Specyfikacja techniczna GPT-5.4 Mini
| Element | GPT-5.4 Mini (szacunek na podstawie informacji oficjalnych + weryfikacji krzyżowej) |
|---|---|
| Rodzina modelu | seria GPT-5.4 (ekonomiczny wariant “mini”) |
| Dostawca | OpenAI |
| Typy wejścia | Text, Image |
| Typy wyjścia | Text |
| Okno kontekstu | 400,000 tokens |
| Maks. tokenów wyjściowych | 128,000 tokens |
| Granica wiedzy | ~31 maja 2024 (dziedziczy rodowód mini) |
| Wsparcie rozumowania | Tak (lekka wersja vs pełne GPT-5.4) |
| Obsługa narzędzi | Wywoływanie funkcji, wyszukiwanie w sieci, wyszukiwanie plików, agenci (wnioskowane na podstawie rodziny GPT-5) |
| Pozycjonowanie | Szybki, ekonomiczny model bliski czołówce |
Czym jest GPT-5.4 Mini?
GPT-5.4 Mini to kosztowo efektywny, wysokoszybki wariant GPT-5.4 zaprojektowany z myślą o obciążeniach wrażliwych na opóźnienia i o dużej skali. Przenosi znaczną część możliwości rozumowania, kodowania i pracy multimodalnej GPT-5.4 do mniejszego, szybszego modelu zoptymalizowanego pod systemy produkcyjne.
W porównaniu z wcześniejszymi modelami „mini” GPT-5.4 Mini jest pozycjonowany jako mały model bliski czołówce, czyli zbliżający się do wydajności flagowców przy dramatycznie niższych kosztach i czasie odpowiedzi.
Kluczowe funkcje GPT-5.4 Mini
- Szybka inferencja: zoptymalizowana pod niskie opóźnienia w aplikacjach takich jak chatboty, copiloty i systemy czasu rzeczywistego
- Duże okno kontekstu (400K): obsługa długich dokumentów, wieloetapowych przepływów i pamięci agenta
- Mocne wsparcie kodowania i agentów: zaprojektowany do użycia narzędzi, wieloetapowego rozumowania i zadań delegowanych subagentom
- Multimodalne wejście: akceptuje zarówno tekst, jak i obrazy dla bogatszych przepływów pracy
- Skalowanie w dobrym stosunku kosztów do efektów: znacznie tańszy niż GPT-5.4, przy zachowaniu silnych zdolności rozumowania
- Optymalizacja potoku agentów: idealny do architektur wielomodelowych, gdzie duże modele planują, a mini wykonują
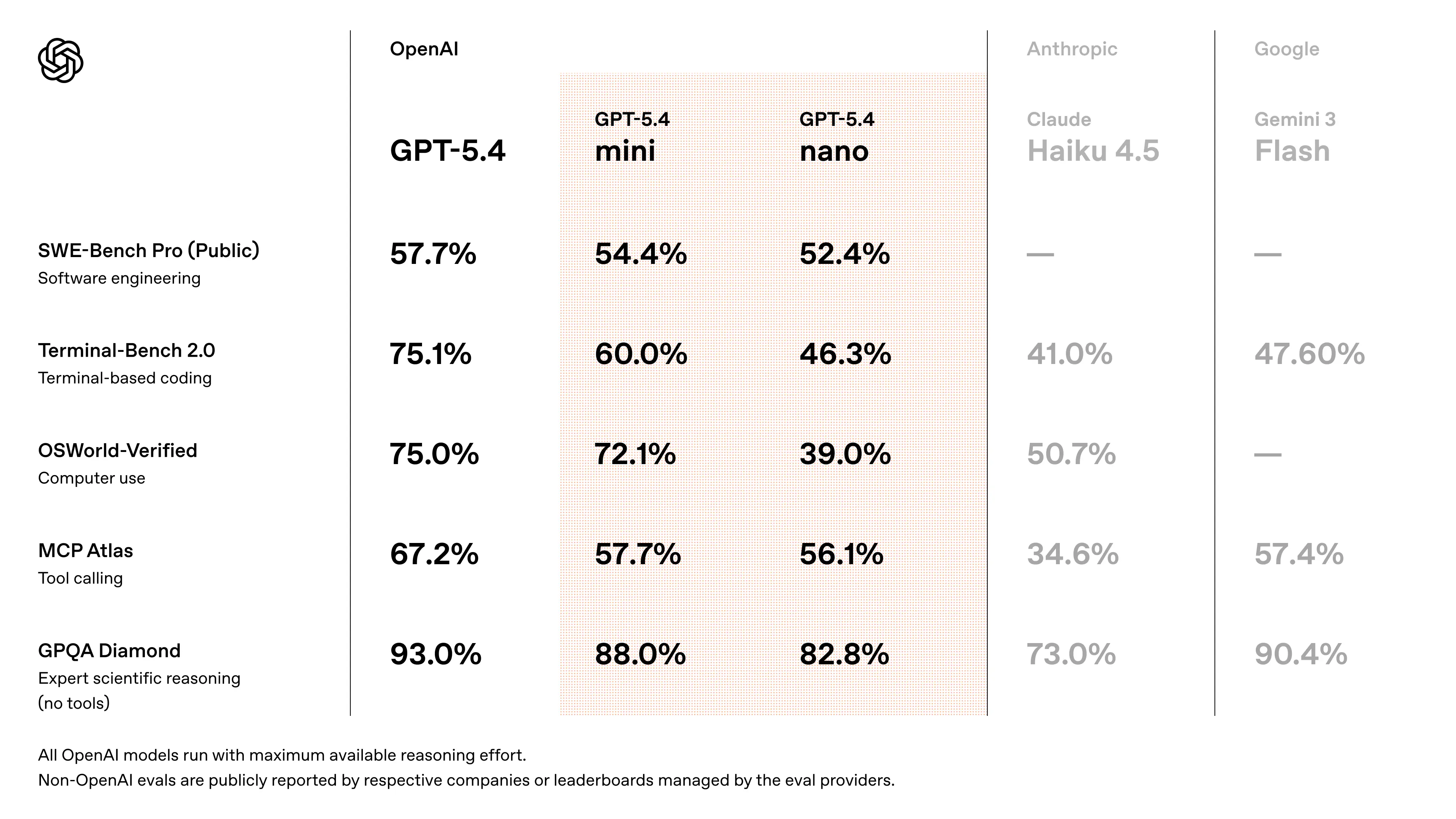
Wydajność w benchmarkach GPT-5.4 Mini
- Zbliża się do wydajności GPT-5.4 w zadaniach kodowania w stylu SWE-Bench (~94–95% osiągów modelu flagowego) (szacunek krzyżowo weryfikowany na podstawie dyskusji wydaniowych)
- Znaczące poprawy względem GPT-5 Mini w:
- dokładności rozumowania
- niezawodności użycia narzędzi
- rozumieniu multimodalnym
- Zaprojektowany, by przewyższać wcześniejsze generacje „mini” w przepływach agentowych i benchmarkach kodowania
- pomiary prędkości: pierwsi testerzy API raportują ~180–190 tokenów/s dla GPT-5.4 Mini (vs ~55–120 t/s dla starszych wariantów GPT-5 mini w zależności od trybów priorytetowych).
👉 Najważniejsze: GPT-5.4 Mini zapewnia wydajność bliską czołówce przy ułamku kosztów i opóźnień, co czyni go idealnym do skalowalnych systemów.
Reprezentatywne przypadki użycia
- Asystenci i edytory kodu (wtyczki IDE, Copilot): szybkie parsowanie kontekstu, eksploracja bazy kodu i szybkie uzupełnienia sprawiają, że GPT-5.4 Mini idealnie nadaje się do podpowiedzi w edytorze, gdzie liczy się czas do pierwszego tokenu. GitHub Copilot to wczesna integracja.
- Subagenci / delegowani pracownicy: gdy główny agent deleguje krótkie, szybkie zadania (formatowanie, małe kroki rozumowania, wyszukiwania w stylu grep) do taniego, szybkiego wykonawcy. OpenAI pozycjonuje mini/nano do tych ról.
- Automatyzacja API o dużej skali: masowe generowanie kodu, automatyczne kategoryzowanie zgłoszeń, podsumowywanie logów na dużą skalę, gdzie kluczowe są koszt na wywołanie i opóźnienie. Liczby wydajności społeczności wskazują na istotne korzyści operacyjne dla mini.
- Opakowywanie narzędzi i łańcuchy narzędziowe: szybkie wywołania narzędzi, w których model orkiestruje połączenia do zewnętrznych narzędzi (wyszukiwanie, grep, uruchamianie testów) i zwraca zwięzłe, praktyczne wyniki. Rodzina GPT-5.4 obejmuje ulepszone możliwości „computer use”.
Jak uzyskać dostęp do API GPT-5.4 Mini
Krok 1: Zarejestruj klucz API
Zaloguj się na cometapi.com. Jeśli nie jesteś jeszcze naszym użytkownikiem, zarejestruj się najpierw. Zaloguj się do swojej konsoli CometAPI. Uzyskaj poświadczenie dostępu — klucz API interfejsu. Kliknij „Add Token” przy tokenie API w centrum osobistym, uzyskaj klucz tokena: sk-xxxxx i zatwierdź.

Krok 2: Wyślij żądania do API GPT-5.4 Mini
Wybierz endpoint „gpt-5.4-mini”, aby wysłać żądanie API, i ustaw body żądania. Metoda i treść żądania są dostępne w dokumentacji API na naszej stronie. Nasza strona udostępnia także test Apifox dla Twojej wygody. Zastąp <YOUR_API_KEY> swoim rzeczywistym kluczem CometAPI z konta. bazowy url to Chat Completions i Responses.
Wstaw swoje pytanie lub prośbę do pola content — to na nią model odpowie. Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź.
Krok 3: Odbierz i zweryfikuj wyniki
Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź. Po przetworzeniu API odpowiada statusem zadania i danymi wyjściowymi.