

DeepSeek wydał DeepSeek V3.2 jako następcę linii V3.x oraz towarzyszący wariant DeepSeek-V3.2-Speciale, który firma pozycjonuje jako edycję o wysokiej wydajności, z priorytetem na rozumowanie, przeznaczoną do użytku przez agentów/narzędzia. V3.2 bazuje na pracach eksperymentalnych (V3.2-Exp) i wprowadza wyższe zdolności rozumowania, edycję Speciale zoptymalizowaną pod „złotopoziomowe” wyniki z matematyki/programowania konkurencyjnego oraz to, co DeepSeek opisuje jako pierwszy w swoim rodzaju, dwumodalny system „myślenie + narzędzia”, ściśle integrujący wewnętrzne rozumowanie krok po kroku z wywoływaniem zewnętrznych narzędzi i przepływami pracy agentów.
Czym jest DeepSeek V3.2 — i czym różni się V3.2-Speciale?
DeepSeek-V3.2 to oficjalny następca eksperymentalnej gałęzi DeepSeek V3.2-Exp. DeepSeek opisuje go jako „rodzinę modeli zorientowanych na rozumowanie, zbudowanych dla agentów”, tzn. modele dostrojone nie tylko pod naturalną jakość konwersacyjną, ale w szczególności pod wnioskowanie wieloetapowe, wywoływanie narzędzi oraz niezawodne rozumowanie w stylu łańcucha rozumowania podczas pracy w środowiskach obejmujących zewnętrzne narzędzia (API, wykonywanie kodu, łączniki danych).
Czym jest DeepSeek-V3.2 (wersja podstawowa)
- Pozycjonowany jako główny, produkcyjny następca eksperymentalnej linii V3.2-Exp; przeznaczony do szerokiej dostępności przez aplikację/web/API DeepSeek.
- Zachowuje równowagę między efektywnością obliczeniową a solidnym rozumowaniem dla zadań agentowych.
Czym jest DeepSeek-V3.2-Speciale
DeepSeek-V3.2-Speciale to wariant, który DeepSeek promuje jako „Edycję Specjalną” o wyższych możliwościach, dostrojoną pod poziom konkursowy w rozumowaniu, zaawansowaną matematykę i wydajność agentów. Pozycjonowany jako wariant o wyższych możliwościach, który „przesuwa granice zdolności rozumowania”. DeepSeek udostępnia obecnie Speciale wyłącznie jako model API z tymczasowym routingiem dostępu; wczesne benchmarki sugerują, że jest pozycjonowany do konkurowania z wysokiej klasy zamkniętymi modelami w benchmarkach rozumowania i kodowania.
Jaka linia rozwojowa i wybory inżynieryjne doprowadziły do V3.2?
V3.2 dziedziczy linię iteracyjnych prac inżynieryjnych upublicznionych przez DeepSeek w 2025 r.: V3 → V3.1 (Terminus) → V3.2-Exp (krok eksperymentalny) → V3.2 → V3.2-Speciale. Eksperymentalny V3.2-Exp wprowadził DeepSeek Sparse Attention (DSA) — drobnoziarnisty mechanizm rzadkiej uwagi mający na celu obniżenie kosztów pamięci i obliczeń dla bardzo długich długości kontekstu przy zachowaniu jakości wyników. Badania nad DSA oraz prace nad redukcją kosztów posłużyły jako techniczny krok milowy dla oficjalnej rodziny V3.2.
Co nowego w oficjalnym DeepSeek 3.2?
1) Zwiększone zdolności rozumowania — jak je ulepszono?
DeepSeek promuje V3.2 jako „zorientowany na rozumowanie”. Oznacza to, że architektura i strojenie koncentrują się na niezawodnym wykonywaniu wnioskowania wieloetapowego, utrzymywaniu wewnętrznych łańcuchów rozumowania oraz wspieraniu rodzaju strukturalnej deliberacji, jakiej potrzebują agenci, aby poprawnie używać narzędzi zewnętrznych.
Konkretnie, usprawnienia obejmują:
- Szkolenie i RLHF (lub podobne procedury aligningu) dostrojone tak, by zachęcać do jawnego, krokowego rozwiązywania problemów oraz stabilnych stanów pośrednich (przydatnych w rozumowaniu matematycznym, wieloetapowym generowaniu kodu i zadaniach logicznych).
- Wybory architektoniczne i funkcje straty, które utrzymują dłuższe okna kontekstu i pozwalają modelowi z wiernością odwoływać się do wcześniejszych kroków rozumowania.
- Tryby praktyczne (zob. „dwumodalność” poniżej), które pozwalają temu samemu modelowi działać albo w szybszym trybie „chat”, albo w deliberacyjnym trybie „thinking”, w którym celowo przechodzi przez kroki pośrednie przed podjęciem działania.
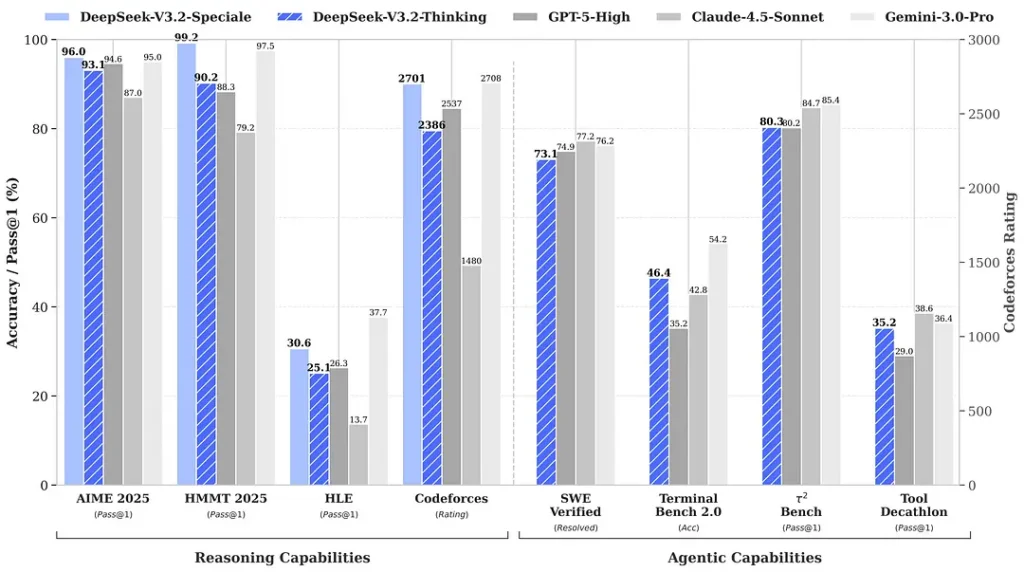
Benchmarki cytowane w okolicach premiery wskazują na znaczące zyski w zestawach matematycznych i rozumowania; niezależne, wczesne benchmarki społeczności również raportują imponujące wyniki na konkurencyjnych zestawach ewaluacyjnych:
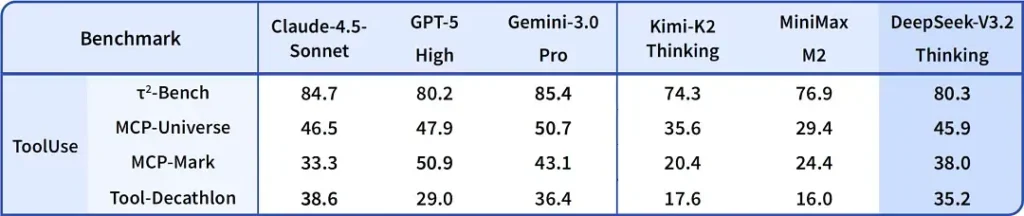
2) Przełomowa wydajność w edycji Speciale — o ile lepsza?
DeepSeek-V3.2-Speciale ma zapewniać skokową poprawę dokładności rozumowania i orkiestracji agentów w porównaniu ze standardowym V3.2. Dostawca przedstawia Speciale jako poziom wydajności skierowany na obciążenia wymagające intensywnego rozumowania i wymagające zadania agentowe; obecnie dostępny tylko przez API i oferowany jako tymczasowy, wyżej wydajny endpoint (DeepSeek wskazuje, że dostępność Speciale będzie początkowo ograniczona). Wersja Speciale integruje wcześniejszy model matematyczny DeepSeek-Math-V2; potrafi samodzielnie dowodzić twierdzeń matematycznych i weryfikować rozumowanie logiczne; osiągnęła znakomite wyniki w wielu światowej klasy konkursach:
- 🥇 IMO (Międzynarodowa Olimpiada Matematyczna) Złoty Medal
- 🥇 CMO (Chińska Olimpiada Matematyczna) Złoty Medal
- 🥈 ICPC (Międzynarodowy Konkurs Programowania Komputerowego) Drugie miejsce (zawody ludzkie)
- 🥉 IOI (Międzynarodowa Olimpiada Informatyczna) Dziesiąte miejsce (zawody ludzkie)
| Benchmark | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) Pierwsza w historii implementacja dwumodalnego systemu „myślenie + narzędzie”
Jednym z najbardziej praktycznych twierdzeń dotyczących V3.2 jest dwumodalny workflow, który rozdziela (i pozwala wybierać między) szybką konwersację a wolniejszy, deliberacyjny tryb „thinking”, ściśle zintegrowany z użyciem narzędzi.
- Tryb „Chat / fast”: Zaprojektowany pod niskie opóźnienia, interfejs rozmowy z krótkimi odpowiedziami i mniejszą liczbą śladów wewnętrznego rozumowania — dobry do swobodnej pomocy, krótkiego Q&A oraz zastosowań wrażliwych na szybkość.
- Tryb „Thinking / reasoner”: Zoptymalizowany pod rygorystyczny łańcuch rozumowania, planowanie krok po kroku i orkiestrację narzędzi zewnętrznych (API, zapytania do baz danych, wykonywanie kodu). W trybie thinking model wytwarza bardziej jawne kroki pośrednie, które można inspekcjonować lub wykorzystać do bezpiecznych, poprawnych wywołań narzędzi w systemach agentowych.
Ten wzorzec (projekt dwumodalny) był obecny we wcześniejszych gałęziach eksperymentalnych, a DeepSeek zintegrował go głębiej w V3.2 i Speciale — Speciale obecnie wspiera wyłącznie tryb thinking (stąd ograniczenie przez API). Możliwość przełączania między szybkością a deliberacją jest cenna inżynieryjnie, bo pozwala deweloperom dobrać właściwy kompromis między latencją a niezawodnością przy budowie agentów, którzy muszą wchodzić w interakcje z systemami świata rzeczywistego.
Dlaczego to istotne: Wiele współczesnych systemów oferuje albo silny model z łańcuchem rozumowania (do wyjaśniania rozumowania), albo oddzielną warstwę orkiestracji agentów/narzędzi. Ujęcie DeepSeek sugeruje ściślejsze sprzężenie — model może „myśleć”, a następnie w sposób deterministyczny wywoływać narzędzia, używając odpowiedzi narzędzi do informowania dalszego myślenia — co jest bardziej bezszwowe dla deweloperów budujących autonomicznych agentów.
Gdzie zdobyć DeepSeek v3.2
Krótka odpowiedź — możesz uzyskać DeepSeek v3.2 na kilka sposobów, w zależności od potrzeb:
- Oficjalna strona/aplikacja (użycie online) — wypróbuj interfejs webowy DeepSeek lub aplikację mobilną, aby korzystać z V3.2 interaktywnie.
- Dostęp przez API — DeepSeek udostępnia V3.2 przez swoje API (dokumentacja zawiera nazwy modeli /
base_urli ceny). Zarejestruj klucz API i wywołuj endpoint v3.2. - Pobieralne/otwarte wagi (Hugging Face) — model (warianty V3.2 / V3.2-Exp) jest opublikowany na Hugging Face i można go pobrać (open-weight). Użyj
huggingface-hublubtransformers, aby pobrać pliki. - CometAPI — platforma agregująca API AI zapewnia hostowane endpointy V3.2-Exp. Cena jest niższa niż oficjalna.
Kilka praktycznych uwag:
- Jeśli chcesz uruchamiać wagi lokalnie, przejdź do strony modelu na Hugging Face (zaakceptuj odpowiednią licencję/warunki dostępu) i użyj
huggingface-clilubtransformersdo pobrania; repozytorium GitHub zwykle pokazuje dokładne polecenia. - Jeśli chcesz produkcyjnego użycia przez API, skorzystaj z dokumentacji platformy, takiej jak CometAPI, aby poznać nazwy endpointów i poprawny
base_urldla wariantu V3.2.
DeepSeek-V3.2-Speciale:* Tylko do użytku badawczego, wspiera dialog w „Trybie Myślenia”, ale nie wspiera wywołań narzędzi.
- Maksymalna długość wyjścia może sięgnąć 128K tokenów (ultradługi Łańcuch Myślenia).
- Obecnie darmowy do testów do 15 grudnia 2025 r.
Wnioski końcowe
DeepSeek-V3.2 stanowi znaczący krok w dojrzewaniu modeli zorientowanych na rozumowanie. Jego połączenie ulepszonego wnioskowania wieloetapowego, wyspecjalizowanych edycji o wysokiej wydajności (Speciale) oraz produkcyjnej integracji „myślenie + narzędzia” jest warte uwagi dla każdego, kto buduje zaawansowanych agentów, asystentów programistycznych lub przepływy pracy badawczej, które muszą przeplatać deliberację z działaniami zewnętrznymi.
Deweloperzy mogą uzyskać dostęp do DeepSeek V3.2 poprzez CometAPI. Aby zacząć, zapoznaj się z możliwościami modelu na CometAPI w Playground oraz zajrzyj do API guide po szczegółowe instrukcje. Przed dostępem upewnij się, że zalogowałeś(-aś) się do CometAPI i uzyskałeś(-aś) klucz API. CometAPI oferuje ceny znacznie niższe niż oficjalne, aby ułatwić integrację.
Ready to Go?→ Sign up for CometAPI today !
Jeśli chcesz poznać więcej porad, przewodników i nowości o AI, śledź nas na VK, X oraz Discord!