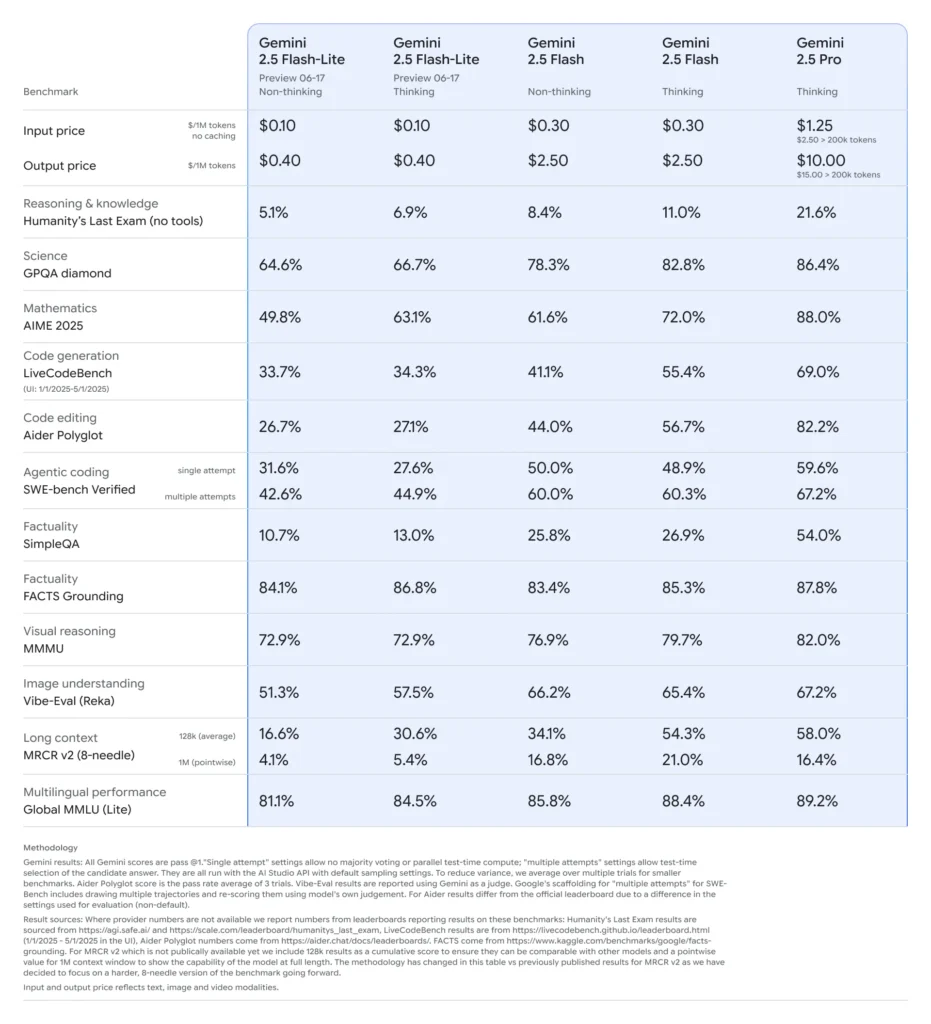
W połowie czerwca 2025 r. Google DeepMind oficjalnie wydało serię Gemini 2.5, w tym stabilne wersje GA Gemini 2.5 Pro i Gemini 2.5 Flash, a także wersję zapoznawczą zupełnie nowego, lekkiego modelu: Gemini 2.5 Flash-Lite. Seria 2.5, zaprojektowana z myślą o zrównoważeniu szybkości, kosztów i wydajności, reprezentuje dążenie Google do obsługi szerokiego spektrum przypadków użycia — od ciężkich obciążeń badawczych po wdrożenia na dużą skalę i wrażliwe na koszty.
Kluczowe cechy Flash-Lite
Flash-Lite wyróżnia się tym, że oferuje multimodalne możliwości (tekst, obrazy, dźwięk, wideo) przy ekstremalnie niskim opóźnieniu, z oknem kontekstowym obsługującym do miliona tokenów i integracją narzędzi, w tym wyszukiwarką Google, wykonywaniem kodu i wywoływaniem funkcji. Co najważniejsze, Flash-Lite wprowadza kontrolę „budżetu myśli”, umożliwiającą programistom kompromis między głębokością rozumowania a czasem reakcji i kosztem poprzez dostosowanie wewnętrznego parametru budżetu tokenów.
Pozycjonowanie w ofercie modeli
W porównaniu do swoich odpowiedników Flash-Lite znajduje się na granicy Pareto efektywności kosztowej: wyceniony na około 0.10 USD za milion tokenów wejściowych i 0.40 USD za milion tokenów wyjściowych w wersji zapoznawczej, podbija Flash (za 0.30 USD/2.50 USD) i Pro (za 1.25 USD/10 USD), zachowując jednocześnie większość ich multimodalnych możliwości i obsługi wywołań funkcji. Dzięki temu Flash-Lite idealnie nadaje się do zadań o dużej objętości i niskiej złożoności, takich jak podsumowywanie, klasyfikacja i lekkie agenci konwersacyjni.
Dlaczego deweloperzy powinni rozważyć Gemini 2.5 Flash-Lite?
Testy wydajności i testy w warunkach rzeczywistych
W bezpośrednim porównaniu Flash-Lite wykazał:
- 2x szybsza przepustowość niż Gemini 2.5 Flash w zadaniach klasyfikacyjnych.
- 3-krotna oszczędność kosztów do podsumowań procesów na skalę przedsiębiorstwa.
- Konkurencyjna dokładność pod kątem logiki, matematyki i testów kodu, dorównując lub przewyższając wcześniejsze wersje zapoznawcze Flash-Lite.
Idealne przypadki użycia
- Chatboty o dużej objętości: Zapewnij spójne, charakteryzujące się niskim opóźnieniem środowisko konwersacyjne milionom użytkowników.
- Automatyczne generowanie treści:Podsumowanie dokumentu na dużą skalę, tłumaczenie i tworzenie mikrokopie.
- Kanały wyszukiwania i rekomendacji:Wykorzystaj szybkie wnioskowanie do personalizacji w czasie rzeczywistym.
- Przetwarzanie danych wsadowych:Adnotacje do dużych zbiorów danych przy minimalnych kosztach obliczeniowych.
W jaki sposób uzyskać i zarządzać dostępem do API dla Gemini 2.5 Flash-Lite poprzez CometAPI?
Dlaczego warto używać CometAPI jako bramki komunikacyjnej?
CometAPI agreguje ponad 500 modeli AI — w tym serię Gemini firmy Google — w ramach ujednoliconego punktu końcowego REST, co upraszcza uwierzytelnianie, ograniczanie szybkości i rozliczanie u różnych dostawców. Zamiast żonglować wieloma bazowymi adresami URL i kluczami API, kierujesz wszystkie żądania do https://api.cometapi.com/v1, określ model docelowy w ładunku i zarządzaj wykorzystaniem za pośrednictwem jednego pulpitu nawigacyjnego.
Wymagania wstępne i rejestracja
- Zaloguj się do pl.com. Jeśli jeszcze nie jesteś naszym użytkownikiem, zarejestruj się najpierw
- Pobierz klucz API uwierzytelniania dostępu do interfejsu. Kliknij „Dodaj token” przy tokenie API w centrum osobistym, pobierz klucz tokena: sk-xxxxx i prześlij.
- Uzyskaj adres URL tej witryny: https://api.cometapi.com/
Zarządzanie tokenami i limitami
Panel CometAPI zapewnia ujednolicone limity tokenów, które można udostępniać w modelach Google, OpenAI, Anthropic i innych. Użyj wbudowanych narzędzi monitorujących, aby ustawić alerty dotyczące wykorzystania i limity stawek, dzięki czemu nigdy nie przekroczysz budżetowanych alokacji ani nie poniesiesz nieoczekiwanych opłat.
Jak skonfigurować środowisko programistyczne pod kątem integracji CometAPI?
Instalowanie wymaganych zależności
Aby przeprowadzić integrację z Pythonem, zainstaluj następujące pakiety:
pip install openai requests pillow
- openai:Zgodny zestaw SDK do komunikacji z CometAPI.
- wywołań: Do operacji HTTP, takich jak pobieranie obrazów.
- poduszka:Do obsługi obrazu podczas wysyłania danych multimodalnych.
Inicjalizacja klienta CometAPI
Użyj zmiennych środowiskowych, aby nie umieszczać klucza API w kodzie źródłowym:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Ta instancja klienta może teraz kierować się do dowolnego obsługiwanego modelu, określając jego identyfikator (np. gemini-2.5-flash-lite-preview-06-17) w swoich prośbach.
Konfigurowanie budżetu myśli i innych parametrów
Wysyłając zapytanie możesz uwzględnić parametry opcjonalne:
- temperatura/top_p:Kontrola losowości w generowaniu.
- liczba kandydatów:Liczba alternatywnych wyjść.
- max_tokens: Limit tokenów wyjściowych.
- budżet_myślowy:Parametr niestandardowy dla Flash-Lite umożliwiający kompromis między głębokością a szybkością i ceną.
Jak wygląda podstawowe żądanie do Gemini 2.5 Flash-Lite poprzez CometAPI?
Przykład tylko tekstowy
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
To wywołanie zwraca zwięzłe podsumowanie w czasie krótszym niż 200 ms, co jest idealnym rozwiązaniem dla chatbotów lub procesów analitycznych w czasie rzeczywistym.
Przykład wejścia multimodalnego
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Program Flash-Lite przetwarza obrazy o rozmiarze do 7 MB i zwraca opisy kontekstowe, dzięki czemu nadaje się do zrozumienia dokumentu, analizy interfejsu użytkownika i automatycznego tworzenia raportów.
W jaki sposób można wykorzystać zaawansowane funkcje, takie jak przesyłanie strumieniowe i wywoływanie funkcji?
Odpowiedzi strumieniowe dla aplikacji w czasie rzeczywistym
W przypadku interfejsów chatbotów lub napisów na żywo należy skorzystać z interfejsu API przesyłania strumieniowego:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Dzięki temu częściowe wyniki są generowane w miarę ich udostępniania, co zmniejsza odczuwalne opóźnienie w interaktywnych interfejsach użytkownika.
Funkcja wywołująca w celu uzyskania ustrukturyzowanego wyjścia danych
Zdefiniuj schematy JSON, aby wymusić ustrukturyzowane odpowiedzi:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Takie podejście gwarantuje zgodność wyników z formatem JSON, upraszczając dalsze procesy przetwarzania danych i integracje.
Jak zoptymalizować wydajność, koszty i niezawodność podczas korzystania z Gemini 2.5 Flash-Lite?
Myślenie o dostrajaniu budżetu
Parametr budżetu myślowego Flash-Lite pozwala Ci wybrać ilość „wysiłku poznawczego”, jaki model wydaje. Niski budżet (np. 0) priorytetowo traktuje szybkość i koszt, podczas gdy wyższe wartości dają głębsze rozumowanie kosztem opóźnienia i tokenów.
Zarządzanie limitami tokenów i przepustowością
- Tokeny wejściowe:Do 1,048,576 XNUMX XNUMX tokenów na żądanie.
- Tokeny wyjściowe: Domyślny limit wynosi 65,536 XNUMX tokenów.
- Wejścia multimodalne:Do 500 MB na zasoby graficzne, audio i wideo.
Wdrażaj przetwarzanie wsadowe po stronie klienta w przypadku obciążeń o dużej objętości i korzystaj z funkcji automatycznego skalowania CometAPI, aby poradzić sobie ze wzmożonym ruchem bez konieczności ręcznej interwencji.
Strategie efektywności kosztowej
- Grupuj zadania o niskiej złożoności w programie Flash-Lite, rezerwując wersję Pro lub standardową programu Flash do zadań wymagających większej złożoności.
- Użyj limitów stawek i alertów budżetowych w panelu CometAPI, aby zapobiec niekontrolowanemu wydatkowi.
- Monitoruj wykorzystanie według identyfikatora modelu, aby porównywać koszty na żądanie i odpowiednio dostosowywać logikę routingu.
Jakie są najlepsze praktyki i kolejne kroki po wstępnej integracji?
Monitorowanie, rejestrowanie i bezpieczeństwo
- Logowanie:Przechwytywanie metadanych żądań/odpowiedzi (znaczników czasu, opóźnień, wykorzystania tokenów) na potrzeby audytów wydajności.
- Alarmy: Skonfiguruj powiadomienia progowe dotyczące wskaźników błędów lub przekroczeń kosztów w CometAPI.
- Ochrona:Regularnie wymieniaj klucze API i przechowuj je w bezpiecznych sejfach lub zmiennych środowiskowych.
Typowe wzorce użytkowania
- Chatbots:Używaj Flash-Lite do szybkich zapytań użytkowników i korzystaj z wersji Pro do bardziej złożonych działań następczych.
- Przetwarzanie dokumentów:Analizy obrazów i plików PDF w partiach, w ciągu nocy, przy niższym budżecie.
- Analityka w czasie rzeczywistym:Przesyłaj strumieniowo dane finansowe i operacyjne, aby uzyskać natychmiastowy wgląd za pomocą interfejsu API przesyłania strumieniowego.
Odkrywanie dalej
- Eksperymentuj z hybrydowym systemem podpowiedzi: łącz tekst i obrazy, aby uzyskać bogatszy kontekst.
- Prototyp RAG (Retrieval-Augmented Generation) dzięki integracji narzędzi do wyszukiwania wektorowego z Gemini 2.5 Flash-Lite.
- Przeprowadź porównanie z ofertami konkurencji (np. GPT-4.1, Claude Sonnet 4), aby sprawdzić kompromis między kosztami i wydajnością.
Skalowanie w produkcji
- Wykorzystaj korporacyjną wersję CometAPI, aby uzyskać dedykowane pule kwot i gwarancje SLA.
- Wdrażaj strategie wdrażania niebiesko-zielone, aby testować nowe monity lub budżety bez zakłócania pracy użytkowników na żywo.
- Regularnie przeglądaj wskaźniki wykorzystania modelu, aby identyfikować możliwości dalszych oszczędności kosztów lub poprawy jakości.
Jak zacząć
CometAPI zapewnia ujednolicony interfejs REST, który agreguje setki modeli AI — w ramach spójnego punktu końcowego, z wbudowanym zarządzaniem kluczami API, limitami wykorzystania i panelami rozliczeniowymi. Zamiast żonglować wieloma adresami URL dostawców i poświadczeniami.
Deweloperzy mogą uzyskać dostęp Gemini 2.5 Flash-Lite (wersja zapoznawcza) API(Model: gemini-2.5-flash-lite-preview-06-17) Poprzez Interfejs API Comet, najnowsze wymienione modele są z dnia publikacji artykułu. Na początek zapoznaj się z możliwościami modelu w Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. Interfejs API Comet zaoferuj cenę znacznie niższą niż oficjalna, aby ułatwić Ci integrację.
W zaledwie kilku krokach możesz zintegrować Gemini 2.5 Flash-Lite za pośrednictwem CometAPI ze swoimi aplikacjami, odblokowując potężne połączenie szybkości, przystępności cenowej i multimodalnej inteligencji. Postępując zgodnie z powyższymi wytycznymi — obejmującymi konfigurację, podstawowe żądania, zaawansowane funkcje i optymalizację — będziesz w dobrej pozycji, aby dostarczać użytkownikom doświadczenia AI nowej generacji. Przyszłość wydajnej kosztowo, wysokoprzepustowej AI jest już tutaj: zacznij korzystać z Gemini 2.5 Flash-Lite już dziś.