

Claude Opus 4.6 firmy Anthropic pojawił się w lutym 2026 r. jako wyraźny, celowo zaprojektowany krok w kierunku agentów klasy korporacyjnej, pracy wiedzowej z długim kontekstem oraz silniejszej autonomicznej syntezy kodu. Wydanie łączy ambitną inżynierię (beta tryb kontekstu na milion tokenów, możliwość „adaptive thinking” oraz funkcje pracy zespołowej agentów) z pragmatyczną decyzją handlową: Anthropic utrzymał ceny API zgodne z poprzednimi modelami z rodziny Opus. To połączenie — materialnie ulepszone możliwości bez natychmiastowego skoku cenowego — jest najważniejszym przekazem.
Czym dokładnie jest Claude Opus 4.6?
Claude Opus 4.6 to flagowy model Anthropic w linii Opus: wielkoskalowy, ukierunkowany na przedsiębiorstwa generatywny model AI zoptymalizowany pod agentowe przepływy pracy, programowanie i długohoryzontową pracę z wiedzą. Anthropic pozycjonuje Opus 4.6 jako swój najbardziej inteligentny model do budowania agentów i automatyzacji — zaprojektowany nie tylko do odpowiadania na pytania, ale do planowania, wywoływania narzędzi, koordynowania podagentów i wykonywania wieloetapowych zadań w dużych bazach kodu i korpusach dokumentów.
W odróżnieniu od chatbotów konsumenckich, Opus 4.6 celuje w integracje korporacyjne: jest dostępny przez interfejs claude.ai, Claude API oraz przez CometAPI. Mocną stroną Opus 4.6 są agentowe zadania kodowe i wywoływanie narzędzi. Dla przedsiębiorstw oznacza to, że Opus 4.6 jest pozycjonowany jako „drop‑in” aktualizacja dla asystentów agentowych, narzędzi migracji kodu, potoków przeglądu dokumentów i przepływów analitycznych, które potrzebują szerszego kontekstu niż typowe sesje czatu.
Dogłębna analiza kluczowych nowych funkcji w Opus 4.6
Kontekst na milion tokenów (i tryby praktyczne)
Opus 4.6 obsługuje rozszerzone domyślne okno kontekstu (deklarowane 200K tokenów, z 1M tokenów w wersji beta). Milion‑tokenowe okno jest na papierze przełomowe: pozwala modelowi „utrzymać” całe repozytoria kodu, długie pisma prawne, wieloletnie archiwa e‑maili czy duże tabele danych w jednej rozmowie, co ogranicza potrzebę zewnętrznych rusztowań do wyszukiwania. Anthropic łączy surowe okno kontekstu z narzędziami „kompresji kontekstu”, które pomagają zagęścić istotne informacje i zmniejszyć koszty tokenów. Krótko mówiąc: Opus może realnie pracować z bardzo dużymi artefaktami bez dzielenia ich na fragmenty, co upraszcza budowanie długotrwałych agentów.
Dlaczego to ma znaczenie: w refaktoryzacji kodu, przeglądach prawnych/finansowych czy projektach badawczych wymagających rozumowania między dokumentami, większe okno zmniejsza narzut inżynieryjny (mniej retrievali, mniej zarządzania stanem) i poprawia spójność w bardzo długich łańcuchach rozumowania.
Adaptive thinking i rozszerzone sterowanie rozumowaniem
Opus 4.6 wprowadza to, co Anthropic nazywa „adaptive thinking” (ewolucja wcześniejszych idei „extended thinking”). To zarówno wewnętrzna zdolność, jak i kontrola w API: deweloperzy mogą stroić „poziomy wysiłku” i głębokość planowania, pozwalając modelowi zużywać więcej mocy obliczeniowej na skomplikowane planowanie albo utrzymywać krótkie, szybkie odpowiedzi przy zadaniach trywialnych.
Dlaczego to ma znaczenie: w agentowych przepływach pracy marginalne poprawy jakości się kumulują: lepsze planowanie + koordynacja oznaczają mniej poprawek ludzkich i bardziej niezawodną autonomiczną realizację.
Czym są „zespoły agentów” i orkiestracja agentowa?
Opus 4.6 wprowadza usprawnione wsparcie dla agentowych przepływów pracy: możliwość tworzenia, koordynowania i nadzorowania wielu podagentów dzielących się zadaniami. Materiały Anthropic (i wczesne relacje partnerów) podkreślają, że Opus potrafi proaktywnie tworzyć podagentów, przydzielać podzadania, monitorować ich postęp oraz kończyć lub zmieniać strategie w razie potrzeby — efektywnie działając jako lekki orkiestrator do złożonych, wieloetapowych prac inżynieryjnych lub analitycznych. To ścisłe połączenie planowania, użycia narzędzi i korekcji błędów jest kluczową zaletą dla zespołów mocno nastawionych na automatyzację.
Usprawnienia API i narzędzi dla integracji korporacyjnych
Anthropic rozszerzył kontrolki API dla kompresji, trwałości i wywoływania narzędzi. Model obsługuje większe limity wyjściowe (Anthropic wspomina o do 128K tokenów wyjściowych), bardziej precyzyjną semantykę retrievalu oraz integracje korporacyjne z Microsoft 365 i środowiskami deweloperskimi. Praktyczny efekt to mniej „kleju” przy podłączaniu Opus do arkuszy kalkulacyjnych, slajdów i wewnętrznych łańcuchów narzędzi. Anthropic zintegrował Opus 4.6 z narzędziami wyższego poziomu, takimi jak Claude Cowork (interfejsy no‑code) oraz aktualizacjami Claude Code, które pozwalają nietechnicznym użytkownikom korzystać z automatyzacji.
Jak wypada Opus 4.6 w benchmarkach?
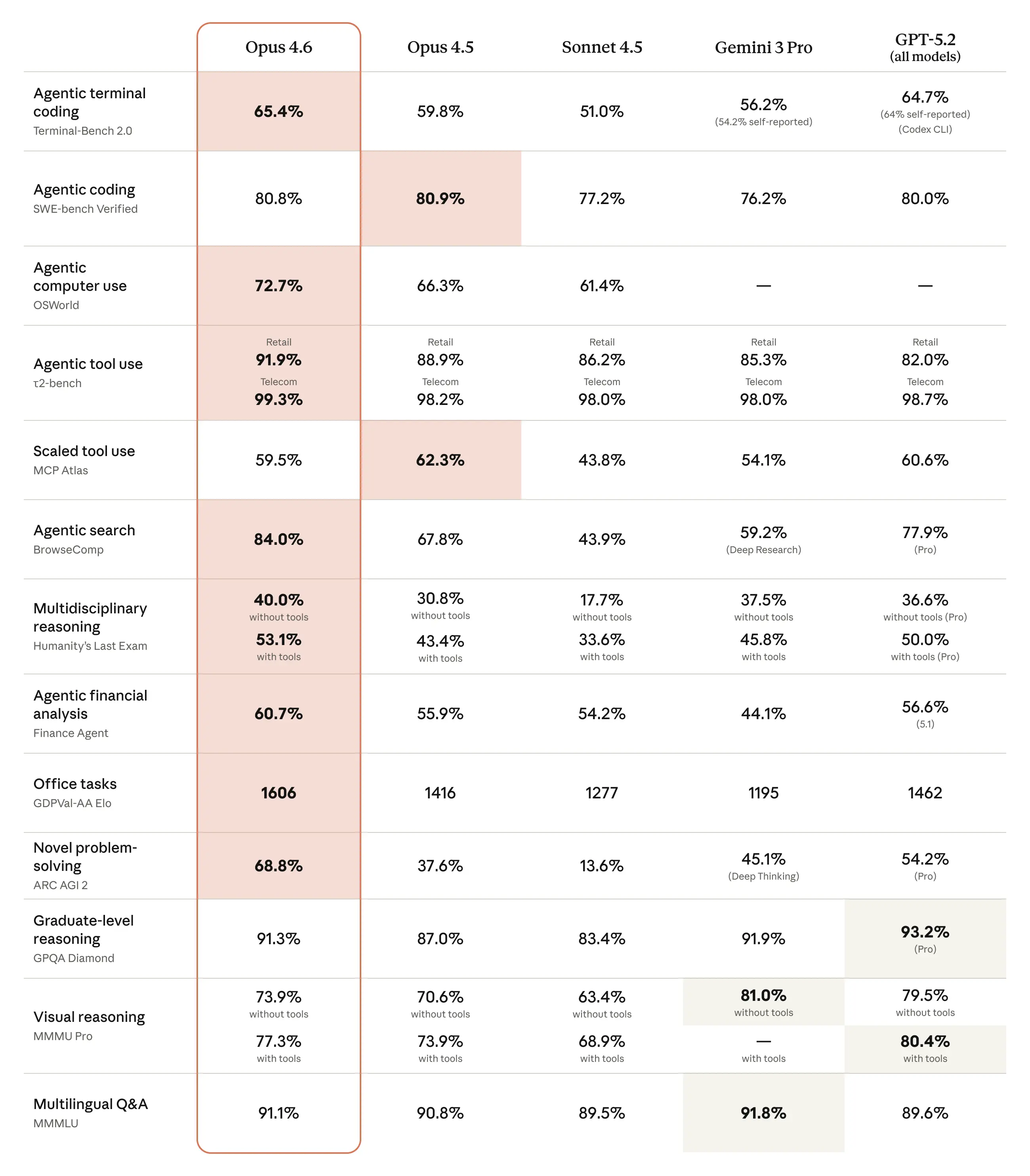
Opus 4.6 zyskuje względem Opus 4.5 i plasuje się konkurencyjnie wobec nowszych modeli OpenAI i Google na mieszance zestawów kodowania, rozumowania i domenowych. Przykłady raportowane skrótowo:
- BigLaw Bench: Opus 4.6 osiągnął ~90.2% na BigLaw Bench Anthropic (rozumowanie prawnicze).
- Terminal-Bench 2.0 / metryki GDPval: niezależne relacje podają wyniki Terminal-Bench 2.0 i oceny Elo GDPval-AA, które sytuują Opus 4.6 przed Opus 4.5 i konkurencyjnie wobec niektórych najnowszych wydań rywali. Jeden raport wymieniał wynik Terminal-Bench 2.0 na poziomie 65.4% i Elo GDPval-AA ~1,606.
Anthropic raportuje duże zyski w agentowych zadaniach kodowych, z lepszym planowaniem, mniejszą liczbą iteracji i mocniejszym wynikiem na ogromnych bazach kodu — w tym twierdzenia o planowaniu i wykonywaniu migracji na wielomilionowych repozytoriach w krótszym czasie. Podkreślana jest ulepszona zdolność modelu do „samowyłapywania” błędów i podtrzymywania rozumowania przez wiele kroków.
Ile kosztuje Opus 4.6?
Krótka odpowiedź — ceny per token
- Standard (prompts ≤ 200K tokens): $5 / 1M input tokens i $25 / 1M output tokens.
- Large prompts (prompts > 200K tokens): $10 / 1M input i $37.50 / 1M output.
- Fast mode (research preview): poziom premium — $30 / 1M input i $150 / 1M output (szybsze wnioskowanie).
Praktyczne kwestie kosztowe:
- Przepływy agentowe są zwykle tokenożerne. Wieloetapowe planowanie, wywołania narzędzi i długie odpowiedzi zwiększają tokeny wyjściowe; ostrożne użycie kompresji i odczytów z cache ma znaczenie dla kontrolowania rozliczeń.
- Wsadowo jest taniej. Jeśli Twój profil pracy pasuje do asynchronicznego przetwarzania wsadowego, ceny batch API Anthropic mogą zauważalnie obniżyć koszt per token.
- Premiowy kontekst jest droższy. Jeśli często polegasz na becie 1M tokenów, zaplanuj wyższe opłaty per token. Wiele organizacji będzie mieszać tryby: duże konteksty tylko tam, gdzie to absolutnie konieczne, a „odchudzone” sesje w pozostałych przypadkach.
Szukasz tańszych sposobów korzystania z Claude API
CometAPI to dobry wybór. Opus 4.6 API również pochodzi od Anthropic, ale jego ceny API wynoszą 20% oficjalnej ceny i nie zmieniają się wraz ze zmianami długości kontekstu.
Jak Opus 4.6 wypada na tle GPT-5.3 i Google Gemini 3?
Opus 4.6 vs GPT-5.3 od OpenAI
Najnowszy GPT-5.3 od OpenAI (firmowany przez OpenAI w linii „Codex” do zadań programistycznych/agentowych) jest explicite dostrojony do głębokiego programowania i agentowych przepływów pracy i deklaruje wiodące w branży wyniki na kilku inżynierskich benchmarkach (SWE-Bench Pro, Terminal-Bench). Wczesne relacje sugerują, że GPT-5.3-Codex przesuwa granice SOTA w benchmarkach inżynierii oprogramowania i planowania agentowego, pozycjonując go jako najbliższego rywala Opus 4.6 w czysto programistycznych i agentowych zadaniach. Z kolei Opus 4.6 podkreśla ekstremalnie długi kontekst i orkiestrację wielu agentów jako wyróżniki. Krótko: GPT-5.3 wydaje się zoptymalizowany pod surową głębię inżynierską i dominację w testach deweloperskich; Opus 4.6 akcentuje szerokość zastosowań w długokontekstowych przepływach pracy przedsiębiorstw i rozumowaniu dziedzinowym.
Opus 4.6 vs Google Gemini 3?
Gemini 3 od Google (oraz warianty Gemini 3 Pro / Deep Think) są wyróżniane za mocne wyniki w abstrakcyjnym rozumowaniu, rozwiązywaniu problemów wizualnych i niektórych benchmarkach QA w naukach ścisłych; przesunęły też dalej zaawansowane rozumowanie multimodalne względem poprzedników. Relacje pozycjonują Gemini 3 jako szczególnie silny w naukowych i wizualnych zestawach rozumowania, podczas gdy przewagą Opus 4.6 jest długi kontekst w pracy z kodem oraz w zadaniach prawno‑korporacyjnych. Dla organizacji potrzebujących multimodalnego rozumowania naukowego lub zaawansowanych zadań logiczno‑wizualnych, Gemini 3 może mieć przewagę; do długotrwałej, długokontekstowej pracy z wiedzą i automatyzacji z wieloma agentami, Opus 4.6 prezentuje silną propozycję.
Kto „wygrywa” w bezpośrednich starciach?
Nie ma jednego dostawcy, który „wygrywa” wszędzie: wybór zależy od przepływu pracy, na którym Ci zależy. Wczesne porównania niezależne pokazują, że Opus 4.6 przewyższa Opus 4.5 o zauważalny margines w zadaniach długohoryzontowych i domenowych, podczas gdy GPT-5.3 i Gemini 3 utrzymują przewagi w niektórych testach programistycznych i multimodalnych. Jak w każdej szybko ewoluującej generacji, wygrywa klient, który dopasowuje mocne strony modelu do realnych obciążeń i integracji narzędzi, a nie model z najwyższym wynikiem w jednym benchmarku.
Czy Claude Opus 4.6 jest tego wart?
Krótka odpowiedź: Tak — jeśli Twoimi głównymi problemami są rozumowanie z długim kontekstem, autonomiczne przepływy agentowe lub zgodność korporacyjna. Mocne strony Opus 4.6 są realne i istotne: okna 200K (i beta 1M), adaptive thinking, zespoły agentów i integracje korporacyjne to namacalne ulepszenia, które zmniejszają złożoność inżynierii produktu i zwiększają klasę problemów, które możesz zautomatyzować.
Jeśli natomiast Twoje obciążenie to głównie krótkie, mocno powtarzalne mikrozadania, gdzie kluczowe są koszt jednostkowy i latencja, Opus 4.6 może być „armata na wróble” w porównaniu z modelem wyspecjalizowanym do krótkiego horyzontu (np. GPT-5.3 Codex) — chyba że planujesz je łączyć i odpowiednio kierować zadania.
CometAPI to platforma agregująca API dużych modeli „all‑in‑one”, oferująca bezproblemową integrację i zarządzanie usługami API. Obsługuje wywoływanie różnych mainstreamowych modeli AI. Obejmuje to generowanie obrazów, generowanie wideo, czat, TTS i STT AI — wszystko na jednej platformie.
Możesz też wybrać model w zależności od pożądanego kosztu i możliwości oraz przełączać się między nimi w dowolnym momencie, np. Gemini 3 Flash, GPT 5.3 lub Opus 4.6. Zanim uzyskasz dostęp, upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. CometAPI oferuje ceny znacznie niższe niż oficjalne, ułatwiając integrację.
Gotowy do startu?→ Zarejestruj się, aby kodować już dziś!
Jeśli chcesz poznać więcej wskazówek, poradników i nowości o AI, obserwuj nas na VK, X i Discord!