Szczegóły techniczne
- Adaptacyjne rozumowanie:
Gemini 2.5 Flash-Liteobsługuje rozumowanie na żądanie, umożliwiając deweloperom przydzielanie zasobów obliczeniowych tylko wtedy, gdy wymagane jest głębsze rozumowanie. - Integracje narzędzi: Pełna kompatybilność z natywnymi narzędziami Gemini 2.5, w tym Grounding with Google Search, Code Execution, URL Context i Function Calling, dla płynnych, multimodalnych przepływów pracy.
- Model Context Protocol (MCP): Wykorzystuje MCP firmy Google do pobierania danych z sieci w czasie rzeczywistym, zapewniając odpowiedzi aktualne i kontekstowo trafne.
- Opcje wdrożenia: Dostępny za pośrednictwem CometAPI, Gemini API, Vertex AI i Google AI Studio, z kanałem wersji preview dla wczesnych użytkowników do eksperymentów i przekazywania opinii.
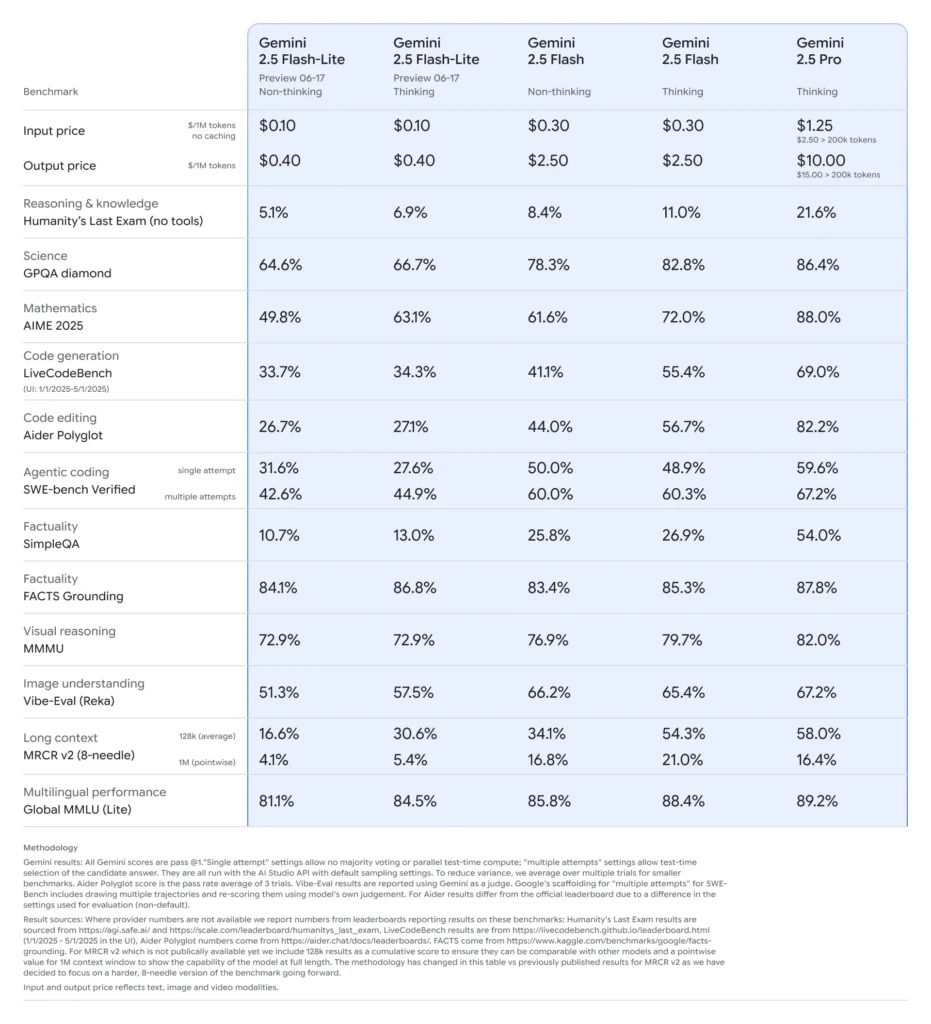
Wydajność w benchmarkach modelu Gemini 2.5 Flash-Lite
- Opóźnienie: Osiąga do 50% niższy medianowy czas odpowiedzi w porównaniu z Gemini 2.5 Flash, z typowymi opóźnieniami poniżej 100 ms w standardowych benchmarkach klasyfikacji i streszczania.
- Przepustowość: Zoptymalizowany pod kątem wysokiej skali, utrzymuje dziesiątki tysięcy żądań na minutę bez degradacji wydajności.
- Koszt/wydajność: Wykazuje 25% redukcję kosztu na 1,000 tokenów względem wariantu Flash, co czyni go wyborem Pareto-optymalnym dla wdrożeń wrażliwych na koszty.
- Adopcja w branży: Pierwsi użytkownicy zgłaszają bezproblemową integrację z produkcyjnymi potokami, a metryki wydajności są zgodne z początkowymi założeniami lub je przewyższają.
Idealne przypadki użycia
- Zadania o wysokiej częstotliwości i niskiej złożoności: automatyczne tagowanie, analiza nastrojów i tłumaczenie masowe
- Potoki wrażliwe na koszty: ekstrakcja danych z dużych korpusów dokumentów, okresowe wsadowe streszczanie
- Scenariusze brzegowe i mobilne: gdy opóźnienie jest krytyczne, a budżet zasobów ograniczony
Ograniczenia modelu Gemini 2.5 Flash-Lite
- Status wersji preview: Przed GA interfejs API może ulec zmianie; integracje powinny uwzględniać możliwe skoki wersji.
- Brak strojenia w locie: Nie można wgrywać własnych wag; należy polegać na inżynierii promptów i komunikatach systemowych.
- Ograniczona kreatywność: Dostosowany do deterministycznych zadań o wysokiej przepustowości; mniej odpowiedni do otwartej generacji lub „kreatywnego” pisania.
- Limit zasobów: Skaluje się liniowo tylko do ~16 vCPUs; powyżej tego zyski w przepustowości maleją.
- Ograniczenia multimodalne: Obsługuje wejścia obraz/dźwięk, ale z ograniczoną wiernością; nie jest idealny do ciężkich zadań wizji ani transkrypcji audio.
- Kompromis okna kontekstu : Mimo że akceptuje do 1 M tokenów, praktyczne wnioskowanie na taką skalę może skutkować obniżoną przepustowością.