

DeepSeek wydał DeepSeek V3.2 jako następca linii V3.x i towarzyszący jej model DeepSeek-V3.2-Speciale Wersja, którą firma pozycjonuje jako wysokowydajną, pierwszą edycję z funkcją wnioskowania do użytku z agentami/narzędziami. Wersja 3.2 bazuje na pracach eksperymentalnych (V3.2-Exp) i wprowadza zaawansowane możliwości wnioskowania, edycję Speciale zoptymalizowaną pod kątem wydajności matematycznej/programowania konkursowego na „złotym poziomie” oraz to, co DeepSeek opisuje jako pierwszy w swoim rodzaju system dual-mode „myślenie + narzędzie”, który ściśle integruje wewnętrzne wnioskowanie krok po kroku z zewnętrznym wywoływaniem narzędzi i przepływami pracy agentów.
Czym jest DeepSeek V3.2 i czym różni się od V3.2-Speciale?
DeepSeek-V3.2 to oficjalny następca eksperymentalnej gałęzi DeepSeek V3.2-Exp. DeepSeek opisuje ją jako rodzina modeli „najpierw rozumowanie” stworzona dla agentówtj. modele dostrojone nie tylko pod kątem naturalnej jakości konwersacji, ale w szczególności pod kątem wnioskowania wieloetapowego, wywoływania narzędzi i niezawodnego wnioskowania w oparciu o ciąg myśli podczas pracy w środowiskach obejmujących narzędzia zewnętrzne (interfejsy API, wykonywanie kodu, złącza danych).
Czym jest DeepSeek-V3.2 (podstawowy)
- Pozycjonowany jako główny następca eksperymentalnej linii V3.2-Exp; przeznaczony do szerokiej dostępności za pośrednictwem aplikacji/strony internetowej/API DeepSeek.
- Utrzymuje równowagę pomiędzy wydajnością obliczeniową i solidnym rozumowaniem dla zadań agentowych.
Czym jest DeepSeek-V3.2-Speciale
DeepSeek-V3.2-Speciale to wariant, który DeepSeek sprzedaje jako „Special Edition” o większych możliwościach, dostrojony do rozumowania na poziomie konkursowym, zaawansowanej matematyki i wydajności agentów. Reklamowany jako wariant o większych możliwościach, który „przesuwa granice możliwości rozumowania”. DeepSeek obecnie prezentuje Speciale jako model wyłącznie API z tymczasowym routingiem dostępu; wstępne testy porównawcze sugerują, że jest on w stanie konkurować z zaawansowanymi modelami zamkniętymi w testach wnioskowania i kodowania.
Jakie wybory dotyczące pochodzenia i inżynierii doprowadziły do powstania wersji 3.2?
Wersja 3.2 dziedziczy linię iteracyjnej inżynierii DeepSeek, którą opublikowano w 2025 roku: V3 → V3.1 (Końcowy) → V3.2-Exp (krok eksperymentalny) → V3.2 → V3.2-Speciale. Wprowadzono eksperymentalną wersję V3.2-Exp. DeepSeek Sparse Attention (DSA) — precyzyjny mechanizm rzadkiej uwagi, mający na celu obniżenie kosztów pamięci i mocy obliczeniowej dla bardzo długich kontekstów, przy jednoczesnym zachowaniu jakości wyników. Badania nad DSA i prace nad redukcją kosztów posłużyły jako techniczny kamień milowy dla oficjalnej rodziny V3.2.
Co nowego w oficjalnej wersji DeepSeek 3.2?
1) Lepsza zdolność rozumowania — w jaki sposób poprawia się rozumowanie?
DeepSeek sprzedaje wersję 3.2 jako „najpierw rozumowanie”. Oznacza to, że architektura i dostrajanie koncentrują się na niezawodnym przeprowadzaniu wnioskowania wieloetapowego, utrzymywaniu wewnętrznych łańcuchów myślowych i wspieraniu rodzajów ustrukturyzowanej narady, których agenci potrzebują, aby prawidłowo korzystać z narzędzi zewnętrznych.
Konkretnie rzecz biorąc, ulepszenia obejmują:
- Szkolenie i RLHF (lub podobne procedury wyrównywania) dostrojone w celu zachęcenia do jawnego, krok po kroku rozwiązywania problemów i stabilnych stanów pośrednich (przydatne w rozumowaniu matematycznym, generowaniu kodu wieloetapowego i zadaniach logicznych).
- Wybory architektoniczne i dotyczące funkcji strat, które pozwalają zachować dłuższe okna kontekstowe i umożliwiają modelowi wierne odwoływanie się do wcześniejszych kroków rozumowania.
- Praktyczne tryby (patrz „tryb podwójny” poniżej), które pozwalają temu samemu modelowi działać albo w szybszym trybie „czatu”, albo w trybie „myślenia”, w którym celowo przechodzi przez etapy pośrednie przed podjęciem działania.
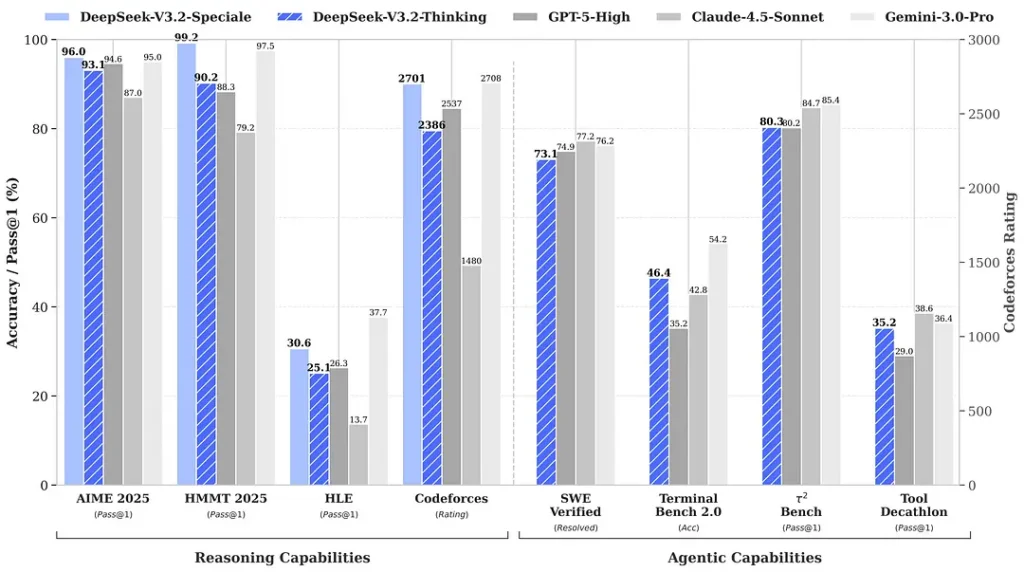
Testy porównawcze cytowane w kontekście wydania wskazują na znaczące postępy w zakresie pakietów matematycznych i rozumowania; niezależne, wczesne testy społecznościowe również wykazują imponujące wyniki w konkurencyjnych zestawach ocen:
2) Przełomowa wydajność w Edycji Specjalnej — o ile lepsza?
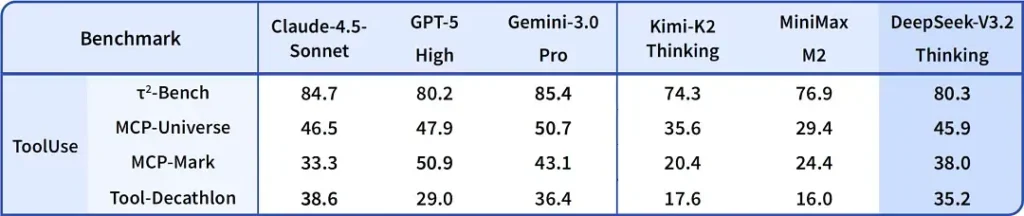
DeepSeek-V3.2-Speciale Deklaruje, że zapewnia wzrost dokładności wnioskowania i koordynacji agentów w porównaniu ze standardem V3.2. Dostawca przedstawia Speciale jako poziom wydajności ukierunkowany na duże obciążenia wnioskowania i wymagające zadania agentów; obecnie jest on dostępny wyłącznie w API i oferowany jako tymczasowy punkt końcowy o większych możliwościach (DeepSeek poinformował, że dostępność Speciale będzie początkowo ograniczona). Wersja Speciale integruje poprzedni model matematyczny DeepSeek-Math-V2; Potrafi samodzielnie dowodzić twierdzeń matematycznych i weryfikować rozumowanie logiczne; Osiągnął znakomite wyniki w wielu konkursach światowej klasy:
- 🥇 Złoty medal IMO (Międzynarodowej Olimpiady Matematycznej)
- 🥇 Złoty medal CMO (Chińskiej Olimpiady Matematycznej)
- 🥈 ICPC (Międzynarodowy Konkurs Programowania Komputerowego) Drugie miejsce (Konkurs Ludzki)
- 🥉 IOI (Międzynarodowa Olimpiada Informatyczna) Dziesiąte miejsce (Konkurs Ludzki)
| Benchmark | GPT-5 Wysoki | Gemini-3.0 Pro | Kimi-K2 Myślenie | DeepSeek-V3.2 Myślenie | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIM 2025 | 94.6 (13 tys.) | 95.0 (15 tys.) | 94.5 (24 tys.) | 93.1 (16 tys.) | 96.0 (23 tys.) |
| HMMT luty 2025 | 88.3 (16 tys.) | 97.5 (16 tys.) | 89.4 (31 tys.) | 92.5 (19 tys.) | 99.2 (27 tys.) |
| HMMT listopad 2025 | 89.2 (20 tys.) | 93.3 (15 tys.) | 89.2 (29 tys.) | 90.2 (18 tys.) | 94.4 (25 tys.) |
| IMOAnswerBench | 76.0 (31 tys.) | 83.3 (18 tys.) | 78.6 (37 tys.) | 78.3 (27 tys.) | 84.5 (45 tys.) |
| LiveCodeBench | 84.5 (13 tys.) | 90.7 (13 tys.) | 82.6 (29 tys.) | 83.3 (16 tys.) | 88.7 (27 tys.) |
| Siły kodu | 2537 (29 tys.) | 2708 (22 tys.) | - | 2386 (42 tys.) | 2701 (77 tys.) |
| Diament GPQA | 85.7 (8 tys.) | 91.9 (8 tys.) | 84.5 (12 tys.) | 82.4 (7 tys.) | 85.7 (16 tys.) |
| HLE | 26.3 (15 tys.) | 37.7 (15 tys.) | 23.9 (24 tys.) | 25.1 (21 tys.) | 30.6 (35 tys.) |
3) Pierwsza w historii implementacja systemu dualnego „myślenie + narzędzie”
Jednym z najbardziej interesujących praktycznie roszczeń w wersji 3.2 jest przepływ pracy w trybie podwójnym który oddziela (i pozwala wybierać pomiędzy) szybkie działanie konwersacyjne i wolniejszy, rozważny tryb „myślenia”, który ściśle integruje się z korzystaniem z narzędzi.
- Tryb „Czat / szybki”: Zaprojektowany do rozmów na czacie z niskim opóźnieniem, zwięzłymi odpowiedziami i mniejszą liczbą wewnętrznych śladów rozumowania — nadaje się do okazjonalnej pomocy, krótkich sesji pytań i odpowiedzi oraz aplikacji wymagających dużej szybkości.
- Tryb „Myślenia/wnioskowania”: Zoptymalizowany pod kątem rygorystycznego łańcucha myślowego, planowania krok po kroku i koordynowania narzędzi zewnętrznych (interfejsów API, zapytań do bazy danych, wykonywania kodu). Działając w trybie myślenia, model generuje bardziej precyzyjne kroki pośrednie, które można analizować lub wykorzystywać do generowania bezpiecznych i poprawnych wywołań narzędzi w systemach agentowych.
Ten wzorzec (konstrukcja dwutrybowa) był obecny we wcześniejszych gałęziach eksperymentalnych, a DeepSeek zintegrował go głębiej w wersji 3.2 i Speciale — Speciale obecnie obsługuje wyłącznie tryb myślenia (stąd bramkowanie API). Możliwość przełączania się między szybkością a rozwagą jest cenna dla inżynierów, ponieważ pozwala programistom wybrać odpowiedni kompromis między opóźnieniem a niezawodnością podczas tworzenia agentów, które muszą współpracować z systemami rzeczywistymi.
Dlaczego jest to godne uwagi: Wiele współczesnych systemów oferuje albo silny model łańcucha myślowego (do wyjaśnienia rozumowania), albo oddzielną warstwę koordynacji agentów/narzędzi. Koncepcja DeepSeek sugeruje ściślejsze powiązanie – model może „myśleć”, a następnie deterministycznie wywoływać narzędzia, wykorzystując odpowiedzi narzędzi do informowania o dalszym myśleniu – co jest bardziej płynne dla programistów tworzących autonomiczne agenty.
Gdzie dostać DeepSeek v3.2
Krótka odpowiedź — DeepSeek v3.2 możesz uzyskać na kilka sposobów, w zależności od swoich potrzeb:
- Oficjalna strona internetowa/aplikacja (używaj online) — wypróbuj internetowy interfejs DeepSeek lub aplikację mobilną, aby korzystać z wersji 3.2 w trybie interaktywnym.
- Dostęp do API — DeepSeek udostępnia wersję 3.2 za pośrednictwem swojego API (dokumentacja zawiera nazwy modeli / base_url i ceny). Zarejestruj się, aby uzyskać klucz API i wywołaj punkt końcowy wersji 3.2.
- Do pobrania/otwarte ciężarki (Przytulanie twarzy) — model (warianty V3.2 / V3.2-Exp) jest opublikowany na Hugging Face i można go pobrać (wersja open-weight).
huggingface-hubortransformersaby pobrać pliki. - Interfejs API Comet — Platforma agregująca API AI zapewnia hostowane punkty końcowe w wersji 3.2-Exp. Cena jest niższa niż oficjalna.
Kilka praktycznych uwag:
- Jeśli chcesz ciężary do biegania lokalnie, przejdź na stronę modelu Hugging Face (zaakceptuj wszelkie warunki licencji/dostępu) i użyj
huggingface-cliortransformersdo pobrania; dokładne polecenia są zwykle podane w repozytorium GitHub. - Jeśli chcesz wykorzystanie produkcyjne za pośrednictwem API, postępuj zgodnie z platformą, taką jak dokumentacja API Cometapi dla nazw punktów końcowych i poprawnych
base_urldla wariantu V3.2.
DeepSeek-V3.2-Speciale:
- Otwarte wyłącznie do użytku badawczego, obsługuje dialog w trybie „myślenia”, ale nie obsługuje wywoływania narzędzi.
- Maksymalna liczba tokenów może wynieść 128 tys. (bardzo długi łańcuch myślowy).
- Obecnie można testować bezpłatnie do 15 grudnia 2025 r.
Końcowe przemyślenia
DeepSeek-V3.2 stanowi znaczący krok w rozwoju modeli skoncentrowanych na rozumowaniu. Połączenie ulepszonego rozumowania wieloetapowego, specjalistycznych edycji o wysokiej wydajności (Speciale) oraz integracji „myślenie + narzędzie” w wersji produkcyjnej jest godne uwagi dla każdego, kto tworzy zaawansowanych agentów, asystentów kodowania lub procesy badawcze, w których rozważania muszą przeplatać się z działaniami zewnętrznymi.
Programiści mogą uzyskać dostęp do DeepSeek V3.2 za pośrednictwem CometAPI. Na początek zapoznaj się z możliwościami modelowania CometAPI w Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. ZetAPI zaoferuj cenę znacznie niższą niż oficjalna, aby ułatwić Ci integrację.
Gotowy do drogi?→ Zarejestruj się w CometAPI już dziś !
Jeśli chcesz poznać więcej wskazówek, poradników i nowości na temat sztucznej inteligencji, obserwuj nas na VK, X oraz Discord!