

W dniach 19–20 listopada 2025 OpenAI ogłosiło dwa powiązane, lecz odmienne ulepszenia: GPT-5.1-Codex-Max, nowy agentski model kodowania dla Codex, który kładzie nacisk na programowanie o długim horyzoncie, efektywność tokenów oraz „kompaktowanie”, aby utrzymać sesje wielookienne; oraz GPT-5.1 Pro, zaktualizowany model ChatGPT klasy Pro, dostrojony do jaśniejszych, bardziej kompetentnych odpowiedzi w złożonej, profesjonalnej pracy.
Czym jest GPT-5.1-Codex-Max i jaki problem stara się rozwiązać?
GPT-5.1-Codex-Max to wyspecjalizowany model Codex od OpenAI, dostrojony do przepływów pracy wymagających utrzymanego, długohoryzontowego rozumowania i wykonania. Tam, gdzie zwykłe modele potykają się na ekstremalnie długich kontekstach — np. przy refaktoryzacjach wielu plików, złożonych pętlach agentowych lub utrzymywanych zadaniach CI/CD — Codex-Max jest zaprojektowany tak, by automatycznie kompaktować i zarządzać stanem sesji w wielu oknach kontekstu, umożliwiając kontynuację spójnej pracy, gdy pojedynczy projekt rozciąga się na wiele tysięcy (lub więcej) tokenów. OpenAI pozycjonuje Codex-Max jako kolejny krok ku temu, by agenci zdolni do kodowania byli rzeczywiście użyteczni w wydłużonej pracy inżynierskiej.
Czym jest GPT-5.1-Codex-Max i jaki problem stara się rozwiązać?
GPT-5.1-Codex-Max to wyspecjalizowany model Codex od OpenAI, dostrojony do przepływów pracy wymagających utrzymanego, długohoryzontowego rozumowania i wykonania. Tam, gdzie zwykłe modele potykają się na ekstremalnie długich kontekstach — np. przy refaktoryzacjach wielu plików, złożonych pętlach agentowych lub utrzymywanych zadaniach CI/CD — Codex-Max jest zaprojektowany tak, by automatycznie kompaktować i zarządzać stanem sesji w wielu oknach kontekstu, umożliwiając kontynuację spójnej pracy, gdy pojedynczy projekt rozciąga się na wiele tysięcy (lub więcej) tokenów.
Jak opisuje OpenAI, jest „szybszy, inteligentniejszy i bardziej efektywny pod względem tokenów na każdym etapie cyklu rozwoju” i ma wyraźnie zastąpić GPT-5.1-Codex jako domyślny model w powierzchniach Codex.
Przegląd funkcji
- Kompaktowanie dla ciągłości w wielu oknach: przycina i zachowuje kluczowy kontekst, aby działać spójnie przez miliony tokenów i godziny. 0
- Zwiększona efektywność tokenów w porównaniu z GPT-5.1-Codex: do ~30% mniej tokenów „myślenia” przy podobnym wysiłku rozumowania na niektórych benchmarkach kodu.
- Agentowa trwałość w długim horyzoncie: wewnętrznie zaobserwowano utrzymanie wielogodzinnych/wielodniowych pętli agentowych (OpenAI udokumentowało wewnętrzne uruchomienia >24 godz.).
- Integracje platformowe: dostępny dziś w Codex CLI, rozszerzeniach IDE, chmurze i narzędziach code review; dostęp przez API w przygotowaniu.
- Obsługa środowiska Windows: OpenAI wskazuje, że po raz pierwszy w przepływach pracy Codex obsługiwany jest Windows, co poszerza realny zasięg wśród deweloperów.
Jak wypada na tle konkurencyjnych produktów (np. GitHub Copilot, inne narzędzia AI do kodowania)?
GPT-5.1-Codex-Max jest przedstawiany jako bardziej autonomiczny, długohoryzontowy współpracownik w porównaniu z narzędziami uzupełniania na żądanie. Podczas gdy Copilot i podobni asystenci świetnie sprawdzają się przy krótkoterminowych podpowiedziach w edytorze, mocą Codex-Max jest orkiestracja wieloetapowych zadań, utrzymanie spójnego stanu między sesjami oraz obsługa przepływów, które wymagają planowania, testowania i iteracji. W większości zespołów najlepsze będzie podejście hybrydowe: używaj Codex-Max do złożonej automatyzacji i utrzymanych zadań agentskich, a lżejszych asystentów do podpowiedzi na poziomie linii.
Jak działa GPT-5.1-Codex-Max?
Czym jest „kompaktowanie” i jak umożliwia długotrwałą pracę?
Kluczowym postępem technicznym jest kompaktowanie — mechanizm wewnętrzny, który przycina historię sesji, zachowując istotne fragmenty kontekstu, aby model mógł kontynuować spójną pracę przez wiele okien kontekstu. W praktyce oznacza to, że sesje Codex zbliżające się do limitu kontekstu będą kompaktowane (starsze lub mniej wartościowe tokeny są streszczane/zachowywane), dzięki czemu agent otrzymuje świeże okno i może powtarzać iteracje aż do ukończenia zadania. OpenAI raportuje wewnętrzne uruchomienia, w których model pracował nad zadaniami ciągiem przez ponad 24 godziny.
Adaptacyjne rozumowanie i efektywność tokenów
GPT-5.1-Codex-Max stosuje ulepszone strategie rozumowania, które zwiększają efektywność tokenów: w zgłoszonych przez OpenAI wewnętrznych benchmarkach model Max osiąga podobną lub lepszą wydajność niż GPT-5.1-Codex, używając znacząco mniej tokenów „myślenia” — OpenAI podaje około 30% mniej tokenów „myślenia” na SWE-bench Verified przy równym wysiłku rozumowania. Model wprowadza także tryb wysiłku rozumowania „Extra High (xhigh)” dla zadań niewrażliwych na opóźnienia, który pozwala zużywać więcej wewnętrznego rozumowania, aby uzyskać wyższej jakości wyniki.
Integracje systemowe i narzędzia agentskie
Codex-Max jest dystrybuowany w ramach przepływów pracy Codex (CLI, rozszerzenia IDE, chmura i powierzchnie code review), aby mógł wchodzić w interakcję z rzeczywistymi łańcuchami narzędzi deweloperskich. Wczesne integracje obejmują Codex CLI oraz agentów IDE (VS Code, JetBrains itd.), a dostęp przez API ma nastąpić w dalszej kolejności. Celem projektu jest nie tylko mądrzejsza synteza kodu, ale AI zdolna uruchamiać wieloetapowe przepływy: otwierać pliki, uruchamiać testy, naprawiać błędy, refaktoryzować i ponownie uruchamiać.
Jak GPT-5.1-Codex-Max wypada w benchmarkach i realnej pracy?
Utrzymane rozumowanie i zadania o długim horyzoncie
Oceny wskazują na mierzalne postępy w utrzymanym rozumowaniu i zadaniach o długim horyzoncie:
- Wewnętrzne oceny OpenAI: Codex-Max potrafi pracować nad zadaniami „ponad 24 godziny” w wewnętrznych eksperymentach, a integracja Codex z narzędziami deweloperskimi zwiększyła wewnętrzne metryki produktywności inżynieryjnej (np. użycie i przepustowość pull requestów). To wewnętrzne deklaracje OpenAI, wskazujące na poprawę na poziomie zadań w realnej produktywności.
- Niezależne oceny (METR): Niezależny raport METR zmierzył zaobserwowany 50% horyzont czasu (statystykę reprezentującą medianę czasu, przez jaki model potrafi spójnie podtrzymywać długie zadanie) dla GPT-5.1-Codex-Max na około 2 godziny 40 minut (z szerokim przedziałem ufności), w porównaniu z 2 godzinami 17 minutami dla GPT-5 w porównywalnych pomiarach — to znacząca, zgodna z trendem poprawa utrzymanej spójności. Metodologia METR i CI podkreślają zmienność, ale wynik wspiera narrację, że Codex-Max poprawia praktyczną wydajność w długim horyzoncie.
Benchmarki kodu
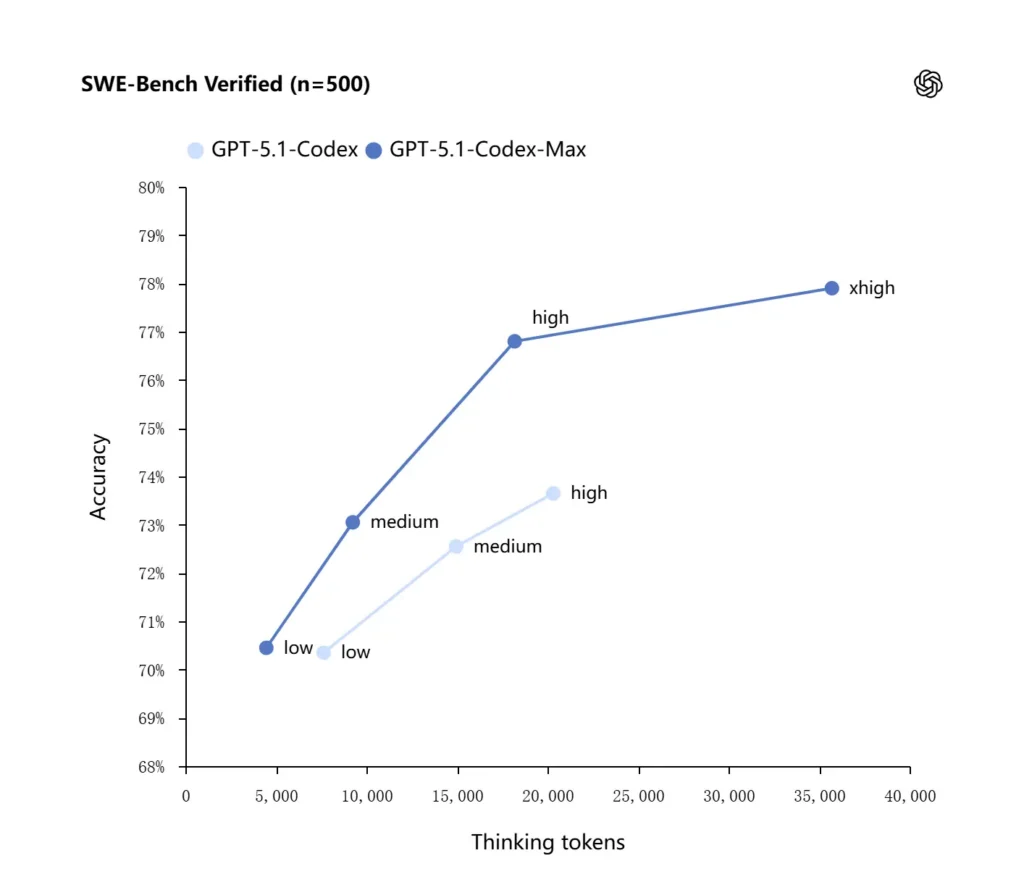
OpenAI raportuje lepsze wyniki na czołowych ewaluacjach kodu, w szczególności SWE-bench Verified, gdzie GPT-5.1-Codex-Max przewyższa GPT-5.1-Codex przy lepszej efektywności tokenów. Firma podkreśla, że przy tym samym „medium” wysiłku rozumowania model Max uzyskuje lepsze rezultaty, zużywając około 30% mniej tokenów „myślenia”; dla użytkowników, którzy dopuszczają dłuższe wewnętrzne rozumowanie, tryb xhigh może dodatkowo podnieść jakość odpowiedzi kosztem opóźnienia.
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
Jak GPT-5.1-Codex-Max wypada w porównaniu do GPT-5.1-Codex?
Różnice w wydajności i przeznaczeniu
- Zakres: GPT-5.1-Codex był wysokowydajnym wariantem kodującym rodziny GPT-5.1; Codex-Max to wyraźnie agentski, długohoryzontowy następca, rekomendowany jako domyślny model dla środowisk Codex i podobnych.
- Efektywność tokenów: Codex-Max wykazuje istotne zyski w efektywności tokenów (zgłoszenie OpenAI o ~30% mniej tokenów „myślenia”) na SWE-bench i w wewnętrznym użyciu.
- Zarządzanie kontekstem: Codex-Max wprowadza kompaktowanie i natywne obsługiwanie wielu okien, aby utrzymać zadania przekraczające pojedyncze okno kontekstu; Codex nie zapewniał tej możliwości w takiej skali.
- Gotowość narzędziowa: Codex-Max jest dostarczany jako domyślny model Codex w CLI, IDE i powierzchniach code review, co sygnalizuje migrację dla produkcyjnych przepływów pracy deweloperów.
Kiedy używać którego modelu?
- Używaj GPT-5.1-Codex do interaktywnej pomocy w kodowaniu, szybkich edycji, małych refaktoryzacji i zastosowań o niższych opóźnieniach, gdzie cały istotny kontekst mieści się łatwo w jednym oknie.
- Używaj GPT-5.1-Codex-Max do refaktoryzacji wielu plików, zautomatyzowanych zadań agentskich wymagających wielu cykli iteracji, przepływów podobnych do CI/CD lub gdy potrzebujesz, by model utrzymywał perspektywę na poziomie projektu przez wiele interakcji.
Praktyczne wzorce promptów i przykłady dla najlepszych rezultatów?
Wzorce promptowania, które działają dobrze
- Bądź precyzyjny w celach i ograniczeniach: „Zrefaktoruj X, zachowaj publiczne API, pozostaw nazwy funkcji i upewnij się, że testy A,B,C przechodzą.”
- Dostarczaj minimalny, reprodukowalny kontekst: podlinkuj zawodzący test, dołącz ślady stosu i istotne fragmenty plików zamiast zrzucać całe repozytoria. Codex-Max będzie kompaktować historię w razie potrzeby.
- Używaj instrukcji krok po kroku dla złożonych zadań: podziel duże prace na sekwencję podzadań i pozwól Codex-Max iterować przez nie (np. „1) uruchom testy 2) napraw 3 najczęściej zawodzące testy 3) uruchom linter 4) podsumuj zmiany”).
- Proś o wyjaśnienia i diffy: poproś zarówno o łatkę, jak i krótką racjonalizację, aby recenzenci mogli szybko ocenić bezpieczeństwo i zamiar.
Przykładowe szablony promptów
Zadanie refaktoryzacji
„Zrefaktoruj moduł
payment/, aby wyodrębnić przetwarzanie płatności dopayment/processor.py. Zachowaj stabilne publiczne sygnatury funkcji dla istniejących wywołań. Utwórz testy jednostkowe dlaprocess_payment(), obejmujące sukces, błąd sieci i nieprawidłową kartę. Uruchom zestaw testów i zwróć zawodzące testy oraz łatkę w formacie znormalizowanego diffu.”
Poprawka błędu + test
„Test
tests/test_user_auth.py::test_token_refreshkończy się błędem z takim śladem. Zbadaj przyczynę źródłową, zaproponuj poprawkę przy minimalnych zmianach i dodaj test jednostkowy zapobiegający regresji. Zastosuj łatkę i uruchom testy.”
Iteracyjne tworzenie PR
„Zaimplementuj funkcję X: dodaj endpoint
POST /api/export, który strumieniuje wyniki eksportu i jest uwierzytelniany. Utwórz endpoint, dodaj dokumentację, utwórz testy i otwórz PR z podsumowaniem oraz listą kontrolną elementów manualnych.”
W większości z nich zacznij od medium wysiłku; przełącz na xhigh, gdy potrzebujesz, by model głęboko rozumował w wielu plikach i przez wiele iteracji testów.
Jak uzyskać dostęp do GPT-5.1-Codex-Max
Gdzie jest dostępny dziś
OpenAI zintegrowało GPT-5.1-Codex-Max z narzędziami Codex: Codex CLI, rozszerzenia IDE, chmura i przepływy code-review używają Domyślnie Codex-Max (można wybrać Codex-Mini). Dostęp przez API jest w przygotowaniu; GitHub Copilot ma publiczne wersje zapoznawcze obejmujące modele z serii GPT-5.1 i Codex.
Deweloperzy mogą uzyskać dostęp do GPT-5.1-Codex-Max oraz GPT-5.1-Codex API poprzez CometAPI. Aby zacząć, poznaj możliwości modeli CometAPI w Playground i zapoznaj się z przewodnikiem API po szczegółowych instrukcjach. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby pomóc Ci w integracji.
Gotowy do działania?→ Zarejestruj się w CometAPI już dziś !
Jeśli chcesz więcej porad, przewodników i wiadomości o AI, obserwuj nas na VK, X i Discord!
Szybki start (praktycznie krok po kroku)
- Upewnij się, że masz dostęp: potwierdź, że Twój plan ChatGPT/Codex (Plus, Pro, Business, Edu, Enterprise) lub plan API dewelopera wspiera modele rodziny GPT-5.1/Codex.
- Zainstaluj Codex CLI lub rozszerzenie IDE: jeśli chcesz uruchamiać zadania kodowe lokalnie, zainstaluj Codex CLI lub rozszerzenie Codex do VS Code / JetBrains / Xcode, zależnie od potrzeb. Narzędzia w obsługiwanych konfiguracjach domyślnie użyją GPT-5.1-Codex-Max.
- Wybierz wysiłek rozumowania: zacznij od medium dla większości zadań. Do głębokiego debugowania, złożonych refaktoryzacji lub gdy chcesz, by model „myślał” intensywniej i nie przeszkadza Ci opóźnienie odpowiedzi, przełącz na high lub xhigh. Do szybkich, drobnych poprawek rozsądne jest low.
- Podaj kontekst repozytorium: daj modelowi klarowny punkt startowy — URL repo lub zestaw plików i krótką instrukcję (np. „zrefaktoruj moduł płatności, aby używać async I/O i dodaj testy jednostkowe, zachowaj kontrakty na poziomie funkcji”). Codex-Max będzie kompaktować historię przy zbliżaniu się do limitów kontekstu i kontynuować pracę.
- Iteruj z testami: po wygenerowaniu łatek przez model uruchamiaj zestawy testów i przekazuj z powrotem błędy w ramach trwającej sesji. Kompaktowanie i ciągłość w wielu oknach pozwalają Codex-Max zatrzymywać istotny kontekst zawodzących testów i iterować.
Podsumowanie:
GPT-5.1-Codex-Max reprezentuje znaczący krok w kierunku agentskich asystentów kodowania, którzy potrafią utrzymywać złożone, długotrwałe zadania inżynierskie z poprawioną efektywnością i rozumowaniem. Postępy techniczne (kompaktowanie, tryby wysiłku rozumowania, szkolenie na środowisko Windows) czynią go wyjątkowo dobrze dopasowanym do współczesnych organizacji inżynieryjnych — pod warunkiem, że zespoły połączą model z konserwatywnymi kontrolami operacyjnymi, jasnymi zasadami human-in-the-loop oraz solidnym monitorowaniem. Dla zespołów, które wdrożą go ostrożnie, Codex-Max ma potencjał zmienić sposób projektowania, testowania i utrzymania oprogramowania — przekształcając powtarzalną, żmudną pracę inżynierską w bardziej wartościową współpracę ludzi i modeli.