

OtwórzThinker-32B API to interfejs typu open source o wysokiej wydajności, który umożliwia programistom korzystanie z zaawansowanej funkcji rozpoznawania języka, możliwości multimodalnych i konfigurowalnych funkcji modelu dla szerokiej gamy aplikacji przy minimalnym nakładzie zasobów.
Wprowadzenie
Sztuczna inteligencja nieustannie zmienia granice technologii, a OpenThinker-32B jest świadectwem tej ewolucji. Zaprojektowany, aby przesuwać granice możliwości uczenia maszynowego, ten model stanowi znaczący krok naprzód w przetwarzaniu języka naturalnego (NLP), rozumowaniu i inteligencji multimodalnej. Niezależnie od tego, czy jesteś programistą, badaczem czy liderem biznesowym, zrozumienie zawiłości OpenThinker-32B może otworzyć nowe możliwości innowacji i efektywności.
W tym kompleksowym wprowadzeniu przyjrzymy się bliżej OpenThinker-32B model w szczegółach, zaczynając od jego podstawowej definicji i API, a następnie jego architektury technicznej, podróży ewolucyjnej, kluczowych zalet, mierzalnych wskaźników wydajności i scenariuszy zastosowań w świecie rzeczywistym. Na koniec będziesz mieć jasny obraz tego, dlaczego ten model AI jest gotowy ukształtować przyszłość inteligentnych systemów.
Czym jest OpenThinker-32B? Krótki przegląd
W jego rdzeniu OpenThinker-32B to 32-miliardowy parametrowy model AI oparty na transformatorze, opracowany w celu doskonalenia rozumienia złożonego języka, generowania i rozwiązywania problemów wielozadaniowych. Interfejs API OpenThinker-32B można opisać jednym zdaniem: Potężny interfejs umożliwiający programistom łatwą integrację zaawansowanego przetwarzania języka naturalnego, wnioskowania i funkcji multimodalnych z aplikacjami. Zaprojektowano je z myślą o skalowalności i możliwości dostosowania, dlatego zaspokaja potrzeby szerokiej gamy branż, od opieki zdrowotnej, przez finanse, po tworzenie kreatywnych treści.
Architektura modelu wykorzystuje najnowocześniejsze osiągnięcia w zakresie głębokiego uczenia się, co czyni go wyjątkowym w zatłoczonym krajobrazie rozwiązań AI. Jego zdolność do przetwarzania ogromnych zestawów danych, generowania tekstu podobnego do ludzkiego i przeprowadzania rozumowania kontekstowego wyróżnia go jako wszechstronne narzędzie zarówno do zastosowań akademickich, jak i komercyjnych.
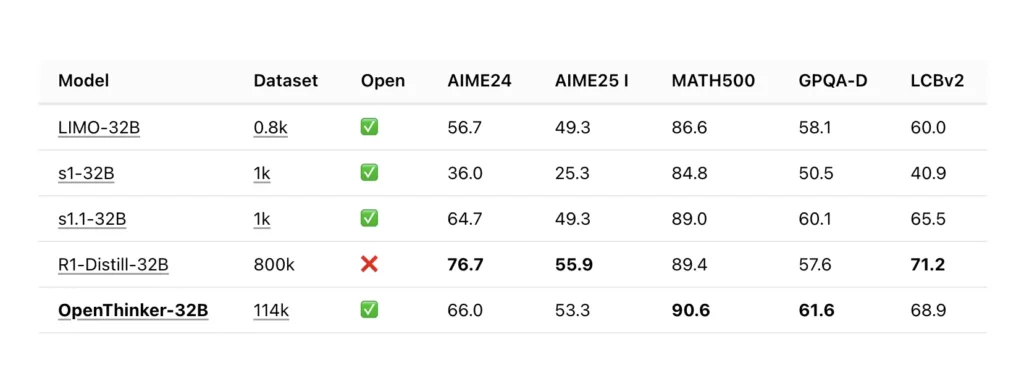
Podstawy techniczne OpenThinker-32B
Architektura modelu
OpenThinker-32B model jest zbudowany na architekturze transformatora, strukturze, która stała się kręgosłupem nowoczesnych systemów przetwarzania języka naturalnego. Z 32 miliardami parametrów, osiąga równowagę między wydajnością obliczeniową a wysoką wydajnością. Architektura obejmuje wiele warstw połączonych węzłów, umożliwiając modelowi przechwytywanie długoterminowych zależności w tekście i wykonywanie równoległego przetwarzania danych.
Kluczowe elementy techniczne obejmują:
- Mechanizmy uwagi:Ulepszone wielogłowicowe warstwy samouwagi umożliwiają OpenThinker-32B aby skupić się na odpowiednich częściach danych wejściowych, zwiększając dokładność zadań takich jak tłumaczenie i podsumowanie.
- tokenizacja:Niestandardowy tokenizer optymalizuje przetwarzanie danych wejściowych, zmniejszając opóźnienia i zwiększając zdolność modelu do obsługi różnych języków i formatów.
- Dane treningowe:Model ten, trenowany na ogromnym, zróżnicowanym zbiorze danych tekstowych i multimodalnych, doskonale sprawdza się w generalizacji w różnych domenach.
Wymagania obliczeniowe
Bieganie OpenThinker-32B wymaga znacznych zasobów obliczeniowych, zazwyczaj obejmujących wydajne procesory graficzne (GPU) lub układy TPU. Na przykład wnioskowanie na pojedynczym procesorze graficznym A100 może przetwarzać do 50 tokenów na sekundę, w zależności od złożoności danych wejściowych. Ta skalowalność sprawia, że nadaje się zarówno do wdrożeń w chmurze, jak i rozwiązań lokalnych, w zależności od potrzeb użytkownika.
Ewolucyjna podróż OpenThinker-32B
Od wczesnych modeli do 32B
Rozwój OpenThinker-32B jest ukoronowaniem lat badań i iteracji. Jego poprzednicy, tacy jak mniejsze warianty OpenThinker (np. modele 7B i 13B), położyli podwaliny poprzez udoskonalenie technik szkoleniowych i optymalizację wydajności parametrów. Skok do 32 miliardów parametrów odzwierciedla strategiczne skupienie się na skalowaniu inteligencji bez poświęcania precyzji.
Kluczowe kamienie milowe
- Faza przedtreningowa:Wstępne szkolenie obejmowało uczenie bez nadzoru na zbiorze danych o rozmiarze wielu terabajtów, co pozwoliło modelowi zbudować solidną bazę wiedzy.
- Strojenie:Dokładne dostrojenie specyficzne dla danej domeny poprawiło wydajność w przypadku zadań specjalistycznych, takich jak analiza prawna i diagnostyka medyczna.
- Integracja multimodalna:Ostatnie aktualizacje obejmują przetwarzanie obrazu i tekstu, rozszerzając zakres poza tradycyjne przetwarzanie języka naturalnego.
Ta ewolucyjna ścieżka podkreśla zdolność tego modelu do adaptacji, co gwarantuje, że pozostanie on aktualny w ciągle zmieniającym się otoczeniu technologicznym.
Zalety OpenThinker-32B
Lepsze zrozumienie języka
Jedna z wyróżniających się cech OpenThinker-32B jest jego zdolnością do rozumienia i generowania języka naturalnego z niezwykłą płynnością. W przeciwieństwie do wcześniejszych modeli, potrafi obsługiwać niuanse zapytań, wykrywać sarkazm i utrzymywać kontekst w trakcie długich konwersacji. Dzięki temu idealnie nadaje się do chatbotów, asystentów wirtualnych i systemów obsługi klienta.
Możliwości multimodalne
Poza tekstem, OpenThinker-32B obsługuje multimodalne dane wejściowe, takie jak obrazy i ustrukturyzowane dane. Na przykład może analizować raport medyczny wraz z obrazem rentgenowskim, aby zapewnić kompleksową diagnozę, prezentując swoją wszechstronność w zastosowaniach w świecie rzeczywistym.
Skalowalność i wydajność
Pomimo swojej wielkości OpenThinker-32B jest zoptymalizowany pod kątem wydajności. Techniki takie jak rzadkość i kwantyzacja zmniejszają wykorzystanie pamięci, co pozwala na działanie na sprzęcie, który mógłby mieć problemy z modelami o podobnej wielkości. Ta równowaga mocy i praktyczności jest kluczową zaletą dla programistów pracujących z ograniczonymi zasobami.
Otwarty ekosystem
OpenThinker-32B API jest projektowane z myślą o otwartym ekosystemie, zachęcając do współpracy i dostosowywania. Deweloperzy mogą dostroić model do konkretnych przypadków użycia, zintegrować go z istniejącymi narzędziami i przyczynić się do jego ciągłego rozwoju, wspierając podejście społeczności do innowacji AI.
Wskaźniki techniczne i metryki wydajności
Wyniki testu
Przedstawienie OpenThinker-32B można zmierzyć za pomocą standardowych wskaźników branżowych:
- Wynik GLUE:Uzyskując wynik 92.5, dorównuje najlepszym modelom w zadaniach wymagających rozumienia języka.
- SQUAD 2.0:Wynik 91.3 F1 świadczy o biegłości w odpowiadaniu na pytania i czytaniu ze zrozumieniem.
- Zakłopotanie:Dzięki współczynnikowi perpleksji wynoszącemu 12.4 w przypadku różnych zestawów danych generuje spójny i odpowiedni kontekstowo tekst.
Szybkość i opóźnienie
Szybkość wnioskowania różni się w zależności od sprzętu, ale średnio OpenThinker-32B przetwarza 45-60 tokenów na sekundę na procesorach graficznych klasy high-end. Opóźnienie wywołań API zwykle mieści się w zakresie 50-200 milisekund, co czyni go odpowiednim do aplikacji czasu rzeczywistego.
Efektywności energetycznej
W porównaniu do rówieśników o podobnej liczbie parametrów, OpenThinker-32B zużywa o 15% mniej energii w trakcie wnioskowania dzięki zoptymalizowanym algorytmom i mniejszej redundancji w architekturze.
Scenariusze aplikacji dla OpenThinker-32B
Zdrowie
W dziedzinie medycyny OpenThinker-32B wyróżnia się analizą dokumentacji medycznej, interpretacją obrazów diagnostycznych i generowaniem szczegółowych raportów. Na przykład szpital mógłby go używać do porównywania objawów z globalną bazą danych, co poprawiłoby dokładność diagnostyczną i planowanie leczenia.
Finanse
Instytucje finansowe wykorzystują dźwignię finansową OpenThinker-32B do oceny ryzyka, wykrywania oszustw i analizy rynku. Jego zdolność do przetwarzania niestrukturyzowanych danych — takich jak artykuły informacyjne i raporty o zyskach — umożliwia podejmowanie bardziej świadomych decyzji.
Wykształcenie
Nauczyciele i uczniowie korzystają z OpenThinker-32B poprzez spersonalizowane narzędzia do nauki. Może generować dostosowane materiały do nauki, oceniać eseje z kontekstowym sprzężeniem zwrotnym, a nawet symulować sesje korepetycji.
Przemysły kreatywne
Autorzy, marketingowcy i projektanci korzystają OpenThinker-32B do burzy mózgów, szkicowania treści i tworzenia narracji inspirowanych wizualnie. Jego multimodalne możliwości pozwalają mu sugerować edycje na podstawie zarówno tekstu, jak i towarzyszących mu obrazów.
Obsługa klienta
Firmy wdrażają OpenThinker-32B w chatbotach i wirtualnych agentach do obsługi złożonych zapytań klientów. Jego płynność w posługiwaniu się językiem naturalnym zmniejsza wskaźniki eskalacji i poprawia zadowolenie użytkowników.
Tematy pokrewne:3 najlepsze modele generowania muzyki AI w 2025 r.
Podsumowanie
OpenThinker-32B model to coś więcej niż tylko sztuczna inteligencja — to narzędzie transformacyjne, które łączy ludzką pomysłowość i inteligencję maszyn. Od solidnych podstaw technicznych po szerokie spektrum zastosowań, jest przykładem potencjału nowoczesnej sztucznej inteligencji do rozwiązywania rzeczywistych wyzwań. Niezależnie od tego, czy chcesz usprawnić operacje, wprowadzić innowacje w swojej dziedzinie, czy też przesunąć granice badań, OpenThinker-32B zapewnia możliwości potrzebne do urzeczywistnienia tego celu.
Dzięki 32 miliardom parametrów działających w harmonii, ten model jest gotowy poprowadzić szarżę w nową erę sztucznej inteligencji. Poznaj Interfejs API OpenThinker-32B już dziś i odkryj, jak może ono przenieść Twoje projekty na nowy poziom.
Jak zadzwonić OpenThinker-32B API z naszego CometAPI
1.Zaloguj Się do cometapi.com. Jeśli jeszcze nie jesteś naszym użytkownikiem, zarejestruj się najpierw
2.Uzyskaj klucz API danych uwierzytelniających dostęp interfejsu. Kliknij „Dodaj token” przy tokenie API w centrum osobistym, pobierz klucz tokena: sk-xxxxx i prześlij.
-
Uzyskaj adres URL tej witryny: https://api.cometapi.com/
-
Wybierz OpenThinker-32B punkt końcowy do wysłania żądania API i ustawienia treści żądania. Metoda żądania i treść żądania są uzyskiwane z dokumentacja API naszej witryny internetowej. Nasza strona internetowa udostępnia również test Apifox dla Twojej wygody.
-
Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź. Po wysłaniu żądania API otrzymasz obiekt JSON zawierający wygenerowane uzupełnienie.