

Gemini Embedding 2 to pierwszy w Google model osadzeń, który jest natywnie multimodalny i odwzorowuje tekst, obrazy, audio, wideo oraz pliki PDF w jednej 3,072‑wymiarowej semantycznej przestrzeni wektorowej (z konfigurowalnymi rozmiarami wyjścia). Wprowadza Matryoshka Representation Learning, aby zapewnić zagnieżdżone/obcinane osadzenia, lepszą wydajność wielojęzyczną (100+ języków) oraz zoptymalizowane sterowanie osadzeniami pod konkretne zadania (np. task:search, task:code).
What is Gemini Embedding 2?
Gemini Embedding 2 to ujednolicony model osadzeń od Google, który odwzorowuje wiele modalności wejściowych — tekst, obrazy, audio, wideo i dokumenty — w jedną semantyczną przestrzeń wektorową. Każde osadzenie to (domyślnie) 3,072‑wymiarowy wektor zmiennoprzecinkowy, który reprezentuje semantyczne znaczenie wejścia, dzięki czemu semantycznie podobne elementy (niezależnie od modalności) znajdują się blisko siebie w przestrzeni wektorowej. Najważniejsze możliwości:
- Szerokie pokrycie języków i formatów: jeden model, który przyjmuje tekst, obrazy, audio, wideo i dokumenty i umieszcza je w jednej semantycznej przestrzeni wektorowej. Udokumentowano, że Gemini Embedding 2 wychwytuje zamiar semantyczny w 100+ językach i akceptuje popularne formaty plików (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), z konkretnymi limitami na żądanie (np. do kilku obrazów lub kilkudziesięciu sekund audio/wideo na żądanie — patrz „Jak używać” poniżej).
- Prawdziwa multimodalność: jeden model, który przyjmuje tekst, obrazy, audio, wideo i dokumenty i umieszcza je w jednej semantycznej przestrzeni wektorowej, aby można było porównywać lub wyszukiwać między modalnościami (np. tekst → obraz, audio → tekst).
- Duża domyślna wymiarowość z elastycznym obcinaniem: model domyślnie zwraca wektory o wymiarze 3072, ale dzięki Matryoshka Representation Learning (MRL) koncentruje najważniejszą treść semantyczną w pierwszych wymiarach, więc można obciąć do 1536, 768 (lub niżej) przy jedynie niewielkich spadkach jakości wyszukiwania. To zmniejsza koszty przechowywania i obliczeń.
Dlaczego to ma znaczenie. Historycznie osadzenia były głównie tekstowe lub wymagały osobnych enkoderów dla każdej modalności z złożonymi warstwami dopasowania między modalnościami. Gemini Embedding 2 usuwa tę barierę, natywnie obsługując wiele formatów — dzięki czemu zapytanie tekstowe może wyszukać obraz lub krótki klip na podstawie podobieństwa semantycznego bez pośredniej transkrypcji czy ręcznego mapowania. Upraszcza to RAG (generowanie wspomagane wyszukiwaniem), wyszukiwanie semantyczne i multimodalne potoki wyszukiwania.
Key features & capabilities (what’s new)
1. Prawdziwa natywna multimodalność (jedna przestrzeń osadzeń)
Jeden model, który przyjmuje tekst, obrazy, audio, wideo i dokumenty i umieszcza je w jednej semantycznej przestrzeni wektorowej. Gemini Embedding 2 odwzorowuje tekst, obrazy, audio, wideo i dokumenty w tej samej przestrzeni osadzeń, aby bezpośrednio działało wyszukiwanie między modalnościami (tekst→obraz, audio→tekst), bez dopasowania między modelami. To redukuje złożoność potoku i upraszcza stosy RAG (Retrieval‑Augmented Generation).
2. Domyślne wektory 3,072‑wymiarowe z regulowanym wyjściem
Gemini Embedding 2 zwraca domyślnie wektory o wymiarze 3072, ale dzięki Matryoshka Representation Learning (MRL) koncentruje najważniejszą treść semantyczną w pierwszych wymiarach, więc można obciąć do 1536, 768 (lub niżej) przy jedynie niewielkich spadkach jakości wyszukiwania. To zmniejsza koszty przechowywania i obliczeń.
3. Matryoshka Representation Learning (MRL)
MRL wytwarza „zagnieżdżone” osadzenia — jak rosyjskie matrioszki — dzięki czemu niżej‑wymiarowe wycinki zachowują wyższej rangi semantykę. Pozwala to systemom dobrać punkt pracy (kompromis przechowywanie/dokładność) bez utrzymywania kilku oddzielnych modeli osadzeń. Wczesne analizy blogowe i dokumentacja opisują tę technikę jako kluczową innowację zwiększającą elastyczność.
4. Wskazówki zadaniowe / dostosowane cele osadzeń
API akceptuje wskazówki task (np. task:search, task:code retrieval, task:semantic-similarity), aby model mógł optymalizować geometrię przestrzeni osadzeń pod konkretne relacje downstream — podobnie do kondycjonowania na zadanie w wcześniejszych systemach osadzeń, ale rozszerzone o wejścia multimodalne.
5. Różnorodność języków i modalności
Udokumentowano, że Gemini Embedding 2 wychwytuje zamiar semantyczny w 100+ językach i akceptuje popularne formaty plików (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), z konkretnymi limitami na żądanie (np. do kilku obrazów lub kilkudziesięciu sekund audio/wideo na żądanie — patrz „Jak używać” poniżej).
Performance benchmarks
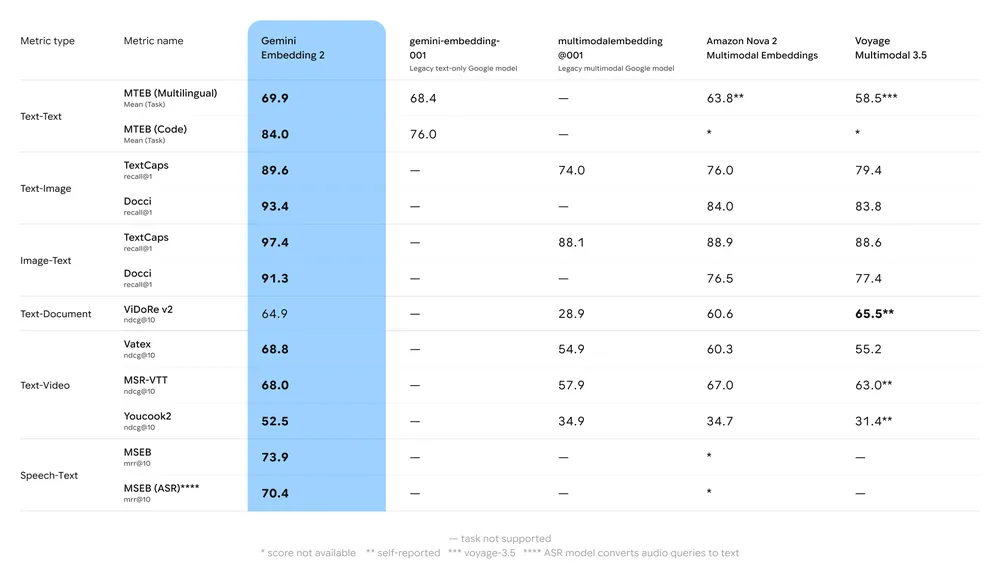
Kluczowe podsumowanie benchmarków:
- MTEB (Massive Text Embedding Benchmark): Zgłaszane wysokie pozycje na wielojęzycznych listach MTEB dla zadań anglojęzycznych i wielojęzycznych; analizy pokazują znaczący wzrost względem wcześniejszych modeli osadzeń Gemini i wielu rozwiązań proprietarnych.
- Wyszukiwanie multimodalne: Przewyższa lub dorównuje wiodącym jednokanałowym osadzeniom przy podobieństwie między modalnościami (np. wyszukiwanie tekst→obraz) dzięki natywnemu treningowi multimodalnemu.
- Opóźnienie i przepustowość: Generowanie osadzeń jest hostowane w chmurze, ale w zastosowaniach wrażliwych na opóźnienia warto rozważyć obcięte wektory lub alternatywne lekkie modele osadzeń dla potrzeb brzegowych.
Gemini Embedding 2 vs gemini-embedding-001 and text-embedding-3-large
| Attribute | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Release / availability | 10 marca 2026 — publiczna wersja zapoznawcza (Gemini API / Vertex AI). | Wcześniejszy model osadzeń Gemini (warianty tylko tekstowe) — GA wcześniej. | Ogłoszony w styczniu 2024 (GA tylko tekst). |
| Modalities supported | Tekst, obrazy, audio, wideo, dokumenty (PDF) — ujednolicona przestrzeń wektorowa. | Tekst (głównie). | Tylko tekst (wysokiej jakości wielojęzyczne). |
| Default embedding dim. | 3072 (MRL / rekomendowane obcinanie: 1536, 768). | 3072 (dla large) — tylko tekst. | 3072 (text-embedding-3-large). |
| Reported MTEB (example) | Wysokie „60+” na MTEB; w tabeli dostawcy widnieje 68.17 przy 1536 (patrz dokumentacja). | gemini-embedding-001 raportował ~68.32 średnio na niektórych listach. | ~64.6 (średnia MTEB raportowana przez OpenAI dla text-embedding-3-large). |
| Native audio/video support | Tak (bezpośrednie osadzanie audio/wideo). | Nie (tylko tekst). | Nie (tylko tekst). |
| Typical use cases | Multimodalne wyszukiwanie, RAG, wyszukiwanie semantyczne w różnych typach plików, wyszukiwanie mowy, wyszukiwanie wideo. | Wyszukiwanie tekstowe, wielojęzyczny RAG. | Wyszukiwanie tekstowe, wyszukiwanie semantyczne, RAG — mocna wielojęzyczna jakość tekstu. |
Technical specs & limits
Domyślny i regulowany rozmiar osadzeń
- Domyślnie: 3,072 wymiary.
- Regulowany: parametr
output_dimensionalitypozwala żądać niższych wymiarów wyjścia, aby oszczędzić miejsce/CPU. W zastosowaniach z ogromnymi bazami wektorów często redukuje się wymiary do 512–1,024 ze świadomą utratą dokładności.
Obsługiwane modalności i limity na żądanie
- Obrazy: PNG, JPEG — do 6 obrazów na żądanie (według danych dostawcy).
- Wideo: MP4, MOV — dostawca podaje do ~128 sekund na wideo dla osadzenia w pojedynczym żądaniu.
- Audio: MP3, WAV — dostawca podaje do ~80 sekund na wejście audio.
- Dokumenty: PDF — do 6 stron na żądanie (według dostawcy).
- Limit tokenów dla treści tekstowych: model obsługuje duże wejścia tokenów; istnieją praktyczne limity tokenów na żądanie (sprawdź dokumentację API i limity Vertex AI).
Dostępność i sposób dostępu
- Public preview: Gemini Embedding 2 został wydany jako publiczna wersja zapoznawcza i jest dostępny przez Gemini API oraz Google Cloud Vertex AI do natychmiastowych testów
Frequently asked questions (FAQ)
Q1: Jakie modalności obsługuje Gemini Embedding 2?
A: Tekst, obrazy (PNG/JPEG), wideo (MP4/MOV), audio (MP3/WAV) oraz dokumenty PDF — wszystkie mapowane do tej samej semantycznej przestrzeni wektorowej.
Q2: Jaki jest domyślny rozmiar wektora w Gemini Embedding 2?
A: Domyślnie 3,072 wymiary. Możesz poprosić o mniejszą wymiarowość wyjścia przez API.
Q3: Czy Gemini Embedding 2 jest dostępny już teraz?
A: Tak — ogłoszony jako public preview i dostępny przez Gemini API oraz Vertex AI (sprawdź identyfikator modelu gemini-embedding-2-preview i bieżący changelog).
Q4: Jak wypada w porównaniu z osadzeniami innych dostawców?
A: Niezależne testy dostawców wskazują, że Gemini Embedding 2 plasuje się wśród czołowych modeli proprietarnych dla wielojęzycznego tekstu i osiąga stan sztuki w kilku zadaniach multimodalnych. Dokładne miejsca zależą od zadania i zbioru; testuj na własnych danych.
Q5: Czy muszę transkrybować audio, aby użyć Gemini Embedding 2?
A: Nie — Gemini Embedding 2 może przyjąć audio bezpośrednio i wygenerować osadzenia bez wcześniejszej transkrypcji do tekstu, umożliwiając end‑to‑end semantyczne wyszukiwanie audio.
Q6: Jak obniżyć koszty przechowywania wektorów 3,072‑D?
A: Opcje obejmują żądanie niższego output_dimensionality, użycie float16/quantization/PQ oraz przechowywanie skompresowanych reprezentacji w twojej bazie wektorowej. Posty dostawcy zawierają przepływy pracy i najlepsze praktyki.
What comes next — should I adopt it now?
Gemini Embedding 2 to duży krok w kierunku ujednolicenia wyszukiwania multimodalnego i upraszcza architektury, które wcześniej wymagały osobnych wyszukiwarek dla tekstu, obrazu i mowy. Kluczowe punkty decyzyjne dotyczące wdrożenia:
- Wdrażaj szybciej, jeśli twój produkt potrzebuje solidnego wyszukiwania między modalnościami (tekst↔obraz/wideo/audio) lub jeśli utrzymywanie wielu wyszukiwarek jednomedalnych jest kosztowne i złożone.
- Pilotuj teraz, jeśli chcesz ocenić obcinanie MRL i zmierzyć koszt vs jakość (zachowaj hybrydowe wdrożenie: 1536 jako podstawowe, 3072 do rerankingu).
- Poczekaj, jeśli twoje obciążenie jest ekstremalnie wrażliwe na koszty i wymaga tylko wyszukiwania tekstowego — czołowe modele tylko tekstowe (np. OpenAI text-embedding-3-large) pozostają konkurencyjne i czasem tańsze w zależności od potoku i umowy.
Programiści mogą uzyskać dostęp do Gemini Embedding 2 i [OpenAI text-embedding-3 ]API za pośrednictwem CometAPI już teraz. Aby zacząć, poznaj możliwości modelu w Playground i zapoznaj się ze wskazówkami dotyczącymi API po szczegółowe instrukcje. Przed dostępem upewnij się, że zalogowałeś(aś) się do CometAPI i uzyskałeś(aś) klucz API. CometAPI oferuje cenę znacznie niższą od oficjalnej, aby ułatwić integrację.
Ready to Go?→ Zarejestruj się w cometapi już dziś !
Jeśli chcesz poznać więcej wskazówek, poradników i nowości o AI, obserwuj nas na VK, X i Discord!