

17 czerwca szanghajski jednorożec AI MiniMax oficjalnie udostępnił kod źródłowy MiniMax‑M1, pierwszy na świecie otwarty, wielkoskalowy hybrydowy model wnioskowania uwagi. Łącząc architekturę Mixture‑of‑Experts (MoE) z nowym mechanizmem Lightning Attention, MiniMax‑M1 zapewnia znaczące korzyści w szybkości wnioskowania, obsłudze bardzo długiego kontekstu i wydajności złożonych zadań.
Tło i ewolucja
Budowanie na fundamencie MiniMax-Tekst-01, który wprowadził błyskawiczną uwagę na ramy Mixture-of-Experts (MoE) w celu osiągnięcia kontekstów 1 miliona tokenów podczas szkolenia i do 4 milionów tokenów podczas wnioskowania, MiniMax-M1 reprezentuje następną generację serii MiniMax-01. Poprzedni model, MiniMax-Text-01, zawierał 456 miliardów całkowitych parametrów z 45.9 miliarda aktywowanych na token, demonstrując wydajność porównywalną z najlepszymi LLM, jednocześnie znacznie rozszerzając możliwości kontekstowe.
Główne cechy MiniMax‑M1
- Hybrydowy MoE + Lightning Attention: MiniMax‑M1 łączy w sobie rzadką konstrukcję Mixture‑of‑Experts — 456 miliardów parametrów w sumie, ale tylko 45.9 miliarda aktywowanych na token — z Lightning Attention, liniowo złożoną uwagą zoptymalizowaną pod kątem bardzo długich sekwencji.
- Bardzo długi kontekst: Obsługuje do 1 milionów tokenów wejściowych — około osiem razy większych niż limit 128 K w DeepSeek‑R1 — umożliwiających głębokie zrozumienie obszernych dokumentów.
- Doskonała wydajność: Podczas generowania 100 tys. tokenów funkcja Lightning Attention procesora MiniMax‑M1 wymaga jedynie ~25–30% mocy obliczeniowej wykorzystywanej przez procesor DeepSeek‑R1.
Warianty modelu
- MiniMax‑M1‑40K: 1 kontekst tokena M, budżet wnioskowania tokena 40 K
- MiniMax‑M1‑80K: 1 kontekst tokena M, budżet wnioskowania tokena 80 K
W scenariuszach wykorzystania narzędzi TAU wariant 40K przewyższył wszystkie modele o otwartej konstrukcji, w tym Gemini 2.5 Pro, wykazując się możliwościami agenta.
Koszt szkolenia i konfiguracja
MiniMax-M1 został wytrenowany od początku do końca przy użyciu uczenia wzmacniającego na dużą skalę (RL) w zróżnicowanym zestawie zadań — od zaawansowanego rozumowania matematycznego po środowiska inżynierii oprogramowania oparte na piaskownicy. Nowy algorytm, CISPO (Clipped Importance Sampling for Policy Optimization) dodatkowo zwiększa wydajność szkolenia poprzez przycinanie wag próbkowania ważności zamiast aktualizacji na poziomie tokena. To podejście, w połączeniu z błyskawiczną uwagą modelu, pozwoliło na ukończenie pełnego szkolenia RL na 512 procesorach graficznych H800 w ciągu zaledwie trzech tygodni przy całkowitym koszcie wynajmu $534,700.
Dostępność i ceny
MiniMax-M1 jest wydawany pod nazwą Apache 2.0 licencja open-source i jest natychmiast dostępna za pośrednictwem:
- Repozytorium GitHub, w tym wagi modeli, skrypty szkoleniowe i testy porównawcze oceny.
- SiliconCloud hosting, oferujący dwa warianty — 40 tys. tokenów („M1‑40K”) i 80 tys. tokenów („M1‑80K”) — z planami umożliwienia pełnego lejka tokenów 1 mln.
- Obecnie obowiązująca cena wynosi 4 jeny za milion tokeny do wprowadzania danych i 16 jeny za milion tokenów za produkcję, z rabatami ilościowymi dostępnymi dla klientów korporacyjnych.
Deweloperzy i organizacje mogą integrować MiniMax-M1 za pośrednictwem standardowych interfejsów API, dostrajać dane specyficzne dla domeny lub wdrażać lokalnie w przypadku poufnych obciążeń.
Wydajność na poziomie zadań
| Kategoria zadania | Atrakcja | Względna wydajność |
|---|---|---|
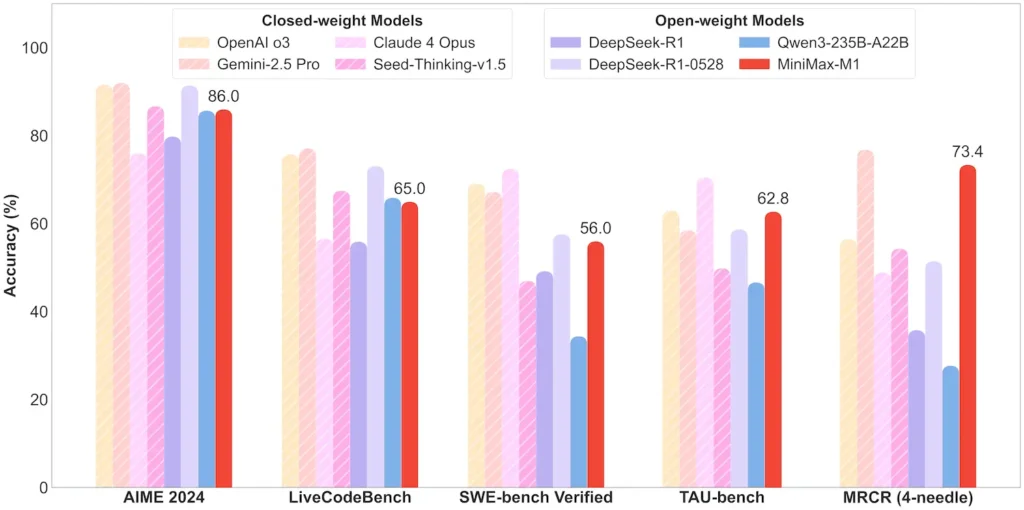
| Matematyka i logika | AIME 2024: 86.0% | > Qwen 3, DeepSeek‑R1; niemal zamknięte źródło |
| Rozumienie długiego kontekstu | Władca (4 żetony K–1 M): Stabilny najwyższy poziom | Wykazuje lepsze wyniki niż GPT‑4 przy długości tokena powyżej 128 K |
| Inżynieria oprogramowania | SWE‑bench (prawdziwe błędy GitHub): 56% | Najlepszy wśród modeli otwartych; 2. po wiodących modelach zamkniętych |
| Wykorzystanie agenta i narzędzia | TAU‑bench (symulacja API) | 62–63.5% w porównaniu z Bliźniakami 2.5, Claude 4 |
| Dialog i Asystent | MultiChallenge: 44.7% | Pasuje do Claude 4, DeepSeek‑R1 |
| Fakt QA | ProsteQA: 18.5% | Obszar przyszłej poprawy |
Uwaga: procenty i wartości odniesienia pochodzą z oficjalnych informacji MiniMax i niezależnych doniesień prasowych
Innowacje techniczne
- Hybrydowy stos uwagi: Błyskawica Uwaga warstwy (koszt liniowy) przeplatane okresową uwagą Softmax (kwadratową, ale bardziej wyrazistą) w celu zrównoważenia wydajności i mocy modelowania.
- Rzadkie trasowanie MoE:32 moduły eksperckie; każdy token aktywuje tylko ~10% wszystkich parametrów, co zmniejsza koszty wnioskowania, a jednocześnie zachowuje przepustowość.
- CISPO Wzmocnienie uczenia się:Nowy algorytm „Clipped IS‑weight Policy Optimization”, który zachowuje rzadkie, ale kluczowe tokeny w sygnale uczącym, przyspieszając stabilność i szybkość RL.
Otwarta wersja MiniMax‑M1 umożliwia każdemu dostęp do niezwykle długiego kontekstu i wysoce wydajnego wnioskowania, wypełniając lukę między badaniami a wdrażalną sztuczną inteligencją na dużą skalę.
Jak zacząć
CometAPI zapewnia ujednolicony interfejs REST, który agreguje setki modeli AI — w tym rodzinę ChatGPT — w ramach spójnego punktu końcowego, z wbudowanym zarządzaniem kluczami API, limitami wykorzystania i panelami rozliczeniowymi. Zamiast żonglować wieloma adresami URL dostawców i poświadczeniami.
Na początek zapoznaj się z możliwościami modeli w Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API.
Najnowsza integracja MiniMax‑M1 API wkrótce pojawi się w CometAPI, więc bądźcie czujni! Podczas gdy finalizujemy przesyłanie modelu MiniMax‑M1, zapoznaj się z naszymi innymi modelami na Strona modeli lub wypróbuj je w Plac zabaw AINajnowszy model MiniMax w CometAPI to Minimax ABAB7-Podgląd API oraz Interfejs API MiniMax Video-01 ,odnieś się do:
