
Qwen3-Max-Preview to najnowszy flagowy model Alibaba w wersji zapoznawczej z rodziny Qwen3 — ponad bilionowy model w stylu Mixture-of-Experts (MoE) z ultradługim oknem kontekstowym tokenów o pojemności 262 tys., wydany w wersji zapoznawczej do użytku korporacyjnego/w chmurze. Jego celem jest: *głębokie rozumowanie, rozumienie długich dokumentów, kodowanie i przepływy pracy agentów.
Podstawowe informacje i nagłówki
- Nazwa / Etykieta:
qwen3-max-preview(Polecić). - Skala: Ponad 1 bilion parametrów (flagowy model z bilionem parametrów). To kluczowy kamień milowy marketingowo-statystyczny dla tego wydania.
- Okno kontekstowe: Tokeny 262,144 (obsługuje bardzo długie dane wejściowe i transkrypcje wieloplikowe).
- Tryb(y): Wariant „Instruct” dostosowany do instrukcji z obsługą myślenia (celowy ciąg myśli) i niemyślący szybkie tryby w rodzinie Qwen3.
- Dostępność: Dostęp do podglądu za pośrednictwem Czat Qwen, Alibaba Cloud Model Studio (punkty końcowe zgodne z OpenAI lub DashScope) i dostawcy trasowania, tacy jak Interfejs API Comet.
Szczegóły techniczne (architektura i tryby)
- architektura: Qwen3-Max jest kontynuacją linii projektowej Qwen3, która wykorzystuje połączenie gęsta + Mieszanka Ekspertów (MoE) komponenty w większych wariantach, a także rozwiązania inżynieryjne mające na celu optymalizację wydajności wnioskowania przy bardzo dużej liczbie parametrów.
- Tryb myślenia kontra tryb niemyślenia: Seria Qwen3 wprowadziła tryb myślenia (do wyników w stylu wieloetapowego łańcucha myśli) i tryb niemyślenia Aby uzyskać szybsze i bardziej zwięzłe odpowiedzi, platforma udostępnia parametry umożliwiające przełączanie tych zachowań.
- Funkcje buforowania kontekstu/wydajności: Listy Model Studio pamięć podręczna kontekstu obsługa dużych żądań w celu ograniczenia kosztów powtarzalnych danych wejściowych i zwiększenia przepustowości w powtarzalnych kontekstach.
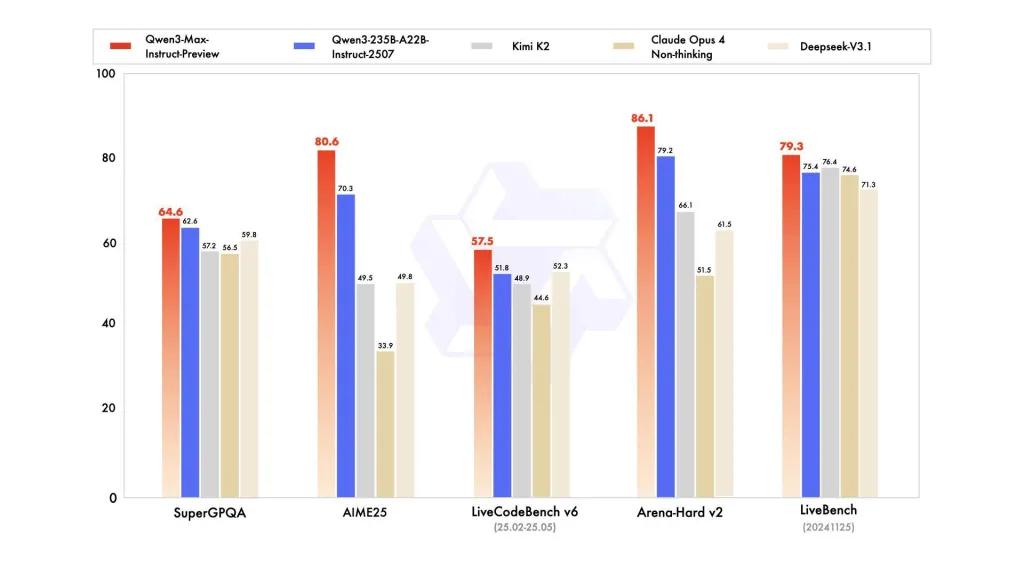
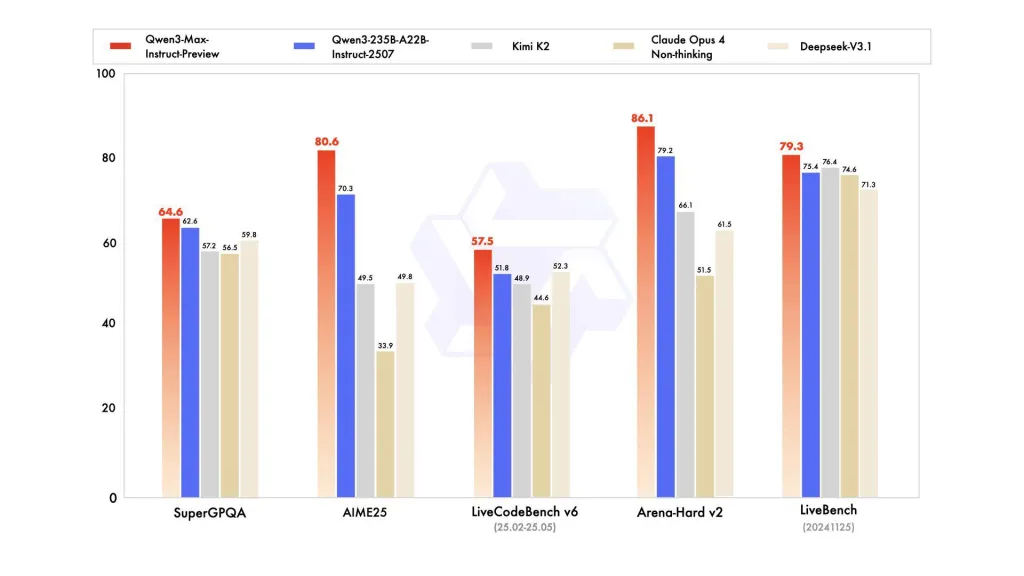
Wydajność wzorcowa
raporty odwołują się do SuperGPQA, wariantów LiveCodeBench, AIME25 i innych zestawów testów/benchmarków, w których Qwen3-Max okazuje się konkurencyjny lub wiodący.
Ograniczenia i zagrożenia (uwagi praktyczne i dotyczące bezpieczeństwa)
- Krycie dla pełnego przepisu treningowego / ciężarów: W ramach zapowiedzi, pełne materiały dotyczące szkolenia/danych/wagi i odtwarzalności mogą być ograniczone w porównaniu z wcześniejszymi, otwartymi wersjami Qwen3. Niektóre modele z rodziny Qwen3 zostały wydane w wersji otwartej, ale Qwen3-Max jest dostarczany jako kontrolowany podgląd z dostępem do chmury. zmniejsza powtarzalność dla niezależnych badaczy.
- Halucynacje i faktyczność: Raporty dostawców wskazują na zmniejszenie liczby halucynacji, ale w praktyce nadal można znaleźć błędy rzeczowe i przesadną pewność siebie – obowiązują standardowe ostrzeżenia LLM. Przed wdrożeniem o wysokim ryzyku konieczna jest niezależna ocena.
- Koszt w skali: Dzięki ogromnemu oknu kontekstowemu i dużym możliwościom, koszty tokenów może być znaczący w przypadku bardzo długich monitów lub przepustowości produkcyjnej. Użyj buforowania, dzielenia na fragmenty i kontroli budżetu.
- Rozważania dotyczące regulacji i suwerenności danych: Użytkownicy korporacyjni powinni sprawdzić regiony Alibaba Cloud, miejsce przechowywania danych i implikacje zgodności przed przetwarzaniem poufnych informacji. (Dokumentacja Model Studio zawiera punkty końcowe i uwagi specyficzne dla danego regionu).
Przykłady użycia
- Zrozumienie/podsumowanie dokumentu na dużą skalę: streszczenia prawne, specyfikacje techniczne i wieloplikowe bazy wiedzy (korzyść: Token 262K okno).
- Rozumowanie kodu w długim kontekście i pomoc w tworzeniu kodu na skalę repozytorium: zrozumienie kodu składającego się z wielu plików, przeglądy obszernych raportów PR, sugestie dotyczące refaktoryzacji na poziomie repozytorium.
- Zadania wymagające złożonego rozumowania i analizy ciągu myślowego: konkursy matematyczne, planowanie wieloetapowe, przepływy pracy agentów, w których ślady „myślenia” ułatwiają śledzenie.
- Wielojęzyczny, korporacyjny system pytań i odpowiedzi oraz ustrukturyzowana ekstrakcja danych: obsługa dużych korpusów wielojęzycznych i możliwości ustrukturyzowanego wyjścia (JSON/tabele).
Jak wywołać API Qqwen3-max-preview z CometAPI
qwen3-max-preview Ceny API w CometAPI, 20% zniżki od ceny oficjalnej:
| Tokeny wejściowe | $0.24 |
| Tokeny wyjściowe | $2.42 |
Wymagane kroki
- Zaloguj się do pl.com. Jeśli jeszcze nie jesteś naszym użytkownikiem, zarejestruj się najpierw
- Pobierz klucz API uwierzytelniania dostępu do interfejsu. Kliknij „Dodaj token” przy tokenie API w centrum osobistym, pobierz klucz tokena: sk-xxxxx i prześlij.
- Uzyskaj adres URL tej witryny: https://api.cometapi.com/
Użyj metody
- Wybierz punkt końcowy „qwen3-max-preview”, aby wysłać żądanie API i ustawić treść żądania. Metoda i treść żądania są dostępne w dokumentacji API naszej strony internetowej. Dla Państwa wygody nasza strona internetowa udostępnia również test Apifox.
- Zastępować za pomocą aktualnego klucza CometAPI ze swojego konta.
- Wpisz swoje pytanie lub prośbę w polu treści — model odpowie właśnie na tę wiadomość.
- . Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź.
Wywołanie API
CometAPI zapewnia w pełni kompatybilne API REST, co umożliwia bezproblemową migrację. Kluczowe szczegóły Dokumentacja API:
- Podstawowe parametry:
prompt,max_tokens_to_sample,temperature,stop_sequences - Punkt końcowy:
https://api.cometapi.com/v1/chat/completions - Parametr modelu: qwen3-max-preview
- Poświadczenie:
Bearer YOUR_CometAPI_API_KEY - Typ zawartości:
application/json.
zastąpić
CometAPI_API_KEYz kluczem; zwróć uwagę na adres URL bazowy.
Python (żądania) — zgodny z OpenAI
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Wskazówka: posługiwać się max_input_tokens, max_output_tokensi Model Studio pamięć podręczna kontekstu funkcje przy wysyłaniu bardzo dużych kontekstów w celu kontrolowania kosztów i przepustowości.
Zobacz także Koder Qwen3