

W szybko ewoluującym krajobrazie sztucznej inteligencji rok 2025 był świadkiem znaczących postępów w dużych modelach językowych (LLM). Wśród faworytów znajdują się Qwen2.5 firmy Alibaba, modele V3 i R1 firmy DeepSeek oraz ChatGPT firmy OpenAI. Każdy z tych modeli wnosi unikalne możliwości i innowacje. W tym artykule zagłębiamy się w najnowsze osiągnięcia dotyczące Qwen2.5, porównując jego funkcje i wydajność z DeepSeek i ChatGPT, aby ustalić, który model obecnie prowadzi w wyścigu AI.
Czym jest Qwen2.5?
Omówienie
Qwen 2.5 to najnowszy gęsty, dekodujący model dużego języka Alibaba Cloud, dostępny w wielu rozmiarach od 0.5B do 72B parametrów. Jest zoptymalizowany pod kątem instrukcji, ustrukturyzowanych wyników (np. JSON, tabele), kodowania i rozwiązywania problemów matematycznych. Dzięki obsłudze ponad 29 języków i długości kontekstu do 128K tokenów, Qwen2.5 jest przeznaczony do aplikacji wielojęzycznych i specyficznych dla danej domeny.
Kluczowe funkcje
- Obsługa wielu języków:Obsługuje ponad 29 języków, zaspokajając potrzeby użytkowników z całego świata.
- Rozszerzona długość kontekstu:Obsługuje do 128 tys. tokenów, umożliwiając przetwarzanie długich dokumentów i konwersacji.
- Warianty specjalistyczne:Zawiera modele takie jak Qwen2.5-Coder do zadań programistycznych i Qwen2.5-Math do rozwiązywania problemów matematycznych.
- Dostępność bez barier:Dostępne na platformach takich jak Hugging Face, GitHub i nowo uruchomionym interfejsie internetowym pod adresem czat.qwenlm.ai.
Jak używać Qwen 2.5 lokalnie?
Poniżej znajduje się przewodnik krok po kroku 7 B Czat punkt kontrolny; większe rozmiary różnią się tylko wymaganiami dotyczącymi procesora graficznego.
1. Wymagania sprzętowe
| Model | vRAM dla 8-bitów | vRAM dla 4-bitów (QLoRA) | Rozmiar dysku |
|---|---|---|---|
| Qwen 2.5‑7B | 14 GB | 10 GB | 13 GB |
| Qwen 2.5‑14B | 26 GB | 18 GB | 25 GB |
Pojedyncza karta RTX 4090 (24 GB) wystarcza do wnioskowania 7 B przy pełnej precyzji 16-bitowej; dwie takie karty lub odciążenie procesora plus kwantyzacja mogą obsłużyć 14 B.
2. Instalacja
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Skrypt szybkiego wnioskowania
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
trust_remote_code=True flaga jest wymagana, ponieważ Qwen wysyła niestandardowy Osadzanie pozycji obrotowej obwoluta.
4. Dokładne dostrajanie za pomocą LoRA
Dzięki wydajnym pod względem parametrów adapterom LoRA możesz przeprowadzić specjalistyczne szkolenie Qwen na około 50 tys. parach domen (np. medycznych) w czasie krótszym niż cztery godziny na jednym procesorze graficznym o pojemności 24 GB:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Powstały plik adaptera (~120 MB) można ponownie scalić lub załadować na żądanie.
Opcjonalnie: Uruchom Qwen 2.5 jako API
CometAPI działa jako scentralizowany hub dla interfejsów API kilku wiodących modeli sztucznej inteligencji, eliminując potrzebę osobnej współpracy z wieloma dostawcami interfejsów API. Interfejs API Comet oferuje cenę znacznie niższą niż oficjalna, aby pomóc Ci zintegrować Qwen API, a po zarejestrowaniu i zalogowaniu otrzymasz 1$ na swoje konto! Zapraszamy do rejestracji i doświadczenia CometAPI. Dla programistów, którzy chcą włączyć Qwen 2.5 do aplikacji:
Krok 1: Zainstaluj niezbędne biblioteki:
bash
pip install requests
Krok 2: uzyskaj klucz API
- Nawigować do Interfejs API Comet.
- Zaloguj się na swoje konto CometAPI.
- Wybierz Panel Użytkownika.
- Kliknij „Uzyskaj klucz API” i postępuj zgodnie z instrukcjami, aby wygenerować klucz.
Krok 3: Wdrażanie wywołań API
Użyj danych uwierzytelniających API, aby wysłać żądania do Qwen 2.5.Zamień za pomocą aktualnego klucza CometAPI ze swojego konta.
Na przykład w Pythonie:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Ta integracja umożliwia bezproblemową integrację możliwości Qwen 2.5 z różnymi aplikacjami, zwiększając ich funkcjonalność i komfort użytkowania.Wybierz “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” punkt końcowy do wysłania żądania API i ustawienia treści żądania. Metoda żądania i treść żądania są pobierane z naszej witryny internetowej API doc. Nasza witryna internetowa udostępnia również test Apifox dla Twojej wygody.
Sprawdź Qwen 2.5 Max API aby uzyskać szczegółowe informacje na temat integracji. CometAPI zaktualizował najnowszą wersję Interfejs API QwQ-32BAby uzyskać więcej informacji o modelu w interfejsie API Comet, zobacz Dokumentacja API.
Najlepsze praktyki i wskazówki
| Scenariusz | Rekomendacja |
|---|---|
| Długi dokument Q&A | Podziel fragmenty na ≤16 tys. tokenów i użyj podpowiedzi z funkcją wyszukiwania zamiast naiwnych kontekstów o rozmiarze 100 tys., aby zmniejszyć opóźnienie. |
| Ustrukturyzowane wyjścia | Wpisz przedrostek do komunikatu systemowego: You are an AI that strictly outputs JSON. Trening wyrównywania Qwen 2.5 sprawdza się znakomicie w przypadku generacji ograniczonej. |
| Uzupełnianie kodu | Zestaw temperature=0.0 oraz top_p=1.0 aby zmaksymalizować determinizm, należy pobrać próbki wielu wiązek (num_return_sequences=4) do rankingu. |
| Filtrowanie bezpieczeństwa | Jako pierwszy krok użyj pakietu wyrażeń regularnych „Qwen‑Guardrails” firmy Alibaba udostępnionego na zasadzie open source lub pakietu text‑moderation‑004 firmy OpenAI. |
Znane ograniczenia Qwen 2.5
- Wrażliwość na natychmiastowe wstrzyknięcie. Zewnętrzne audyty wykazują, że skuteczność jailbreaku na Qwen 18‑VL wynosi 2.5% — co przypomina, że sam rozmiar modelu nie zapewnia odporności na instrukcje przeciwników.
- Szum OCR niełaciński. Po dostosowaniu do zadań związanych z wizją i językiem, kompleksowy proces przetwarzania danych w modelu czasami myli tradycyjne i uproszczone glify chińskie, co wymaga stosowania warstw korekcyjnych specyficznych dla danej domeny.
- Spadek pamięci GPU przy 128 K. FlashAttention‑2 kompensuje pamięć RAM, ale gęste przekazanie 72 B przez 128 K tokenów nadal wymaga >120 GB pamięci vRAM; użytkownicy powinni korzystać z obsługi okna lub pamięci podręcznej KV.
Mapa drogowa i ekosystem społeczności
Zespół Qwen zasugerował Qwen 3.0, ukierunkowane na hybrydowy szkielet routingu (Dense + MoE) i ujednolicone wstępne szkolenie mowy, wizji i tekstu. Tymczasem ekosystem już obsługuje:
- Agent Q – agent łańcucha myśli w stylu ReAct, używający Qwen 2.5‑14B jako polityki.
- Chińska Alpaka Finansowa – LoRA na Qwen2.5‑7B wytrenowana przy użyciu 1 mln zgłoszeń regulacyjnych.
- Wtyczka Open Interpreter – zamienia GPT‑4 na lokalny punkt kontrolny Qwen w VS Code.
Sprawdź stronę Hugging Face „Qwen2.5 collection”, aby zapoznać się z ciągle aktualizowaną listą punktów kontrolnych, adapterów i pakietów ewaluacyjnych.
Analiza porównawcza: Qwen2.5 kontra DeepSeek i ChatGPT
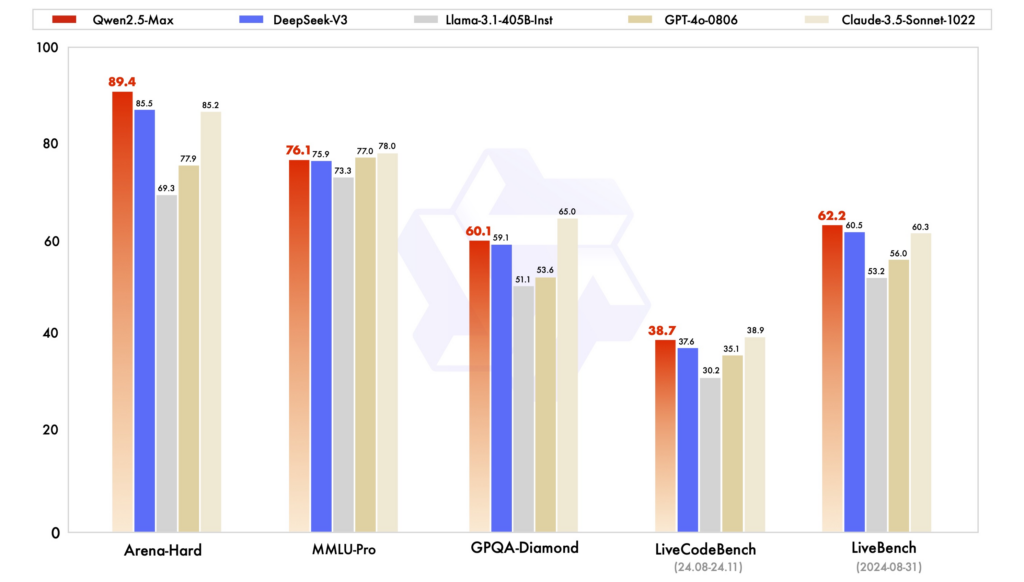
Testy wydajności: W różnych ocenach Qwen2.5 wykazał się wysoką wydajnością w zadaniach wymagających rozumowania, kodowania i wielojęzycznego zrozumienia. DeepSeek-V3, z architekturą MoE, wyróżnia się wydajnością i skalowalnością, zapewniając wysoką wydajność przy zmniejszonych zasobach obliczeniowych. ChatGPT pozostaje solidnym modelem, szczególnie w zadaniach języka ogólnego przeznaczenia.
Wydajność i koszt: Modele DeepSeek wyróżniają się opłacalnym szkoleniem i wnioskowaniem, wykorzystując architekturę MoE do aktywowania tylko niezbędnych parametrów na token. Qwen2.5, choć gęsty, oferuje specjalistyczne warianty w celu optymalizacji wydajności dla określonych zadań. Szkolenie ChatGPT wymagało znacznych zasobów obliczeniowych, co odzwierciedla się w jego kosztach operacyjnych.
Dostępność i dostępność Open Source: Qwen2.5 i DeepSeek w różnym stopniu przyjęły zasady Open Source, a modele są dostępne na platformach takich jak GitHub i Hugging Face. Niedawne uruchomienie interfejsu internetowego Qwen2.5 zwiększa jego dostępność. ChatGPT, choć nie jest open source, jest szeroko dostępny za pośrednictwem platformy i integracji OpenAI.
Podsumowanie
Qwen 2.5 znajduje się w idealnym miejscu pomiędzy usługi premium o zamkniętym ciężarze oraz w pełni otwarte modele hobbystycznePołączenie liberalnego licencjonowania, wielojęzycznej mocy, kompetencji w zakresie długiego kontekstu i szerokiego zakresu skal parametrów sprawia, że jest to przekonująca podstawa zarówno do badań, jak i produkcji.
W miarę jak krajobraz programów LLM opartych na otwartym kodzie źródłowym pędzi naprzód, projekt Qwen pokazuje, że przejrzystość i wydajność mogą współistniećZarówno dla programistów, naukowców zajmujących się danymi, jak i decydentów politycznych opanowanie Qwen 2.5 jest dziś inwestycją w bardziej pluralistyczną, przyjazną innowacjom przyszłość AI.