Gemini 2.5 Flash został zaprojektowany tak, aby dostarczać szybkie odpowiedzi bez kompromisu w jakości wyników. Obsługuje wejścia multimodalne, w tym tekst, obrazy, audio i wideo, dzięki czemu nadaje się do różnorodnych zastosowań. Model jest dostępny na platformach takich jak Google AI Studio i Vertex AI, zapewniając deweloperom narzędzia niezbędne do bezproblemowej integracji z różnymi systemami.
Podstawowe informacje (funkcje)
Gemini 2.5 Flash wprowadza kilka wyróżniających się funkcji, które odróżniają go w rodzinie Gemini 2.5:
- Hybrydowe rozumowanie: Deweloperzy mogą ustawić parametr thinking_budget, aby precyzyjnie kontrolować, ile tokenów model przeznacza na wewnętrzne rozumowanie przed wygenerowaniem odpowiedzi.
- Granica Pareto: Umieszczony w optymalnym punkcie koszt–wydajność, Flash oferuje najlepszy stosunek ceny do inteligencji wśród modeli 2.5.
- Obsługa multimodalna: Natywnie przetwarza tekst, obrazy, wideo i audio, umożliwiając bogatsze możliwości konwersacyjne i analityczne.
- Kontekst 1 miliona tokenów: Niezrównana długość kontekstu pozwala na dogłębną analizę i rozumienie długich dokumentów w jednym żądaniu.
Wersjonowanie modelu
Gemini 2.5 Flash przeszedł przez następujące kluczowe wersje:
- gemini-2.5-flash-lite-preview-09-2025: Zwiększona użyteczność narzędzi: poprawiona wydajność w złożonych, wieloetapowych zadaniach, ze wzrostem wyników SWE-Bench Verified o 5% (z 48.9% do 54%). Zwiększona efektywność: po włączeniu rozumowania uzyskiwana jest wyższa jakość wyników przy mniejszej liczbie tokenów, co redukuje latencję i koszty.
- Preview 04-17: Wydanie we wczesnym dostępie z funkcją „thinking”, dostępne poprzez gemini-2.5-flash-preview-04-17.
- Stabilna dostępność ogólna (GA): Od 17 czerwca 2025 stabilny endpoint gemini-2.5-flash zastępuje wersję preview, zapewniając niezawodność klasy produkcyjnej bez zmian w API względem wersji z 20 maja.
- Wycofywanie wersji preview: Endpointy preview zaplanowano do wyłączenia 15 lipca 2025; użytkownicy muszą przejść na endpoint GA przed tą datą.
Od lipca 2025 Gemini 2.5 Flash jest publicznie dostępny i stabilny (bez zmian względem gemini-2.5-flash-preview-05-20 ). Jeśli używasz gemini-2.5-flash-preview-04-17, dotychczasowe ceny wersji preview będą obowiązywać do planowanego wycofania endpointu modelu 15 lipca 2025, kiedy zostanie on wyłączony. Możesz przejść na ogólnodostępny model "gemini-2.5-flash" .
Szybszy, tańszy, mądrzejszy:
- Cele projektowe: niska latencja + wysoka przepustowość + niski koszt;
- Ogólne przyspieszenie w rozumowaniu, przetwarzaniu multimodalnym i zadaniach na długich tekstach;
- Zużycie tokenów zmniejszone o 20–30%, co znacząco obniża koszty rozumowania.
Specyfikacja techniczna
Okno kontekstu wejściowego: do 1 miliona tokenów, co pozwala na rozbudowaną retencję kontekstu.
Tokeny wyjściowe: możliwość generowania do 8,192 tokenów na odpowiedź.
Obsługiwane modalności: tekst, obrazy, audio i wideo.
Platformy integracji: dostępny przez Google AI Studio i Vertex AI.
Cennik: konkurencyjny model rozliczeń oparty na tokenach, ułatwiający efektywne kosztowo wdrożenia.
Szczegóły techniczne
Pod maską Gemini 2.5 Flash to duży model językowy oparty na architekturze transformer, trenowany na mieszance danych z sieci, kodu, obrazów i wideo. Kluczowe techniczne specyfikacje obejmują:
Trening multimodalny: Wytrenowany do łączenia wielu modalności, Flash może płynnie zestawiać tekst z obrazami, wideo lub audio, co jest przydatne w zadaniach takich jak podsumowywanie wideo czy opisy audio.
Dynamiczny proces myślenia: Implementuje wewnętrzną pętlę rozumowania, w której model planuje i rozbija złożone polecenia przed finalnym wynikiem.
Konfigurowalne budżety myślenia: thinking_budget można ustawić od 0 (brak rozumowania) do 24,576 tokenów, umożliwiając kompromis między latencją a jakością odpowiedzi.
Integracja narzędzi: Obsługuje Grounding with Google Search, Code Execution, URL Context i Function Calling, umożliwiając wykonywanie działań w świecie rzeczywistym bezpośrednio z poleceń w języku naturalnym.
Wydajność w benchmarkach
W rygorystycznych ewaluacjach Gemini 2.5 Flash demonstruje wiodącą w branży wydajność:
- LMArena Hard Prompts: Wynik ustępujący jedynie 2.5 Pro w wymagającym benchmarku Hard Prompts, pokazujący silne możliwości wieloetapowego rozumowania.
- Wynik MMLU 0.809: Przewyższa średnią wydajność modeli z dokładnością MMLU 0.809, odzwierciedlając szeroką wiedzę dziedzinową i zdolności rozumowania.
- Opóźnienie i przepustowość: Osiąga prędkość dekodowania 271.4 tokenów/s przy 0.29 s Time-to-First-Token, co czyni go idealnym dla obciążeń wrażliwych na latencję.
- Lider cena–wydajność: Przy $0.26/1 M tokenów Flash wyprzedza wielu konkurentów kosztowo, dorównując im lub przewyższając ich w kluczowych benchmarkach.
Wyniki te wskazują na przewagę konkurencyjną Gemini 2.5 Flash w zakresie rozumowania, rozumienia naukowego, rozwiązywania problemów matematycznych, kodowania, interpretacji wizualnej i wielojęzyczności:
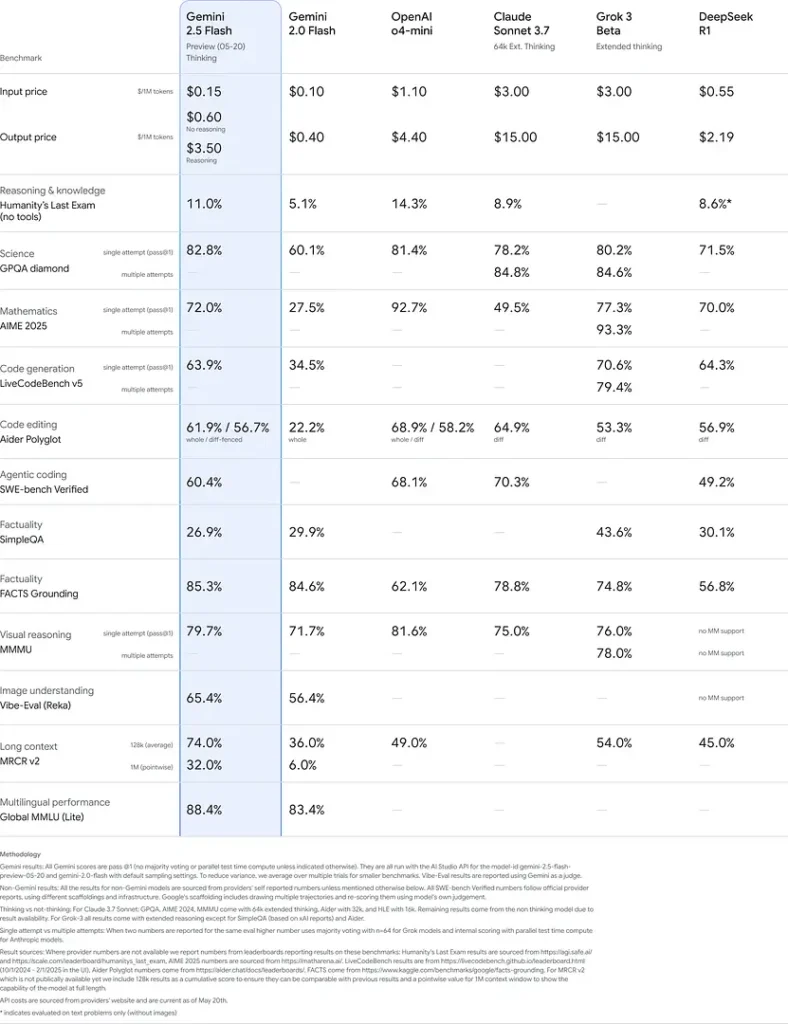
Ograniczenia
- Ryzyka związane z bezpieczeństwem: Model może przejawiać pouczający ton i generować wiarygodnie brzmiące, lecz niepoprawne lub stronnicze odpowiedzi (halucynacje), szczególnie w zapytaniach brzegowych. Rygorystyczny nadzór człowieka pozostaje niezbędny.
- Limity zapytań: Użycie API ograniczają limity (10 RPM, 250,000 TPM, 250 RPD w domyślnych progach), co może wpływać na przetwarzanie wsadowe lub zastosowania o dużym wolumenie.
- Dolny pułap inteligencji: Choć wyjątkowo zdolny jak na model flash, pozostaje mniej dokładny niż 2.5 Pro w najbardziej wymagających zadaniach agencyjnych, takich jak zaawansowane kodowanie czy koordynacja wielu agentów.
- Kompromisy kosztowe: Mimo najlepszego stosunku cena–wydajność, intensywne użycie trybu thinking zwiększa całkowite zużycie tokenów, podnosząc koszty dla zadań wymagających głębokiego rozumowania.