

DeepSeek-V3.1 to najnowszy hybrydowy model wnioskowania firmy DeepSeek, który obsługuje zarówno szybki tryb czatu „bez myślenia”, jak i bardziej przemyślany tryb „myślenie/rozumowanie”. Oferuje długi (do 128 KB) kontekst, ustrukturyzowane wyniki i wywołania funkcji. Dostęp do niego jest możliwy bezpośrednio za pośrednictwem API DeepSeek zgodnego z OpenAI, punktu końcowego zgodnego z Anthropic lub przez CometAPI. Poniżej przedstawiam istotę modelu, najważniejsze wyniki testów porównawczych i koszty, zaawansowane funkcje (wywoływanie funkcji, wyniki JSON, tryb wnioskowania), a następnie konkretne przykłady kodu: bezpośrednie wywołania REST DeepSeek (curl/Node/Python), użycie klienta Anthropic oraz wywołania przez CometAPI.
Czym jest DeepSeek-V3.1 i co nowego w tej wersji?
DeepSeek-V3.1 to najnowsza wersja w rodzinie DeepSeek V3: linia modeli językowych o dużej pojemności i mieszanym przez ekspertów, która dostarcza hybrydowy projekt wnioskowania z dwoma „trybami” operacyjnymi — szybkim rozmowa bez myślenia tryb i A myślący / rozumujący tryb, który może ujawniać ślady w stylu łańcucha myślowego dla trudniejszych zadań rozumowania i użycia agentów/narzędzi. Wersja kładzie nacisk na szybsze opóźnienie „myślenia”, ulepszone możliwości narzędzi/agentów oraz dłuższe przetwarzanie kontekstu w przepływach pracy na skalę dokumentu.
Najważniejsze praktyczne wnioski:
- Dwa tryby pracy:
deepseek-chatpod kątem przepustowości i kosztów,deepseek-reasoner(model rozumowania), gdy chcesz uzyskać ślady ciągu myśli lub wyższą wierność rozumowania. - Ulepszona obsługa agentów/narzędzi oraz ulepszenia tokenizatora/kontekstu dla długich dokumentów.
- Długość kontekstu: do ~128 tys. tokenów (obsługuje długie dokumenty, bazy kodów, logi).
Przełomowy punkt odniesienia
Wersja DeepSeek-V3.1 wykazała znaczną poprawę w zakresie rzeczywistych wyzwań programistycznych. W zweryfikowanej ocenie SWE-bench, która mierzy częstotliwość, z jaką model naprawia problemy z GitHub, aby zapewnić zaliczenie testów jednostkowych, wersja 3.1 osiągnęła 66% wskaźnik sukcesu, w porównaniu z 45% w wersjach V3-0324 i R1. W wersji wielojęzycznej wersja 3.1 rozwiązała 54.5% problemów, co stanowi prawie dwukrotność wskaźnika sukcesu wynoszącego około 30% w przypadku pozostałych wersji. W ocenie Terminal-Bench, która sprawdza, czy model może pomyślnie wykonywać zadania w rzeczywistym środowisku Linux, DeepSeek-V3.1 pomyślnie rozwiązał 31% zadań, w porównaniu z odpowiednio 13% i 6% w przypadku pozostałych wersji. Te ulepszenia pokazują, że DeepSeek-V3.1 jest bardziej niezawodny w wykonywaniu kodu i działaniu w rzeczywistych środowiskach narzędziowych.
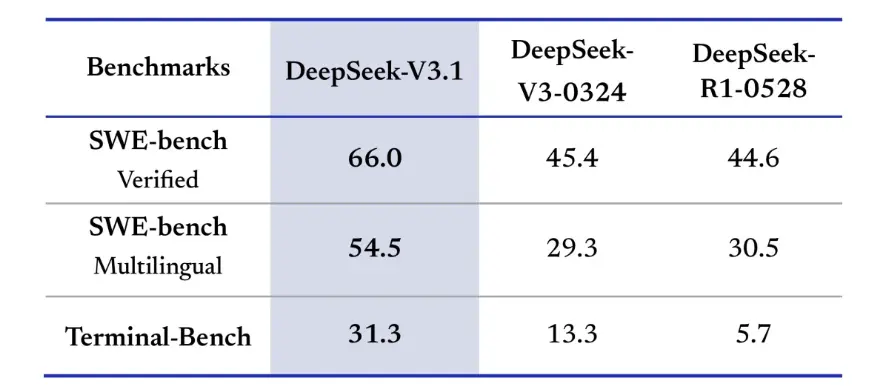
Testy porównawcze wyszukiwania informacji również faworyzują DeepSeek-V3.1 w przeglądaniu, wyszukiwaniu i odpowiadaniu na pytania. W teście BrowseComp, który wymaga nawigacji i wyodrębniania odpowiedzi ze strony internetowej, wersja 3.1 poprawnie odpowiedziała na 30% pytań, w porównaniu z 9% w wersji R1. W wersji chińskiej DeepSeek-V3.1 osiągnął 49% trafności, w porównaniu z 36% w wersji R1. W teście Hard Language Exam (HLE) wersja 3.1 nieznacznie przewyższyła wersję R1, osiągając odpowiednio 30% do 25% trafności. W zadaniach z zakresu głębokiego wyszukiwania, takich jak xbench-DeepSearch, które wymagają syntezy informacji z różnych źródeł, wersja 3.1 uzyskała wynik 71%, a wersja R1 55%. DeepSeek-V3.1 wykazał również niewielką, ale stałą przewagę w testach porównawczych, takich jak (rozumowanie strukturalne), SimpleQA (odpowiadanie na pytania oparte na faktach) i Seal0 (odpowiadanie na pytania dotyczące konkretnych dziedzin). Ogólnie rzecz biorąc, wersja 3.1 znacznie przewyższyła wersję R1 pod względem wyszukiwania informacji i łatwego odpowiadania na pytania.
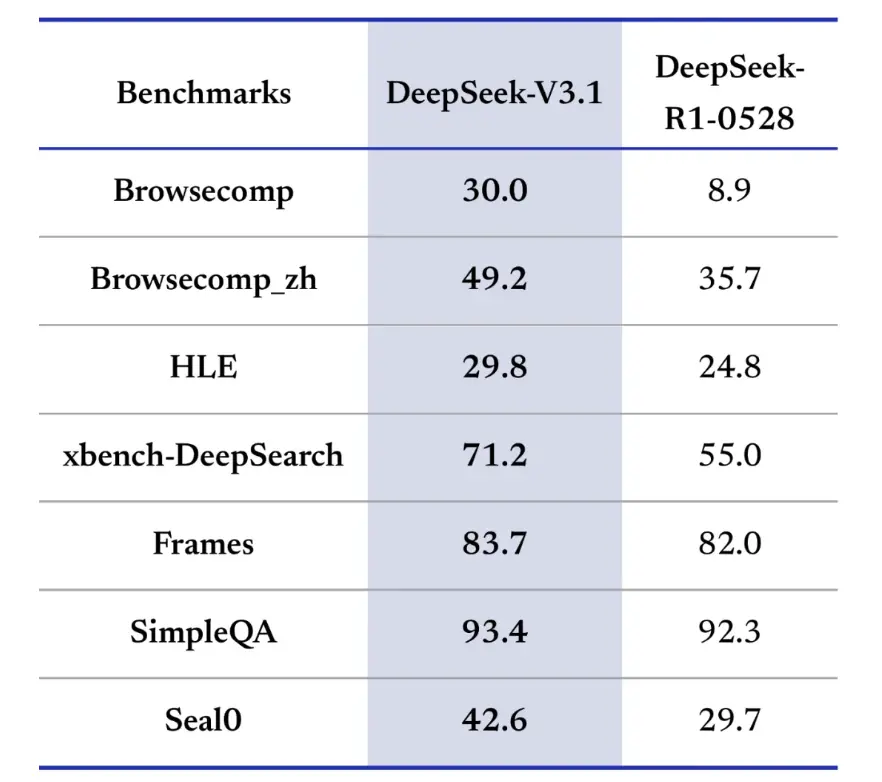
Pod względem efektywności rozumowania, wyniki wykorzystania tokenów potwierdzają jego skuteczność. W teście AIME 2025 (trudnym egzaminie z matematyki) model V3.1-Think osiągnął dokładność porównywalną lub nieznacznie przewyższającą R1 (88.4% w porównaniu z 87.5%), ale zużywał o około 30% mniej tokenów. W teście GPQA Diamond (wielodomenowym egzaminie magisterskim) oba modele uzyskały niemal taki sam wynik (80.1% w porównaniu z 81.0%), ale model V3.1 zużywał prawie połowę tokenów w porównaniu z modelem R1. W teście LiveCodeBench, który ocenia rozumowanie kodu, model V3.1 był nie tylko dokładniejszy (74.8% w porównaniu z 73.3%), ale także bardziej zwięzły. To pokazuje, że model V3.1-Think jest w stanie zapewnić szczegółowe rozumowanie, unikając przy tym rozwlekłości.
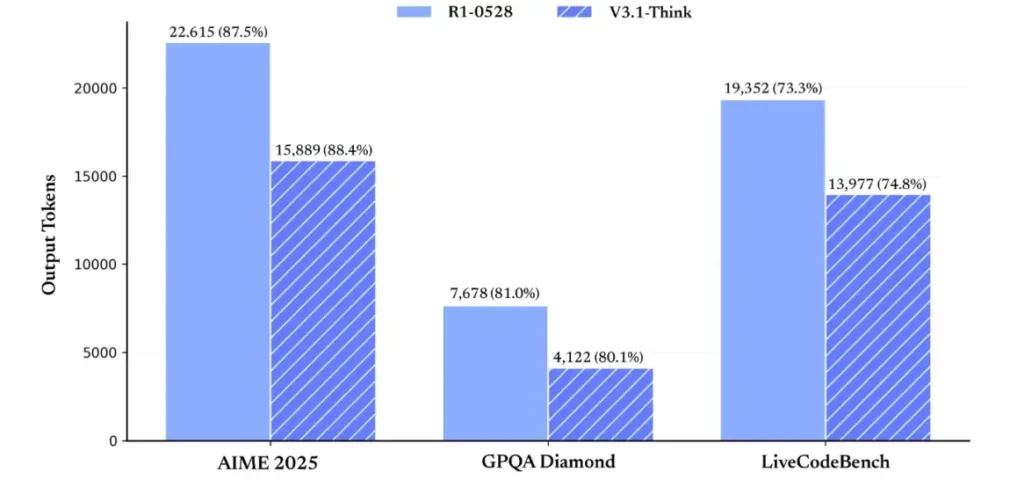
Ogólnie rzecz biorąc, wersja 3.1 stanowi znaczący skok generacyjny w porównaniu z wersją 3-0324. W porównaniu z wersją R1, wersja 3.1 osiągnęła wyższą dokładność w niemal każdym teście i była bardziej efektywna w przypadku zadań wymagających zaawansowanego rozumowania. Jedynym testem, w którym R1 dorównał, była GPQA, ale przy prawie dwukrotnie wyższych kosztach.
Jak uzyskać klucz API i założyć konto programistyczne?
Krok 1: Zarejestruj się i utwórz konto
- Odwiedź portal dla deweloperów DeepSeek (dokumentacja/konsola DeepSeek). Utwórz konto u swojego dostawcy poczty e-mail lub usługi logowania jednokrotnego (SSO).
- Wykonaj wszelkie wymagane przez portal kontrole tożsamości i ustawienia rozliczeń.
Krok 2: Utwórz klucz API
- W panelu przejdź do Klucze API → Utwórz klucz. Nazwij swój klucz (np.
dev-local-01). - Skopiuj klucz i zapisz go w bezpiecznym menedżerze tajnych danych (patrz najlepsze praktyki produkcyjne poniżej).
Wskazówka: niektóre bramy i routery innych firm (np. CometAPI) umożliwiają korzystanie z pojedynczego klucza bramy w celu uzyskania dostępu do modeli DeepSeek za ich pośrednictwem — jest to przydatne w przypadku redundancji wielu dostawców (zobacz Interfejs API DeepSeek V3.1 Sekcja).
Jak skonfigurować środowisko programistyczne (Linux/macOS/Windows)?
To prosta, powtarzalna konfiguracja dla Pythona i Node.js, która działa dla DeepSeek (punkty końcowe zgodne z OpenAI), CometAPI i Anthropic.
Wymagania wstępne
- Python 3.10+ (zalecany), pip, virtualenv.
- Node.js 18+ i npm/yarn.
- curl (do szybkich testów).
Środowisko Pythona (krok po kroku)
- Utwórz katalog projektu:
mkdir deepseek-demo && cd deepseek-demo
python -m venv .venv
source .venv/bin/activate # macOS / Linux
# .venv\Scripts\activate # Windows PowerShell
- Zainstaluj minimalne pakiety:
pip install --upgrade pip
pip install requests
# Optional: install an OpenAI-compatible client if you prefer one:
pip install openai
- Zapisz swój klucz API w zmiennych środowiskowych (nigdy nie zatwierdzaj):
export DEEPSEEK_KEY="sk_live_xxx"
export CometAPI_KEY="or_xxx"
export ANTHROPIC_KEY="anthropic_xxx"
(Używa programu Windows PowerShell $env:DEEPSEEK_KEY = "…")
Środowisko węzła (krok po kroku)
- Zainicjuj:
mkdir deepseek-node && cd deepseek-node
npm init -y
npm install node-fetch dotenv
- Stwórz
.envfile:
DEEPSEEK_KEY=sk_live_xxx
CometAPI_KEY=or_xxx
ANTHROPIC_KEY=anthropic_xxx
Jak wywołać DeepSeek-V3.1 bezpośrednio — przykłady kodu krok po kroku?
API DeepSeek jest zgodne ze standardem OpenAI. Poniżej kopiuj wklej przykłady: curl, Python (w stylu żądań i SDK OpenAI) i Node.
Krok 1: Prosty przykład loków
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-chat-v3.1",
"messages": [
{"role":"system","content":"You are a concise engineering assistant."},
{"role":"user","content":"Give a 5-step secure deployment checklist for a Django app."}
],
"max_tokens": 400,
"temperature": 0.0,
"reasoning_enabled": true
}'
Uwagi: reasoning_enabled Przełącza tryb „Think” (flaga dostawcy). Dokładna nazwa flagi może się różnić w zależności od dostawcy — sprawdź dokumentację modelu.
Krok 2: Python (żądania) z prostą telemetrią
import os, requests, time, json
API_KEY = os.environ
URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat-v3.1",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Refactor this Flask function to be testable: ..."}
],
"max_tokens": 600,
"temperature": 0.1,
"reasoning_enabled": True
}
start = time.time()
r = requests.post(URL, headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}, json=payload, timeout=60)
elapsed = time.time() - start
print("Status:", r.status_code, "Elapsed:", elapsed)
data = r.json()
print(json.dumps(data, indent=2))
CometAPI: całkowicie darmowy dostęp do DeepSeek V3.1
Dla programistów poszukujących natychmiastowego dostępu bez rejestracji, CometAPI oferuje atrakcyjną alternatywę dla DeepSeek V3.1 (nazwa modelu: deepseek-v3-1-250821; deepseek-v3.1). Ta usługa bramy agreguje wiele modeli sztucznej inteligencji (AI) za pośrednictwem ujednoliconego interfejsu API, zapewniając dostęp do DeepSeek i oferując inne korzyści, takie jak automatyczne przełączanie awaryjne, analiza wykorzystania oraz uproszczone rozliczenia między dostawcami.
Najpierw utwórz konto CometAPI na https://www.cometapi.com/—Cały proces zajmuje tylko dwie minuty i wymaga jedynie weryfikacji adresu e-mail. Po zalogowaniu wygeneruj nowy klucz w sekcji „Klucz API”. Strona https://www.cometapi.com/ oferuje darmowe środki na nowe konta i 20% zniżki na oficjalną cenę API.
Implementacja techniczna wymaga minimalnych zmian w kodzie. Wystarczy zmienić punkt końcowy API z bezpośredniego adresu URL DeepSeek na bramkę CometAPI.
Uwaga: API obsługuje strumieniowanie (
stream: true),max_tokens, temperatura, sekwencje zatrzymywania i funkcje wywoływania funkcji podobne do innych interfejsów API zgodnych z OpenAI.
Jak wywołać DeepSeek przy użyciu zestawów SDK firmy Anthropic?
DeepSeek zapewnia punkt końcowy zgodny z Anthropic, dzięki czemu można ponownie wykorzystać zestawy SDK Anthropc lub narzędzia Claude Code, kierując zestaw SDK do https://api.deepseek.com/anthropic i ustawiając nazwę modelu na deepseek-chat (lub deepseek-reasoner (jeśli jest obsługiwane).
Wywołaj model DeepSeek za pomocą interfejsu API Anthropic
Zainstaluj pakiet SDK Anthropic: pip install anthropic. Skonfiguruj swoje środowisko:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=YOUR_DEEPSEEK_KEY
Utwórz wiadomość:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
system="You are a helpful assistant.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hi, how are you?"
}
]
}
]
)
print(message.content)
Użyj DeepSeek w kodzie Claude
Instalacja: npm install -g @anthropic-ai/claude-code. Skonfiguruj swoje środowisko:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=${YOUR_API_KEY}
export ANTHROPIC_MODEL=deepseek-chat
export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chat
Wejdź do katalogu projektu i wykonaj kod Claude’a:
cd my-project
claude
Użyj DeepSeek w Claude Code za pomocą CometAPI
CometAPI obsługuje Claude Code. Po instalacji, podczas konfiguracji środowiska, wystarczy zastąpić adres URL bazowy adresem https://api.cometapi.com, a klucz kluczem CometAPI, aby korzystać z modelu DeepSeek CometAPI w Claude Code.
# Navigate to your project folder cd your-project-folder
# Set environment variables (replace sk-... with your actual token)
export ANTHROPIC_AUTH_TOKEN=sk-...
export ANTHROPIC_BASE_URL=https://www.cometapi.com/console/
# Start Claude Code
claude
Uwagi:
- DeepSeek mapuje nieobsługiwane nazwy modeli antropicznych na
deepseek-chat. - Warstwa kompatybilności antropicznej obsługuje
system,messages,temperature, strumieniowanie, sekwencje zatrzymywania i tablice myślowe.
Jakie są konkretne, najlepsze praktyki produkcyjne (bezpieczeństwo, koszty, niezawodność)?
Poniżej przedstawiono zalecane wzorce produkcji, które mają zastosowanie w przypadku DeepSeek lub dowolnego zastosowania LLM o dużej objętości.
Sekrety i tożsamość
- Przechowuj klucze API w menedżerze sekretów (nie używaj
.env(w środowisku produkcyjnym). Regularnie wymieniaj klucze i twórz klucze dla poszczególnych usług z najmniejszymi uprawnieniami. - Użyj oddzielnych projektów/kont dla środowiska rozwojowego/staging/produkcyjnego.
Limity szybkości i ponowne próby
- Wdrożenie wycofywanie wykładnicze na HTTP 429/5xx z jitterem. Ogranicz liczbę ponownych prób (np. 3 próby).
- Użyj kluczy idempotentności w przypadku żądań, które mogą się powtarzać.
Przykład w Pythonie — ponawianie próby z wycofaniem
import time, random, requests
def post_with_retries(url, headers, payload, attempts=3):
for i in range(attempts):
r = requests.post(url, json=payload, headers=headers, timeout=60)
if r.status_code == 200:
return r.json()
if r.status_code in (429, 502, 503, 504):
backoff = (2 ** i) + random.random()
time.sleep(backoff)
continue
r.raise_for_status()
raise RuntimeError("Retries exhausted")
Zarządzanie kosztami
- Ograniczenia
max_tokensi unikaj przypadkowego żądania ogromnych wyników. - Odpowiedzi modelu pamięci podręcznej w stosownych przypadkach (zwłaszcza w przypadku powtarzających się monitów). DeepSeek wyraźnie rozróżnia trafienia i chybienia w pamięci podręcznej w cenniku — buforowanie oszczędza pieniądze.
- Zastosowanie
deepseek-chatdo rutynowych, krótkich odpowiedzi; rezerwadeepseek-reasonerw przypadkach, gdy CoT jest naprawdę potrzebne (jest droższe).
Obserwowalność i rejestrowanie
- Rejestruj tylko metadane dotyczące żądań w postaci zwykłego tekstu (hasze monitów, liczbę tokenów, opóźnienia). Unikaj rejestrowania pełnych danych użytkownika lub poufnych treści. Przechowuj identyfikatory żądań/odpowiedzi na potrzeby wsparcia i uzgadniania rozliczeń.
- Śledź użycie tokenów na żądanie i udostępniaj budżetowanie/alerty dotyczące kosztów.
Kontrola bezpieczeństwa i halucynacji
- Zastosowanie wyjścia narzędzi i walidatory deterministyczne w przypadku wszelkich kwestii mających znaczenie dla bezpieczeństwa (finansowych, prawnych, medycznych).
- W przypadku wyników strukturalnych należy użyć
response_format+Schemat JSON i walidacja wyników przed podjęciem nieodwracalnych działań.
Wzorce wdrażania
- Uruchamiaj wywołania modelu z dedykowanego procesu roboczego, aby kontrolować współbieżność i kolejkowanie.
- Przenieś ciężkie zadania do asynchronicznych procesów roboczych (zadania Celery, Fargate, zadania Cloud Run) i reaguj użytkownikom za pomocą wskaźników postępu.
- W przypadku ekstremalnych opóźnień i wymagań dotyczących przepustowości należy wziąć pod uwagę umowy SLA dostawcy oraz zdecydować, czy hostować urządzenie samodzielnie, czy korzystać z akceleratorów dostawcy.
Notatka końcowa
DeepSeek-V3.1 to pragmatyczny, hybrydowy model zaprojektowany zarówno do szybkiego czatu, jak i złożonych zadań agentowych. Jego interfejs API zgodny z OpenAI ułatwia migrację w wielu projektach, a warstwy kompatybilności Anthropic i CometAPI zapewniają elastyczność w istniejących ekosystemach. Testy porównawcze i raporty społeczności wskazują na obiecujący kompromis między kosztami a wydajnością — ale jak w przypadku każdego nowego modelu, przed pełnym wdrożeniem produkcyjnym należy go zweryfikować w rzeczywistych obciążeniach (monitory, wywoływanie funkcji, kontrole bezpieczeństwa, opóźnienia).
W CometAPI możesz bezpiecznie uruchomić go i wchodzić z nim w interakcję za pomocą interfejsu API zgodnego ze standardem OpenAI lub przyjaznego dla użytkownika plac zabaw dla dzieci, bez ograniczeń prędkości.
👉 Wdróż teraz DeepSeek-V3.1 na CometAPI!
Dlaczego warto używać CometAPI?
- Multipleksowanie dostawców:zmień dostawcę bez przepisywania kodu.
- Ujednolicone rozliczenia/metryki:jeśli kierujesz wiele modeli przez CometAPI, otrzymujesz pojedynczą powierzchnię integracji.
- Metadane modelu: zobacz długość kontekstu i aktywne parametry dla każdego wariantu modelu.