

Kling O1 — wydany w ramach tygodnia premiery „Omni” firmy Kling AI — pozycjonuje się jako pojedynczy, zunifikowany, multimodalny model fundamentu wideo, który akceptuje tekst, obrazy i filmy w jednym żądaniu i może zarówno generować, jak i edytować wideo w iteracyjnych, reżyserskich przepływach pracy. Zespół Klinga określa O1 jako „pierwszy na świecie zunifikowany, multimodalny model wideo na dużą skalę”. Wewnętrzne testy Klinga wskazują na znaczące przewagi nad rozwiązaniami Google Veo 3.1 i Runway Aleph.
Czym jest Kling O1?
Kling O1 (często sprzedawany jako Wideo O1 or Omni jeden) to nowo wydany model bazowy wideo firmy Kling AI, który ujednolica generowanie i edycję tekstu, obrazów i wideo w ramach jednego, opartego na poleceniach frameworka. Zamiast traktować przetwarzanie tekstu na wideo, obrazu na wideo i edycję wideo jako oddzielne procesy, Kling O1 akceptuje mieszane dane wejściowe (tekst + wiele obrazów + opcjonalne wideo referencyjne) w jednym poleceniu, uzasadnia je i generuje spójne krótkie klipy lub edytuje istniejące materiały z precyzyjną kontrolą. Firma określiła wdrożenie jako część „Wszechstronnego Wprowadzenia” i opisuje O1 jako „multimodalny silnik wideo” zbudowany w oparciu o paradygmat Multimodalnego Języka Wizualnego (MVL) i ścieżkę rozumowania Łańcucha Myśli (CoT) do interpretowania złożonych, wieloczęściowych instrukcji kreatywnych.
Komunikacja Klinga kładzie nacisk na trzy praktyczne przepływy pracy: (1) tekst → generowanie wideo, (2) obraz/element → wideo (kompozycja i zamiana obiektów/rekwizytów z wykorzystaniem jawnych odniesień) oraz (3) edycja wideo/kontynuacja ujęcia (zmiana stylu, dodawanie/usuwanie obiektów, sterowanie początkową/końcową klatką). Model obsługuje monity wieloelementowe (w tym składnię „@” do kierowania na konkretne obrazy referencyjne) i oferuje sterowanie w stylu reżyserskim, takie jak zakotwiczenie klatki początkowej/końcowej i kontynuacja wideo w celu tworzenia sekwencji wieloujęciowych.
5 najważniejszych cech Kling O1
1) Prawdziwe ujednolicone wejście multimodalne (MVL)
Flagową funkcją Kling O1 jest przetwarzanie tekstu, nieruchomych obrazów (wielokrotne odniesienia) i wideo jako pierwszorzędnych, jednoczesnych danych wejściowych. Użytkownicy mogą dostarczyć kilka obrazów referencyjnych (lub krótki klip referencyjny). oraz Instrukcja w języku naturalnym; model będzie analizował wszystkie dane wejściowe razem, aby wygenerować lub edytować spójny wynik. Zmniejsza to tarcie w łańcuchu narzędzi i umożliwia przepływy pracy takie jak „użyj tematu z @image1, umieść je w środowisku od @image2, dopasuj ruch do ref_video.mp4i zastosuj kinową gradację kolorów X”. To ujęcie „Multimodalnego Języka Wizualnego” (MVL) stanowi sedno prezentacji Klinga.
Dlaczego jest to ważne: Prawdziwe procesy kreatywne często wymagają łączenia materiałów referencyjnych: postaci z jednego zasobu, ruchu kamery z innego oraz instrukcji narracyjnej w tekście. Ujednolicenie tych danych wejściowych umożliwia generowanie obrazu w jednym przejściu i mniejszą liczbę ręcznych kroków kompozycji.
2) Edycja + generacja w jednym modelu (tryb wieloelementowy)
Większość wcześniejszych systemów oddzielała generowanie (tekst→wideo) od edycji z dokładnością do klatki. O1 celowo je łączy: ten sam model, który tworzy klip od podstaw, może również edytować istniejące materiały – podmieniając obiekty, zmieniając styl ubrań, usuwając rekwizyty lub wydłużając ujęcie – wszystko za pomocą instrukcji w języku naturalnym. Ta konwergencja znacznie upraszcza przepływ pracy w zespołach produkcyjnych.
Model O1 w swojej istocie zapewnia głęboką integrację wielu zadań wideo:
- Generowanie tekstu na wideo
- Generowanie odniesień do obrazu/obiektu
- Edycja wideo i inpainting
- Zmiana stylu wideo
- Następne/poprzednie generowanie strzału
- Generowanie wideo z ograniczeniami klatek kluczowych
Największe znaczenie tego projektu polega na tym, że: złożone procesy, które wcześniej wymagały wielu modeli lub niezależnych narzędzi, można teraz zrealizować w ramach jednego silnika. To nie tylko znacznie obniża koszty tworzenia i obliczeń, ale także kładzie podwaliny pod rozwój „zunifikowanego modelu rozumienia i generowania wideo”.
3) Spójność generowania wideo
Spójność tożsamości: Model O1 zwiększa możliwości modelowania spójności międzymodalnej, zachowując stabilność struktury, materiału, oświetlenia i stylu obiektu referencyjnego w trakcie procesu generowania:
- Obsługuje obrazy referencyjne o wielu widokach do modelowania obiektów;
- obsługuje spójność ujęć obiektu (cechy postaci, obiektów i scen pozostają takie same w różnych ujęciach);
- obsługuje hybrydowe odniesienia wielotematyczne, co pozwala na generowanie portretów grupowych i interaktywną konstrukcję scen.
Mechanizm ten znacząco poprawia spójność i „spójność tożsamościową” generowanych materiałów wideo, dzięki czemu nadaje się do scenariuszy o wyjątkowo wysokich wymaganiach dotyczących spójności, takich jak generowanie reklam i ujęć na poziomie filmu.
Poprawiona pamięć: Model O1 posiada również „pamięć”, która zapobiega niestabilności stylu wyjściowego z powodu długich kontekstów lub zmieniających się instrukcji. Potrafi nawet:
- zapamiętywanie wielu znaków jednocześnie;
- umożliwiać interakcję różnych postaci w filmie;
- zachować spójność stylu, ubioru i postawy.
4) Precyzyjne komponowanie za pomocą składni „@” i kontroli początku/końca klatki
Kling wprowadził skrót kompozycji (zwany systemem wzmianek „@”), dzięki czemu można odwoływać się do konkretnych obrazów w monicie (np. @image1, @image2) do niezawodnego przypisywania ról do zasobów. W połączeniu z wyraźną specyfikacją klatki początkowej i końcowej, umożliwia to kontrolę na poziomie reżysera nad tym, jak elementy przechodzą, przesuwają się lub przekształcają w generowanym klipie — zestaw funkcji zorientowanych na produkcję, który wyróżnia O1 spośród wielu generatorów zorientowanych na użytkownika.
5) Wysoka wierność, długie czasy wyjścia i łączenie wielu zadań
Kling O1 ma generować kinowe wyniki w rozdzielczości 1080p (30 kl./s) i – biorąc pod uwagę wcześniejsze wersje Klinga – firma chwali się generowaniem dłuższych klipów (w najnowszych opisach produktów deklarowano długość do 2 minut). Obsługuje również łączenie wielu zadań kreatywnych w jednym żądaniu (generowanie, dodawanie tematu, zmiana oświetlenia i edycja kompozycji). Te właściwości sprawiają, że jest konkurencyjny w stosunku do zaawansowanych silników tekstowo-wideo.
Dlaczego jest to ważne: Dłuższe klipy o wysokiej jakości i możliwość łączenia edycji redukują potrzebę łączenia wielu krótkich klipów i upraszczają kompleksową produkcję.
Jak zbudowana jest architektura Kling O1 i jakie są leżące u jej podstaw mechanizmy?
O1 wokół Multimodalny język wizualny (MVL) Rdzeń: model, który uczy się wspólnych osadzeń dla sygnałów językowych + obrazów + ruchu (klatek wideo i cech typu przepływu optycznego), a następnie stosuje dekodery oparte na dyfuzji lub transformatorze do syntezy ramek koherentnych czasowo. Model jest opisany jako wykonujący kondycjonowanie na podstawie wielu odniesień (tekst, obrazy jeden do wielu, krótkie klipy wideo) w celu wytworzenia ukrytej reprezentacji wideo, która jest następnie dekodowana do obrazów dla każdej klatki, przy jednoczesnym zachowaniu spójności czasowej za pomocą uwagi międzyklatkowej lub specjalistycznych modułów czasowych.
1. Transformator multimodalny + architektura długiego kontekstu
Model O1 wykorzystuje samodzielnie opracowaną przez Kelinga multimodalną architekturę Transformer, integrującą sygnały tekstowe, graficzne i wideo oraz obsługującą długą pamięć kontekstową (Multimodal Long Context).
Dzięki temu model może zrozumieć ciągłość czasową i spójność przestrzenną podczas generowania wideo.
2. MVL: Multimodalny język wizualny
MVL jest podstawową innowacją tej architektury.
Głęboko harmonizuje język i sygnały wizualne w obrębie Transformera poprzez ujednoliconą semantyczną warstwę pośrednią, dzięki czemu:
- Umożliwiając łączenie instrukcji multimodalnych w jednym polu wprowadzania danych;
- Poprawa dokładnego rozumienia przez model opisów języka naturalnego;
- Wsparcie dla niezwykle elastycznego, interaktywnego generowania materiałów wideo.
Wprowadzenie MVL oznacza zmianę w generowaniu materiałów wideo z „sterowanego tekstem” na „współsterowane semantycznie i wizualnie”.
3. Mechanizm wnioskowania łańcuchowego
Model O1 wprowadza ścieżkę wnioskowania „łańcucha myśli” na etapie generowania wideo.
Mechanizm ten pozwala modelowi na wykonanie logiki zdarzeń i dedukcji czasu przed wygenerowaniem, zachowując w ten sposób naturalne powiązanie między akcjami i zdarzeniami w materiale wideo.
Kanały wnioskowania i edycji
- Pokolenie: kanał: (tekst + opcjonalne odniesienia do obrazów + opcjonalne odniesienia do wideo + ustawienia generowania) → model generuje ukryte klatki wideo → dekodowanie do klatek → opcjonalne przetwarzanie kolorów/czasu.
- Edycja oparta na instrukcjach: Feed: (oryginalne wideo + instrukcja tekstowa + opcjonalne odnośniki do obrazów) → model wewnętrznie mapuje żądaną edycję na zestaw transformacji w przestrzeni pikseli, a następnie syntetyzuje edytowane klatki, zachowując niezmienioną treść. Ponieważ wszystko znajduje się w jednym modelu, te same moduły warunkowania i temporalne są używane zarówno do tworzenia, jak i edycji.
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
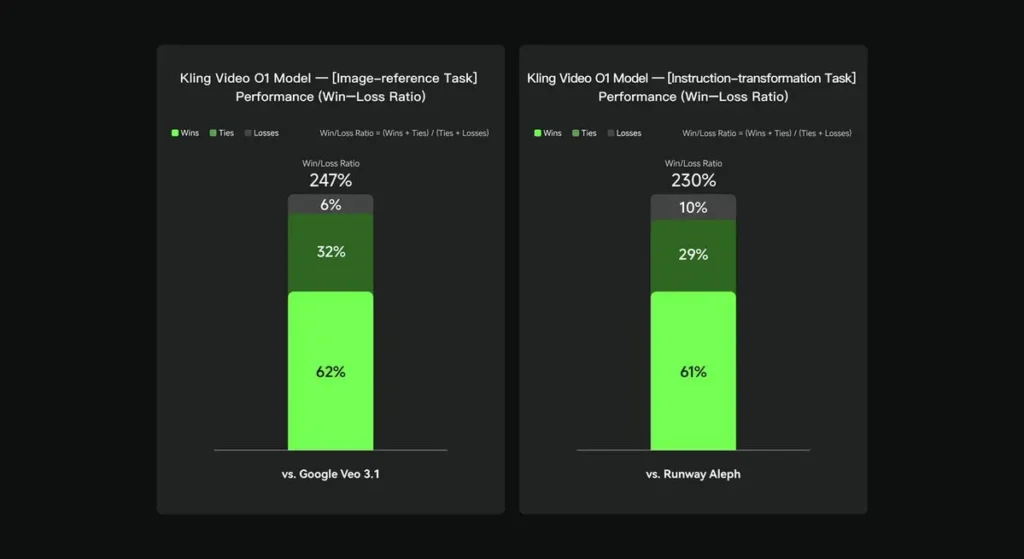
W ocenach wewnętrznych Keling Video O1 znacząco przewyższył istniejące międzynarodowe odpowiedniki w kilku kluczowych wymiarach. Wyniki wydajności (na podstawie samodzielnie utworzonego zestawu ocen Keling AI):
- Zadanie „Odniesienie do obrazu”: O1 przewyższa Google Veo 3.1 w ogólnym rozrachunku, ze wskaźnikiem wygranych wynoszącym 247%;
- Zadanie „Transformacja instrukcji”: O1 przewyższa Runway Aleph, ze współczynnikiem wygranych wynoszącym 230%.
Przegląd konkurencji (porównanie na poziomie funkcji)
| Możliwość / Model | Kling O1 | Google Veo 3.1 | Pas startowy (Aleph / Gen-4.5) |
|---|---|---|---|
| Zunifikowany komunikat multimodalny (tekst + obrazy + wideo) | Tak (główny argument sprzedaży). przepływy multimodalne z pojedynczym żądaniem. | Częściowo — istnieje tekst→wideo + odnośniki; mniejszy nacisk na pojedynczy, ujednolicony MVL. | Runway skupia się na generowaniu i edycji, ale często jako oddzielnych trybach; najnowsza Gen-4.5 zmniejsza tę różnicę. |
| Edycje pikselowe oparte na konwersacji/tekście | Tak — „edytuj jak rozmowę” (bez masek). | Częściowo — edycja istnieje, ale przepływy pracy z maskami/klatkami kluczowymi są nadal powszechne. | Runway ma zaawansowane narzędzia edycyjne; Runway twierdzi, że zaawansowane instrukcje transformują (różnią się w zależności od wersji). |
| Kontrola klatki początkowej/końcowej i odniesienie do kamery | Tak — dokładny opis klatki początkowej/końcowej i ruchów kamery odniesienia. | Ograniczony / rozwijający się | Pas startowy: ulepszone sterowanie; nie jest to dokładnie ten sam UX. |
| Generowanie długich klipów (wysoka wierność) | do ~2 minut (1080p, 30 kl./s) w materiałach produktowych i postach społecznościowych; | Veo 3.1: silna spójność, ale wcześniejsze wersje miały krótsze domyślne czasy; różnią się w zależności od modelu/ustawienia. | Runway Gen-4.5: stawia na wysoką jakość; długość/wierność odwzorowania są zmienne. |
Wnioski:
Publicznym powodem sławy Kling O1 jest ujednolicenie przepływu pracy: nadanie pojedynczemu modelowi mandatu do rozumienia tekstu, obrazów i wideo oraz wykonywania zarówno generowania, jak i edycji opartej na rozbudowanych instrukcjach w ramach tego samego systemu semantycznego. Dla twórców i zespołów, które często przemieszczają się między krokami „tworzenia”, „edycji” i „rozszerzania”, taka konsolidacja może radykalnie uprościć iteracje i zmniejszyć złożoność narzędzi. Lepsza spójność czasowa, kontrola klatek początkowych i końcowych oraz pragmatyczna integracja z platformą sprawiają, że jest ona dostępna dla twórców.
Interfejs API Kling Video o1 będzie wkrótce dostępny w CometAPI.
Deweloperzy mogą uzyskać dostęp Kling 2.5 Turb oraz Interfejs API Veo 3.1 przez Interfejs API Comet, najnowsze wymienione modele są z dnia publikacji artykułu. Na początek zapoznaj się z możliwościami modelu w Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. Interfejs API Comet zaoferuj cenę znacznie niższą niż oficjalna, aby ułatwić Ci integrację.
Gotowy do drogi?→ Zarejestruj się w CometAPI już dziś !
Jeśli chcesz poznać więcej wskazówek, poradników i nowości na temat sztucznej inteligencji, obserwuj nas na VK, X oraz Discord!