
.webp&w=3840&q=75)
GLM-5.1 stanowi przełomową zmianę w krajobrazie AI. W miarę jak chińskie firmy AI przyspieszają komercjalizację, jednocześnie otwierając czołowe możliwości, ten model zmniejsza dystans do liderów zastrzeżonych, takich jak OpenAI GPT-5.4, Anthropic Claude Opus 4.6 i Google Gemini 3.1 Pro — zwłaszcza w realnej inżynierii oprogramowania. Wytrenowany na tej samej architekturze MoE z 744 mld parametrów co GLM-5, lecz mocno zoptymalizowany pod przepływy agentowe, świetnie radzi sobie tam, gdzie większość LLM-ów zawodzi: w długich, niejednoznacznych, iteracyjnych zadaniach wymagających planowania, eksperymentowania, debugowania i autokorekcji, wykonywanych w tysiącach wywołań narzędzi.
Obecnie CometAPI integruje GLM-5.1 oraz GLM-5, a deweloperzy mogą też zobaczyć inne czołowe modele z Zachodu i uzyskać do nich dostęp w bardzo niskiej cenie API (co jest również przewagą CometAPI względem innych konkurentów).
What is GLM-5.1?
GLM-5.1 to najnowszy flagowy model językowy Z.ai i kolejny krok firmy w kierunku długoterminowej, agentowej pracy programistycznej. Jak podaje samo Z.ai, model jest zaprojektowany do zadań wymagających ciągłego wykonywania, a nie jednorazowych odpowiedzi, i jest pozycjonowany jako model, który potrafi planować, wykonywać, udoskonalać i dostarczać w ramach jednego, wydłużonego przebiegu. W notatkach wydawniczych Z.ai informuje, że GLM-5.1 powstał dzięki nadzorowanemu dostrajaniu wieloturowemu, uczeniu ze wzmocnieniem oraz ramom oceny jakości procesu, a ponadto poprawia stabilność, spójność i użycie narzędzi w długich zadaniach.
To pozycjonowanie ma znaczenie, ponieważ GLM-5.1 nie jest sprzedawany jako „kolejny model czatowy”. Jest skierowany do przepływów inżynierskich, w których modele muszą utrzymać cel, obsłużyć kroki pośrednie i odzyskać kontrolę po błędach, nie gubiąc wątku — model do autonomicznego planowania, długotrwałego wykonywania, naprawy błędów i iteracji strategii, co jest zupełnie inną opowieścią produktową niż przypadkowy asystent czy krótko-kontekstowy copilot do kodu.
Praktyczny detal: GLM-5.1 jest modelem wyłącznie tekstowym, jest wspierany w GLM Coding Plan i może być używany w popularnych agentach kodowania, takich jak Claude Code i OpenClaw, co czyni go szczególnie istotnym dla zespołów chcących osadzić model w istniejącym przepływie pracy deweloperów zamiast go zastępować.
Core Technical Specifications (Inherited and Refined from GLM-5):
- Architecture: Architektura Mixture-of-Experts (MoE) z 744 miliardami łącznych parametrów i około 40 miliardami aktywnych parametrów na inferencję.
- Context Window: 203K–204.8K tokenów (z obsługą do 131K tokenów wyjściowych).
- Key Enhancements: DeepSeek Sparse Attention (DSA) dla efektywnego przetwarzania długiego kontekstu i niższych kosztów wdrożenia; zaawansowana asynchroniczna infrastruktura uczenia ze wzmocnieniem (za pośrednictwem frameworka „slime”) dla skuteczniejszego post-treningu.
- Availability: Otwarte wagi (licencja MIT na Hugging Face via zai-org/GLM-5.1), dostęp przez API na platformie Z.ai i u agregatorów takich jak CometAPI, oraz integracja z narzędziami GLM Coding Plan (zgodne z Claude Code / OpenClaw).
W przeciwieństwie do wcześniejszych modeli GLM nastawionych na ogólną inteligencję lub krótkie „vibe coding”, GLM-5.1 celuje w autonomiczne agenty klasy produkcyjnej. Potrafi samodzielnie planować, wykonywać, benchmarkować, debugować i iterować złożone projekty inżynierskie przez wiele godzin bez interwencji człowieka — możliwości, które plasują go jako bezpośredniego konkurenta wyspecjalizowanych agentów kodowania od Anthropic i OpenAI.
Wydanie zbiegło się z ~10% wzrostem ceny API (tokeny wejściowe ~$0.54/M, wyjściowe ~$4.40/M), jednak wciąż pozostaje on dramatycznie tańszy niż odpowiedniki, takie jak Anthropic Opus 4.6 (o 250–470% droższe).
GLM-5.1 Benchmark Performance
Z.ai pozycjonuje GLM-5.1 jako najsilniejszy model open-source na świecie i globalnego top-3 w agentowym kodowaniu. Dane pochodzą z oficjalnych ewaluacji na SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 oraz niestandardowych scenariuszach długoterminowych.
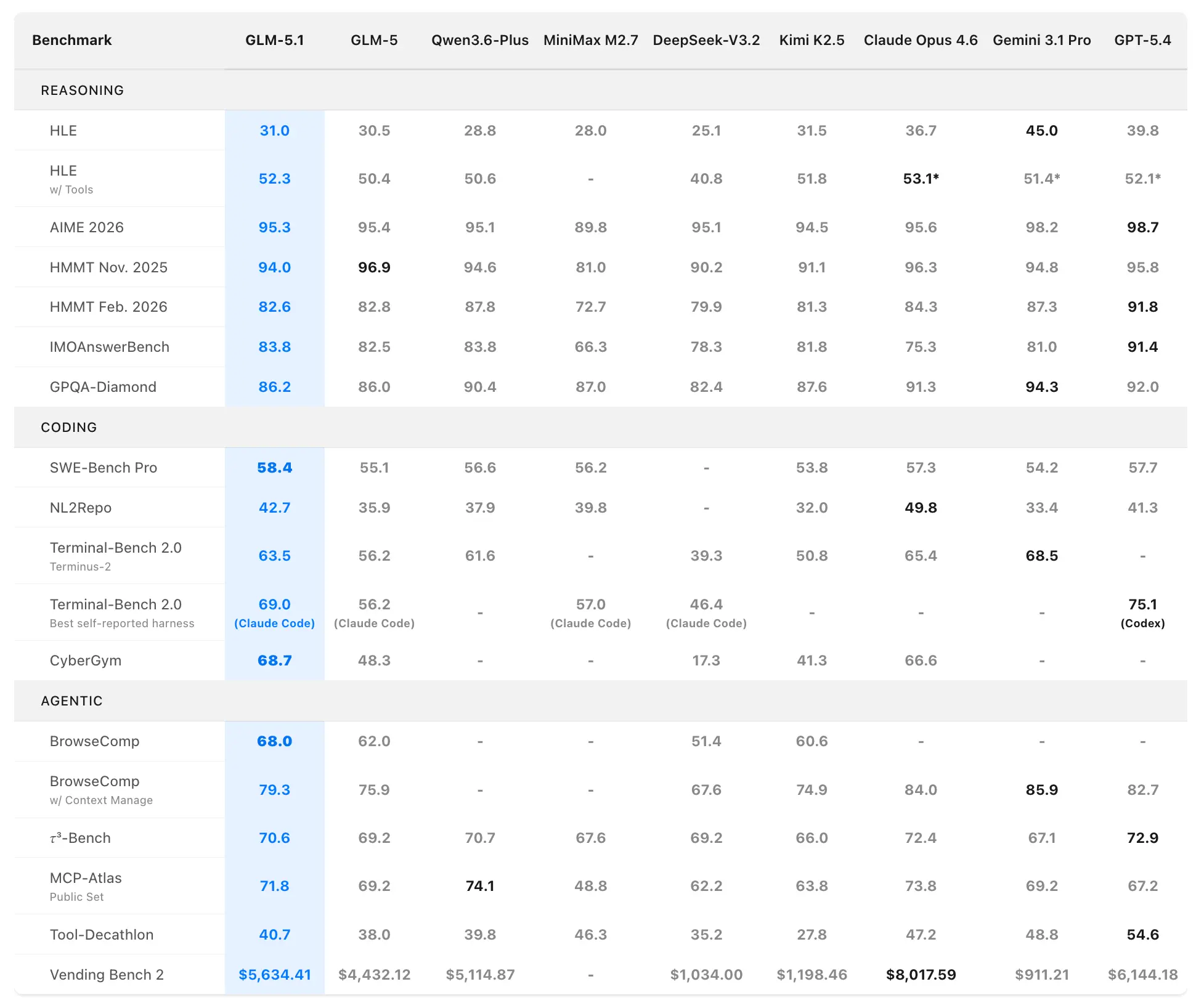
Coding and Agentic Benchmarks
SWE-Bench Pro (realistyczne zadania inżynierii oprogramowania wymagające nawigacji po repozytorium, edycji kodu i weryfikacji funkcjonalnej):
- GLM-5.1: 58.4 (nowy stan sztuki)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 jest pierwszym krajowym (chińskim) i open-source’owym modelem, który zdobywa pierwsze miejsce w tym wymagającym benchmarku, blisko odzwierciedlającym przepływy pracy profesjonalnych deweloperów.
NL2Repo (generowanie pełnego repozytorium z języka naturalnego):
- GLM-5.1: 42.7 (znaczna przewaga nad 35.9 GLM-5)
- Konkurencyjne modele mieszczą się w zakresie 32.0–49.8 (konkretni liderzy zależą od harnessu).
Terminal-Bench 2.0 (realne zadania terminalowe i systemowe):
- Harness Terminus-2: GLM-5.1 63.5 (vs. GLM-5 56.2)
- Najlepszy wynik samodeklarowany (Claude Code): do 69.0.
W osobnej ewaluacji w harnessie do kodowania (styl Claude Code) GLM-5.1 uzyskał 45.3 — osiągając 94.6% wyniku 47.9 Claude Opus 4.6 i 28% poprawy względem 35.4 GLM-5.
Composite Ranking: #1 open-source, #1 model chiński, #3 globalnie w zestawieniu SWE-Bench Pro + NL2Repo + Terminal-Bench.
Long-Horizon Task Performance: The Real Differentiator
Standardowe benchmarki mierzą wydajność w trybie one-shot lub krótkich sesjach. GLM-5.1 błyszczy w wydłużonych, autonomicznych przebiegach:
- VectorDBBench Optimization (600+ iteracji, 6,000+ wywołań narzędzi): Startując od szkieletu w Rust, GLM-5.1 iteracyjnie przeprojektował indeksowanie, kompresję, routing i pruning, osiągając 21.5k QPS (6× poprzedniego najlepszego wyniku 50-tur: 3,547 QPS Claude Opus 4.6) przy zachowaniu ≥95% recall na SIFT-1M. Wykazywał „schodkowy” postęp z przełomami strukturalnymi co 100–200 iteracji.
- KernelBench Level 3 (pełna optymalizacja modelu ML, 1,000+ tur): Geometryczna średnia przyspieszenia 3.6× w 50 złożonych problemach (przewyższając 1.49× w torch.compile max-autotune). GLM-5.1 kontynuował poprawę długo po tym, jak GLM-5 osiągnął plateau; jedynie Claude Opus 4.6 nieznacznie go wyprzedził przy 4.2×.
- Linux Desktop Web App Build (8+ godzin, otwarty koniec): Dysponując jedynie poleceniem w języku naturalnym i bez kodu startowego, GLM-5.1 autonomicznie zbudował funkcjonalne środowisko pulpitu w stylu Linuksa — z paskiem zadań, oknami, interakcjami i dopracowaniem — podczas gdy wcześniejsze modele tworzyły tylko podstawowe szkielety.
Wyniki te pokazują zdolność GLM-5.1 do utrzymywania spójności, samooceny, rewizji strategii i wychodzenia z lokalnych optimum na ekstremalnie długich horyzontach — możliwości, które Z.ai celowo zaprojektowało z myślą o realnych systemach agentowych.
How is GLM-5.1 different from GLM-5?
GLM-5 i GLM-5.1 są blisko spokrewnione, ale są inaczej pozycjonowane. GLM-5 to wcześniejszy model bazowy Z.AI do Agentic Engineering. Został zaprojektowany do złożonej inżynierii systemów i długodystansowych zadań agentowych, z otwartymi wagami osiągającymi stan sztuki w kodowaniu i możliwościach agentowych, a jego wydajność w kodowaniu w realnych scenariuszach programistycznych zbliża się do Claude Opus 4.5. Osiąga 77.8 na SWE-bench Verified i 56.2 na Terminal Bench 2.0.
GLM-5.1 natomiast jest przedstawiany jako następny krok w kierunku zadań długoterminowych i bardziej niezawodnego, utrzymywanego wykonania; poprawia stabilność, spójność i użycie narzędzi w długich zadaniach i jest lepiej zestrojony ogólnie z Claude Opus 4.6. Innymi słowy, GLM-5 to wcześniejszy, zorientowany na inżynierię model bazowy, podczas gdy GLM-5.1 to flagowiec ukierunkowany na wytrzymałość zadaniową.
Istnieją również różnice architektoniczne i treningowe w generacji GLM-5, które pomagają wyjaśnić skok. GLM-5 rozszerzył się z 355B parametrów (32B aktywowanych) do 744B parametrów (40B aktywowanych), zwiększył dane pretreningowe z 23T do 28.5T, dodał asynchroniczny framework uczenia ze wzmocnieniem i zintegrował DeepSeek Sparse Attention w celu zachowania jakości długiego tekstu przy jednoczesnej poprawie efektywności. Te szczegóły dotyczą GLM-5, ale stanowią bazę, na której GLM-5.1 najwyraźniej buduje.
GLM-5.1 vs Other Frontier Models
GLM-5.1 wyróżnia się jako najsilniejszy kandydat open-source, oferując przekonujący stosunek ceny do wydajności.
Comparison Table: Major Coding & Agentic Benchmarks (April 2026)
| Model | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding Harness Score | Long-Horizon Sustained? | Open-Source? | Approx. API Price (Input/Output per M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% of Opus) | Yes (600+ iter, 8 hrs) | Yes | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Limited | Yes | Lower (pre-hike) |
| GPT-5.4 | 57.7 | — | — | — | Strong | No | Higher |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Strongest | No | ~250–470% more expensive |
| Gemini 3.1 Pro | 54.2 | — | — | — | Good | No | Higher |
Verdict: GLM-5.1 wygrywa pod względem dostępności open-source, kosztów i wybranych metryk długoterminowego kodowania. W agentowych scenariuszach rywalizuje z liderami zamkniętymi, jednocześnie demokratyzując czołowe możliwości.
Application scenarios of GLM-5.1
1) Autonomous software engineering
GLM-5.1 jest najbardziej przekonujący, gdy zadanie przypomina prawdziwy sprint inżynierski: przeczytaj bazę kodu, zaplanuj zmianę, wdroż ją, przetestuj, napraw regresje i iteruj do stabilnego rezultatu. Notatki wydawnicze Z.ai wprost podkreślają autonomiczne planowanie, utrzymywane wykonanie, naprawę błędów i iterację strategii, co sprawia, że model wydaje się stworzony dla agentów kodowania i potoków dostarczania oprogramowania.
2) Long-running agent workflows
Jeśli Twój przypadek użycia obejmuje wiele wywołań narzędzi, długie wieloetapowe przepływy lub powtarzalną autokorektę, projekt GLM-5.1 to mocne dopasowanie. Dokumentacja podkreśla wywoływanie narzędzi, ustrukturyzowane wyjście, integrację MCP i obsługę streamingu narzędzi — wszystko to jest przydatne, gdy model nie tylko odpowiada, lecz działa wewnątrz większego systemu.
3) Enterprise knowledge work and reporting
GLM-5.1 jest również pozycjonowany do zadań produktywności biurowej, takich jak przepływy PowerPoint, Word, PDF i Excel. Z.ai wskazuje na poprawę w złożonej organizacji treści, projektowaniu układu, ustrukturyzowanym wyjściu i wizualnym dopracowaniu, co czyni go wiarygodnym wyborem do generowania raportów, materiałów dydaktycznych, podsumowań badań i innych prac dokumentowych.
4) Front-end prototyping and artifacts
Z.ai twierdzi, że GLM-5.1 dobrze nadaje się do generowania stron internetowych, interaktywnych witryn i prototypowania front-endu, z mniejszą szablonowością i lepszą jakością realizacji zadań. Sugeruje to dobre dopasowanie dla zespołów produktowych potrzebujących szybkiego mostu od briefu do prototypu, zwłaszcza gdy prototyp ma być używalny, a nie tylko ładny.
5) Complex conversation and instruction-following
Choć nagłówkiem jest kodowanie, GLM-5.1 jest także opisywany jako silniejszy w otwartych pytaniach i odpowiedziach, złożonych instrukcjach i interakcjach wieloturowych. Czyni to go użytecznym w przepływach asystenckich, gdzie model musi śledzić ograniczenia, rewidować wyniki i zachować kontekst w dłuższych rozmowach.
Conclusion: Why GLM-5.1 Matters in 2026
GLM-5.1 to nie tylko kolejna iteracja — sygnalizuje pojawienie się naprawdę kompetentnej, open-source’owej agentowej AI. Dzięki świetnym wynikom w najtrudniejszych realnych benchmarkach inżynierskich, przy jednoczesnej przystępności i otwartości, Z.ai podnosi poprzeczkę dla całej branży. Niezależnie od tego, czy jesteś indywidualnym deweloperem, zespołem korporacyjnym, czy badaczem, GLM-5.1 oferuje niezrównaną autonomię w długoterminowych zadaniach kodowania za ułamek kosztów rozwiązań zastrzeżonych.
Ready to try it? Sprawdź model CometAPI GLM-5.1, repozytorium na Hugging Face lub GLM Coding Plan, aby uzyskać natychmiastowy dostęp.