

W dniach 19–20 listopada 2025 r. OpenAI wydało dwie powiązane, ale odrębne aktualizacje: GPT-5.1-Codex-Max, nowy model kodowania agentowego dla Codex, który kładzie nacisk na kodowanie długoterminowe, wydajność tokenów i „kompaktowanie” w celu obsługi sesji wielookienkowych; i GPT-5.1 Pro, zaktualizowany model ChatGPT w wersji Pro-tier, dostrojony do udzielania jaśniejszych i bardziej kompetentnych odpowiedzi w złożonych, profesjonalnych zastosowaniach.
Czym jest GPT-5.1-Codex-Max i jaki problem próbuje rozwiązać?
GPT-5.1-Codex-Max to specjalistyczny model Codex firmy OpenAI dostosowany do przepływów pracy związanych z kodowaniem, które wymagają trwałe, długoterminowe rozumowanie i realizacja. W przypadku gdy zwykłe modele mogą być blokowane przez wyjątkowo długie konteksty — na przykład refaktoryzacje obejmujące wiele plików, złożone pętle agentów lub ciągłe zadania CI/CD — Codex-Max został zaprojektowany tak, aby automatyczne kompaktowanie i zarządzanie stanem sesji w wielu oknach kontekstowych, umożliwiając mu spójną pracę w ramach pojedynczego projektu obejmującego tysiące (lub więcej) tokenów. OpenAI pozycjonuje Codex-Max jako kolejny krok w kierunku uczynienia agentów obsługujących kod autentycznie użytecznymi w rozszerzonych pracach inżynierskich.
Czym jest GPT-5.1-Codex-Max i jaki problem próbuje rozwiązać?
GPT-5.1-Codex-Max to specjalistyczny model Codex firmy OpenAI dostosowany do przepływów pracy związanych z kodowaniem, które wymagają trwałe, długoterminowe rozumowanie i realizacja. W przypadku gdy zwykłe modele mogą być blokowane przez wyjątkowo długie konteksty — na przykład refaktoryzacje obejmujące wiele plików, złożone pętle agentów lub ciągłe zadania CI/CD — Codex-Max został zaprojektowany tak, aby automatyczne kompaktowanie i zarządzanie stanem sesji w wielu oknach kontekstowych, co pozwala mu na spójną pracę w ramach pojedynczego projektu obejmującego tysiące (lub więcej) tokenów.
OpenAI opisuje go jako „szybszy, inteligentniejszy i wydajniejszy pod względem tokenów na każdym etapie cyklu rozwoju” i ma on wyraźnie zastąpić GPT-5.1-Codex jako domyślny model na powierzchniach Codex.
Migawka funkcji
- Kompaktowanie w celu zapewnienia ciągłości wielu okien: przycina i zachowuje krytyczny kontekst, aby spójnie pracować nad milionami tokenów i godzinami. 0
- Poprawiona wydajność tokena w porównaniu do GPT-5.1-Codex: do ~30% mniej tokenów myślowych przy podobnym wysiłku rozumowania w niektórych testach porównawczych kodu.
- Długoterminowa trwałość agenta: zaobserwowano wewnętrznie, że utrzymuje pętle agentów trwające wiele godzin/wiele dni (OpenAI udokumentował wewnętrzne przebiegi trwające >24 godzin).
- Integracje platform: dostępne już dziś w Codex CLI, rozszerzeniach IDE, chmurze i narzędziach do przeglądu kodu; wkrótce będzie dostępny dostęp do API.
- Obsługa środowiska Windows: OpenAI podkreśla, że po raz pierwszy w obiegach pracy Codex włączono obsługę systemu Windows, co rozszerza zakres możliwości rzeczywistych programistów.
Jak wypada w porównaniu z produktami konkurencyjnymi (np. GitHub Copilot, innymi programistycznymi sztuczkami AI)?
GPT-5.1-Codex-Max jest reklamowany jako bardziej autonomiczny, długoterminowy system współpracy w porównaniu z narzędziami do realizacji zadań na żądanie. Podczas gdy Copilot i podobne asystenty doskonale radzą sobie z realizacją zadań w krótkim czasie w edytorze, mocne strony Codex-Max to koordynacja zadań wieloetapowych, utrzymywanie spójności stanu w sesjach oraz obsługa przepływów pracy wymagających planowania, testowania i iteracji. Mimo to, najlepszym podejściem w większości zespołów będzie podejście hybrydowe: Codex-Max będzie wykorzystywany do złożonej automatyzacji i zadań agentów, a lżejsze asystenty do realizacji zadań na poziomie wiersza.
Jak działa GPT-5.1-Codex-Max?
Czym jest „kompaktowanie” i w jaki sposób umożliwia ono długotrwałą pracę?
Centralnym postępem technicznym jest zagęszczanie—wewnętrzny mechanizm, który usuwa historię sesji, zachowując jednocześnie istotne elementy kontekstu, dzięki czemu model może kontynuować spójną pracę w różnych obszarach wielokrotność Okna kontekstowe. W praktyce oznacza to, że sesje Kodeksu zbliżające się do limitu kontekstowego zostaną skompresowane (starsze lub o niższej wartości tokeny zostaną podsumowane/zachowane), dzięki czemu agent będzie miał nowe okno i będzie mógł kontynuować iterację aż do zakończenia zadania. OpenAI raportuje wewnętrzne uruchomienia, w których model pracował nad zadaniami nieprzerwanie przez ponad 24 godziny.
Adaptacyjne rozumowanie i efektywność tokenów
GPT-5.1-Codex-Max stosuje ulepszone strategie wnioskowania, które zwiększają wydajność tokenów: w raportowanych wewnętrznych testach porównawczych OpenAI model Max osiąga podobną lub lepszą wydajność niż GPT-5.1-Codex, przy jednoczesnym użyciu znacznie mniejszej liczby tokenów „myślących” — OpenAI podaje około O 30% mniej Tokeny myślowe na platformie SWE zweryfikowane przy równym wysiłku wnioskowania. Model wprowadza również tryb wysiłku wnioskowania „Extra High (xhigh)” dla zadań niezależnych od opóźnień, który pozwala na wykorzystanie większego wewnętrznego rozumowania w celu uzyskania wyników wyższej jakości.
Integracje systemowe i narzędzia agentowe
Codex-Max jest dystrybuowany w ramach przepływów pracy Codex (CLI, rozszerzenia IDE, chmura i powierzchnie do przeglądu kodu), aby umożliwić interakcję z rzeczywistymi łańcuchami narzędzi programistycznych. Wczesne integracje obejmują Codex CLI i agentów IDE (VS Code, JetBrains itp.), a następnie planowany jest dostęp do API. Celem projektu jest nie tylko inteligentniejsza synteza kodu, ale także sztuczna inteligencja, która może obsługiwać wieloetapowe przepływy pracy: otwieranie plików, uruchamianie testów, naprawianie błędów, refaktoryzacja i ponowne uruchamianie.
Jak GPT-5.1-Codex-Max sprawdza się w testach porównawczych i w praktyce?
Zadania wymagające długotrwałego rozumowania i długoterminowego
Oceny wskazują na mierzalną poprawę w zakresie rozumowania długoterminowego i zadań o charakterze długoterminowym:
- Wewnętrzne oceny OpenAICodex-Max może pracować nad zadaniami przez „ponad 24 godziny” w ramach wewnętrznych eksperymentów, a integracja Codex z narzędziami programistycznymi zwiększyła wewnętrzne wskaźniki produktywności inżynierskiej (np. wykorzystanie i przepustowość żądań ściągnięcia). Są to wewnętrzne deklaracje OpenAI, które wskazują na poprawę produktywności na poziomie zadań w praktyce.
- Niezależne oceny (METR):Niezależny raport METR zmierzył obserwowany horyzont czasowy 50% (statystyka przedstawiająca medianę czasu, w którym model może spójnie podtrzymywać długie zadanie) dla GPT-5.1-Codex-Max na poziomie około 2 godzin 40 minut (z szerokim przedziałem ufności), w porównaniu z 2 godzinami i 17 minutami GPT-5 w porównywalnych pomiarach — znacząca, zgodna z trendem poprawa w zakresie trwałej spójności. Metodologia METR i CI kładą nacisk na zmienność, ale wynik potwierdza tezę, że Codex-Max poprawia praktyczną wydajność w długim horyzoncie czasowym.
Testy porównawcze kodu
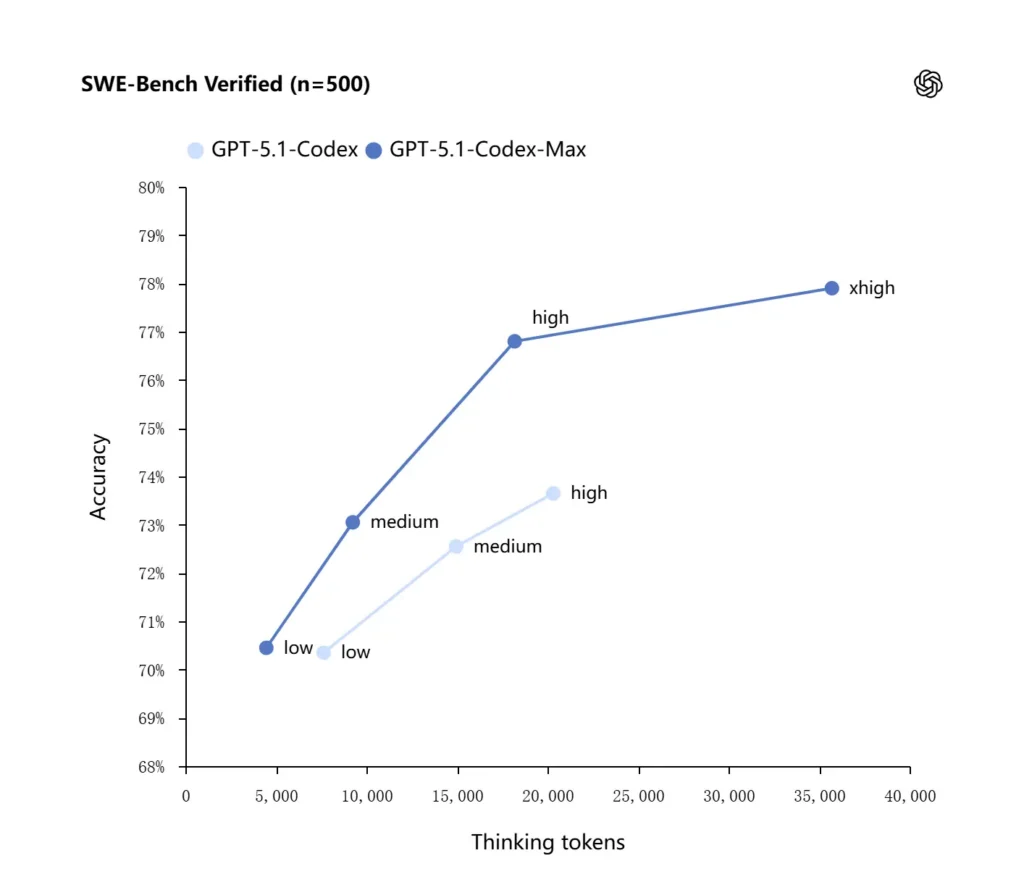
OpenAI raportuje lepsze wyniki w testach kodowania granicznego, zwłaszcza w teście SWE-bench Verified, gdzie GPT-5.1-Codex-Max przewyższa GPT-5.1-Codex pod względem lepszej wydajności tokenów. Firma podkreśla, że przy tym samym „średnim” nakładzie pracy na rozumowanie model Max generuje lepsze rezultaty, zużywając około 30% mniej tokenów myślowych; dla użytkowników, którzy pozwalają na dłuższe rozumowanie wewnętrzne, tryb xhigh może dodatkowo podnieść poziom odpowiedzi kosztem opóźnienia.
| GPT‑5.1-Codex (wysoki) | GPT‑5.1-Codex-Max (xhigh) | |
| Zweryfikowano na SWE-bench (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
Jak GPT-5.1-Codex-Max wypada w porównaniu z GPT-5.1-Codex?
Różnice w wydajności i celu
- Zakres: GPT-5.1-Codex to wysokowydajna odmiana rodziny kodów GPT-5.1; Codex-Max jest jawnie agentycznym następcą o długim horyzoncie czasowym, który ma być zalecaną wartością domyślną dla środowisk Codex i podobnych do Codex.
- Efektywność tokena: Codex-Max wykazuje znaczący wzrost wydajności tokenów (OpenAI twierdzi, że używa około 30% mniej tokenów myślowych) w testach SWE i w użyciu wewnętrznym.
- Zarządzanie kontekstem: Codex-Max wprowadza kompresję i natywną obsługę wielu okien w celu obsługi zadań wykraczających poza jedno okno kontekstowe. Codex nie zapewniał natywnie tej możliwości na taką skalę.
- Gotowość narzędzi: Codex-Max jest domyślnym modelem Codex w interfejsach CLI, IDE i na platformach do przeglądu kodu, co sygnalizuje migrację do przepływów pracy programistów produkcyjnych.
Kiedy stosować który model?
- Użyj GPT-5.1-Codex do interaktywnej pomocy w kodowaniu, szybkich edycji, niewielkich refaktoryzacji i przypadków użycia o mniejszym opóźnieniu, w których cały odpowiedni kontekst łatwo mieści się w jednym oknie.
- Użyj GPT-5.1-Codex-Max w przypadku refaktoryzacji obejmujących wiele plików, zautomatyzowanych zadań agentowych wymagających wielu cykli iteracji, przepływów pracy podobnych do CI/CD lub gdy model musi uwzględniać perspektywę na poziomie projektu w wielu interakcjach.
Praktyczne wzory podpowiedzi i przykłady pozwalające uzyskać najlepsze rezultaty?
Podpowiadanie wzorców, które działają dobrze
- Wyraźnie określ cele i ograniczenia: „Przebuduj X, zachowaj publiczne API, zachowaj nazwy funkcji i upewnij się, że testy A, B i C zaliczą pomyślnie.”
- Zapewnij minimalny możliwy do odtworzenia kontekst: Link do nieudanego testu, dołącz ślady stosu i odpowiednie fragmenty plików zamiast zrzucać całe repozytoria. Codex-Max będzie kompresował historię w razie potrzeby.
- W przypadku złożonych zadań stosuj instrukcje krok po kroku: podziel duże zadania na sekwencję podzadań i pozwól Codex-Maxowi iterować je (np. „1) uruchom testy 2) popraw 3 najczęściej nieudane testy 3) uruchom linter 4) podsumuj zmiany”).
- Poproś o wyjaśnienia i różnice: poproś zarówno o poprawkę, jak i krótkie uzasadnienie, aby recenzenci mogli szybko ocenić bezpieczeństwo i intencje.
Przykładowe szablony komunikatów
Zadanie refaktoryzacji
„Przebuduj
payment/moduł do ekstrakcji przetwarzania płatności dopayment/processor.py. Zachowaj stabilność publicznych sygnatur funkcji dla istniejących wywołujących. Utwórz testy jednostkowe dlaprocess_payment()Obejmują one powodzenie, awarię sieci i nieprawidłową kartę. Uruchom zestaw testów i zwróć nieudane testy oraz poprawkę w ujednoliconym formacie różnicowym.
Naprawiono błąd + przetestowano
„Test
tests/test_user_auth.py::test_token_refreshBłąd z wklejeniem śladu. Zbadaj przyczynę, zaproponuj poprawkę z minimalnymi zmianami i dodaj test jednostkowy, aby zapobiec regresji. Zastosuj poprawkę i uruchom testy.
Iteracyjne generowanie PR
„Wdrożenie funkcji X: dodanie punktu końcowego
POST /api/exportktóry przesyła strumieniowo wyniki eksportu i jest uwierzytelniany. Utwórz punkt końcowy, dodaj dokumenty, utwórz testy i otwórz żądanie żądania (PR) z podsumowaniem i listą kontrolną pozycji ręcznych.
W przypadku większości z nich zacznij od średni wysiłek; przełączyć się na xwysoki gdy potrzebujesz modelu do przeprowadzenia głębokiego rozumowania na podstawie wielu plików i wielu iteracji testów.
Jak uzyskać dostęp do GPT-5.1-Codex-Max
Gdzie jest dostępny dzisiaj
OpenAI zintegrowało GPT-5.1-Codex-Max z Narzędzia kodeksowe dziś: Codex CLI, rozszerzenia IDE, chmura i przepływy przeglądu kodu domyślnie korzystają z Codex-Max (można wybrać Codex-Mini). Dostępność API jest w przygotowaniu; GitHub Copilot udostępnia publiczne wersje zapoznawcze, obejmujące modele serii GPT-5.1 i Codex.
Programiści mogą uzyskać dostęp do GPT-5.1-Codex-Max i API GPT-5.1-Codex poprzez CometAPI. Na początek zapoznaj się z możliwościami modeluInterfejs API Comet Plac zabaw Szczegółowe instrukcje znajdziesz w przewodniku API. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. ZetAPI zaoferuj cenę znacznie niższą niż oficjalna, aby ułatwić Ci integrację.
Gotowy do drogi?→ Zarejestruj się w CometAPI już dziś !
Jeśli chcesz poznać więcej wskazówek, poradników i nowości na temat sztucznej inteligencji, obserwuj nas na VK, X oraz Discord!
Szybki start (praktyczny przewodnik krok po kroku)
- Upewnij się, że masz dostęp: sprawdź, czy Twój plan produktu ChatGPT/Codex (Plus, Pro, Business, Edu, Enterprise) lub Twój plan API dla deweloperów obsługuje modele rodziny GPT-5.1/Codex.
- Zainstaluj rozszerzenie Codex CLI lub IDE: Jeśli chcesz uruchamiać zadania kodu lokalnie, zainstaluj interfejs wiersza poleceń Codex lub rozszerzenie Codex IDE dla VS Code / JetBrains / Xcode, w zależności od potrzeb. W obsługiwanych konfiguracjach narzędzia będą domyślnie używać GPT-5.1-Codex-Max.
- Wybierz wysiłek rozumowania: zacząć od średni wysiłku w przypadku większości zadań. W przypadku głębokiego debugowania, złożonych refaktoryzacji lub gdy chcesz, aby model intensywniej myślał i nie zależy Ci na opóźnieniu odpowiedzi, przełącz się na wysoka or xwysoki tryby. Do szybkich, drobnych poprawek, Niska jest uzasadnione.
- Podaj kontekst repozytorium: Nadaj modelowi jasny punkt wyjścia — adres URL repozytorium lub zestaw plików oraz krótką instrukcję (np. „zrefaktoryzuj moduł płatności, aby korzystał z asynchronicznego wejścia/wyjścia i dodał testy jednostkowe, zachowując kontrakty na poziomie funkcji”). Codex-Max będzie kompresował historię w miarę zbliżania się do limitów kontekstowych i kontynuował pracę.
- Iteruj za pomocą testów: Po wygenerowaniu poprawek przez model, uruchamiaj zestawy testów i zgłaszaj awarie w ramach trwającej sesji. Kompaktowość i ciągłość w wielu oknach pozwalają Codex-Max zachować ważny kontekst dla nieudanych testów i iterować.
Wnioski:
GPT-5.1-Codex-Max stanowi znaczący krok w kierunku agentowych asystentów kodowania, które mogą obsługiwać złożone, długotrwałe zadania inżynierskie z lepszą wydajnością i wnioskowaniem. Postęp techniczny (kompresja, tryby wysiłku wnioskowania, szkolenie w środowisku Windows) sprawia, że model ten doskonale nadaje się do nowoczesnych organizacji inżynierskich — pod warunkiem, że zespoły połączą go z konserwatywnymi mechanizmami kontroli operacyjnej, jasnymi zasadami dotyczącymi udziału człowieka w procesie oraz solidnym monitorowaniem. W przypadku zespołów, które wdrożą go ostrożnie, Codex-Max ma potencjał, aby zmienić sposób projektowania, testowania i utrzymywania oprogramowania — przekształcając powtarzalną, żmudną pracę inżynierską w bardziej wartościową współpracę między ludźmi a modelami.