

Qwen2.5-VL-32B API zyskało uwagę dzięki swojemu wyjątkowa wydajność w różnorodnych złożonych zadaniach, łączących oba dane obrazowe i tekstowe dla bogatszego zrozumienia świata. Opracowane przez Alibabaten 32-miliardowy model parametrów jest ulepszeniem wcześniejszego Qwen2.5-VL seria, przesuwająca granice Rozumowanie oparte na sztucznej inteligencji oraz rozumienie wizualne.

Przegląd Qwen2.5-VL-32B
Qwen2.5-VL-32B to najnowocześniejszy, multimodalny model typu open source zaprojektowany do obsługi szeregu zadań obejmujących zarówno tekst, jak i obrazy. Dzięki 32 miliarda parametrów, oferuje m.in potężna architektura dla rozpoznawanie obrazu, rozumowanie matematyczne, generowanie dialogui wiele więcej. Jego ulepszona możliwości uczenia się, oparte na uczeniu maszynowym, pozwalają mu generować odpowiedzi, które lepiej odpowiadają ludzkim preferencjom.
Kluczowe cechy i funkcje
Qwen2.5-VL-32B wykazuje niezwykłe możliwości w wielu obszarach:
Zrozumienie i opis obrazu:Ten model wyróżnia się Analiza obrazu, dokładnie identyfikując obiekty i sceny. Może generować szczegółowe opisy w języku naturalnym, a nawet zapewniać szczegółowe spostrzeżenia na atrybuty obiektu i ich relacje.
Rozumowanie matematyczne i logikaModel jest wyposażony w funkcje rozwiązywania złożonych problemów matematycznych, od geometria do algebry—zatrudniając rozumowanie wieloetapowe z jasną logiką i ustrukturyzowanymi wynikami.
Generowanie tekstu i dialog:Dzięki zaawansowanemu modelowi językowemu Qwen2.5-VL-32B generuje spójne i kontekstowo istotne odpowiedzi na podstawie tekstu wejściowego lub obrazów. Obsługuje również dialog wieloetapowy, umożliwiając bardziej naturalne i ciągłe interakcje.
Wizualne odpowiadanie na pytania:Model może odpowiadać na pytania związane z treścią obrazu, takie jak: Rozpoznawanie obiektów oraz opis sceny, zapewniając zaawansowane możliwości wizualnej logiki i wnioskowania.
Podstawy techniczne Qwen2.5-VL-32B
Aby zrozumieć moc Qwen2.5-VL-32B, kluczowe jest zbadanie jego zasad technicznych. Poniżej przedstawiono kluczowe aspekty, które wpływają na jego wydajność:
- Multimodalne szkolenie wstępne:Model został wstępnie wytrenowany przy użyciu zbiory danych na dużą skalę składający się z obu dane tekstowe i graficzneDzięki temu może uczyć się różnych cech wizualnych i językowych, ułatwiając bezproblemowe rozumienie międzymodalne.
- Architektura transformatora:Zbudowany na solidnej konstrukcji Architektura transformatoramodel wykorzystuje zarówno koder oraz dekoder struktury do przetwarzania obrazów i tekstów wejściowych, generujące bardzo dokładne wyniki. Jego mechanizm samouwagi pozwala skupić się na krytycznych elementach danych wejściowych, zwiększając ich precyzję.
- Optymalizacja uczenia się przez wzmacnianie: Qwen2.5-VL-32B korzysta z uczenia wzmacniającego, gdzie jest dostrajany na podstawie ludzkiej informacji zwrotnej. Ten proces zapewnia, że odpowiedzi modelu są bardziej zgodny z preferencjami człowieka optymalizując jednocześnie wiele celów, takich jak: precyzja, logika, płynność.
- Dopasowanie wizualno-językowe: Przez uczenie kontrastowe i strategie dopasowania, model zapewnia, że oba cechy wizualne oraz informacje tekstowe są prawidłowo zintegrowane w przestrzeń językowa, co czyni go niezwykle skutecznym w zadania multimodalne.
Najważniejsze cechy
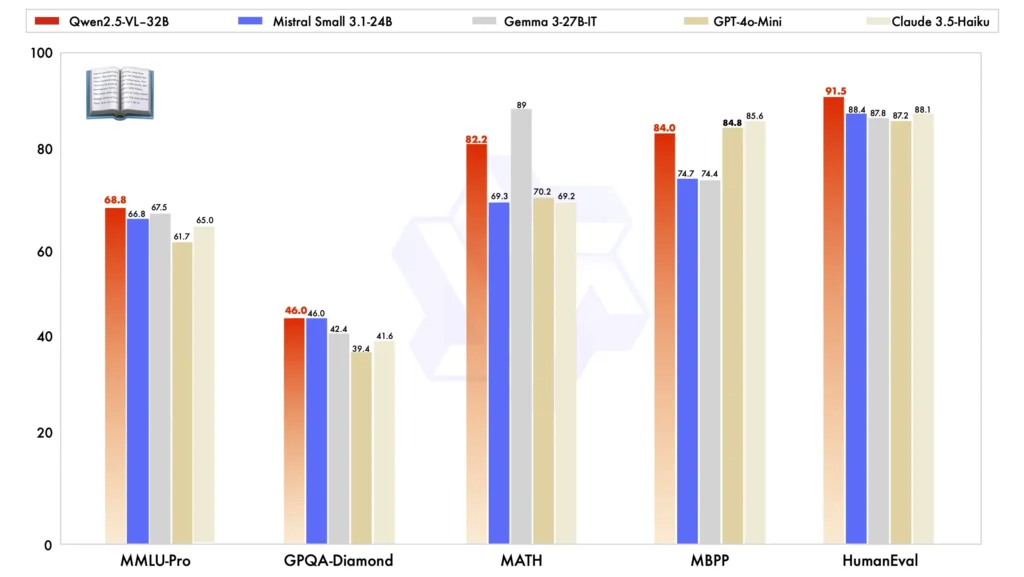
W porównaniu z innymi modelami o dużej skali Qwen2.5-VL-32B wyróżnia się w kilku kluczowych testach porównawczych, prezentując swoje lepsza wydajność zarówno multimodalny oraz zadania tekstowe:
Porównanie modeli:W porównaniu z innymi modelami, takimi jak Mistral-Mały-3.1-24B oraz Gemma-3-27B-IT, Qwen2.5-VL-32B wykazuje znacznie ulepszone możliwości. Co ciekawe, nawet przewyższa większy Qwen2-VL-72B w różnych zadaniach.
Wydajność zadań multimodalnych:W złożonym zadania multimodalne jak na przykład MMMU, MMMU-Pro, MatematykaVistaQwen2.5-VL-32B wyróżnia się precyzją wykonania, która wyróżnia go na tle innych modeli o podobnych rozmiarach.
MM-MT-Bench Test porównawczy:W porównaniu do swojego poprzednika, Qwen2-VL-72B-Instruct, nowa wersja wykazuje znaczną poprawę, szczególnie w zakresie logiczne rozumowanie oraz rozumowanie multimodalne możliwości.
Wydajność zwykłego tekstu:W zadaniach opartych na zwykłym tekście Qwen2.5-VL-32B stał się najlepszy wykonawca w swojej klasie, oferując ulepszone generowanie tekstu, rozumowaniei ogólną dokładność.
Zasoby projektu
Dla programistów i entuzjastów sztucznej inteligencji, którzy chcą bliżej poznać Qwen2.5-VL-32B, dostępnych jest kilka ważnych źródeł:
- Oficjalna strona internetowa: Projekt Qwen2.5-VL-32B
- Model HuggingFace: HuggingFace Qwen2.5-VL-32B-Instrukcja
Aplikacje w świecie rzeczywistym
Wszechstronność Qwen2.5-VL-32B sprawia, że nadaje się do szerokiej gamy zastosowań praktyczne zastosowania w różnych branżach:
Inteligentna obsługa klienta:Model można wykorzystać do automatycznej obsługi zapytań klientów, wykorzystując jego zdolność do rozumienia i generowania odpowiedzi oparte na tekście i obrazach.
Pomoc edukacyjna:Rozwiązując problemy matematyczne, interpretacja treść obrazui wyjaśnianie pojęć może znacznie usprawnić proces uczenia się uczniów.
Adnotacja obrazu:W systemach zarządzania treścią Qwen2.5-VL-32B może automatyzować generowanie podpisy graficzne oraz Opisy, co czyni je nieocenionym narzędziem dla mediów i przemysłu kreatywnego.
Autonomiczna jazda:Analizując znaki drogowe i warunki ruchu drogowego za pomocą swoich możliwości przetwarzania obrazu, model może zapewnić wgląd w czasie rzeczywistym w celu poprawy bezpieczeństwo jazdy.
Tworzenie treściW mediach i reklamie model ten może generować XNUMX oparta na bodźcach wizualnych, pomagająca twórcom treści w tworzeniu wciągających narracji do filmów wideo i reklam.
Przyszłe perspektywy i wyzwania
Chociaż Qwen2.5-VL-32B stanowi ogromny krok naprzód w dziedzinie multimodalnej sztucznej inteligencji, przed firmą nadal stoją wyzwania i możliwości. Strojenie model do bardziej szczegółowych zadań, integrując go z aplikacjami czasu rzeczywistego i ulepszając jego skalowalność Aby poradzić sobie ze złożonymi zbiorami danych multimodalnych, konieczne są ciągłe prace badawczo-rozwojowe.
Co więcej, w miarę jak pojawia się coraz więcej modeli sztucznej inteligencji o podobnych możliwościach, obawy etyczne wokół treści generowanych przez sztuczną inteligencję, stronniczość, prywatność danych nadal przyciągać uwagę. Zapewnienie, że Qwen2.5-VL-32B i podobne modele są szkolone i wykorzystywane w sposób odpowiedzialny, będzie miało kluczowe znaczenie dla ich długoterminowego sukcesu.
Powiązane tematy:Porównanie 8 najpopularniejszych modeli AI w 2025 r.
Podsumowanie
Qwen2.5-VL-32B to potężne narzędzie w arsenale modeli AI zaprojektowanych do radzenia sobie z zadania multimodalne z imponującą dokładnością i wyrafinowaniem. Dzięki integracji zaawansowanych uczenie się wzmacniania, architektura transformatora, dopasowanie wizualno-językowe, to nie tylko przewyższa poprzednie modele ale otwiera również ekscytujące możliwości dla branż, od Edukacja do autonomiczna jazdaJako technologia typu open source oferuje ona ogromny potencjał dla programistów i użytkowników AI do eksperymentowania, optymalizacji i wdrażania w rzeczywistych aplikacjach.
Jak wywołać Qwen2.5-VL-32B API z CometAPI
1.Zaloguj Się do pl.com. Jeśli jeszcze nie jesteś naszym użytkownikiem, zarejestruj się najpierw
2.Uzyskaj klucz API danych uwierzytelniających dostęp interfejsu. Kliknij „Dodaj token” przy tokenie API w centrum osobistym, pobierz klucz tokena: sk-xxxxx i prześlij.
-
Uzyskaj adres URL tej witryny: https://api.cometapi.com/
-
Wybierz punkt końcowy Qwen2.5-VL-32B, aby wysłać żądanie API i ustawić treść żądania. Metoda żądania i treść żądania są uzyskiwane z dokumentacja API naszej witryny internetowej. Nasza strona internetowa udostępnia również test Apifox dla Twojej wygody.
-
Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź. Po wysłaniu żądania API otrzymasz obiekt JSON zawierający wygenerowane uzupełnienie.