

GPT-5.2 to wydana przez OpenAI w grudniu 2025 r. wersja punktowa z rodziny GPT-5: flagowa rodzina modeli multimodalnych (tekst + wizja + narzędzia) dostrojona do potrzeb pracy wiedzy na poziomie profesjonalnym, rozumowania w bardzo długim kontekście, agentowego użycia narzędzi oraz inżynierii oprogramowania. OpenAI pozycjonuje GPT-5.2 jako najbardziej zaawansowany model z serii GPT-5 do tej pory i twierdzi, że został opracowany z naciskiem na niezawodne rozumowanie wieloetapowe, obsługę bardzo dużych dokumentów oraz poprawę bezpieczeństwa i zgodności z zasadami; wydanie obejmuje trzy warianty skierowane do użytkowników — Instant, Thinking i Pro — i najpierw trafia do płatnych subskrybentów ChatGPT oraz klientów API.
Czym jest GPT-5.2 i dlaczego ma znaczenie?
GPT-5.2 to najnowszy członek rodziny GPT-5 — nowej serii modeli „frontier” zaprojektowanej specjalnie, by zniwelować lukę między asystentami konwersacyjnymi w pojedynczej turze a systemami, które muszą rozumować na podstawie długich dokumentów, wywoływać narzędzia, interpretować obrazy oraz niezawodnie wykonywać wieloetapowe przepływy pracy. OpenAI pozycjonuje 5.2 jako swoje najbardziej kompetentne wydanie do pracy wiedzy na poziomie profesjonalnym: ustanawia nowe rekordy na wewnętrznych benchmarkach (w szczególności nowy benchmark GDPval dla pracy wiedzy), wykazuje silniejszą wydajność w kodowaniu na benchmarkach inżynierii oprogramowania oraz oferuje znacząco poprawione możliwości w długim kontekście i w obszarze wizji.
W praktyce GPT-5.2 to więcej niż „większy model czatu”. To rodzina trzech dostrojonych wariantów (Instant, Thinking, Pro), które równoważą opóźnienia, głębokość rozumowania i koszt — i które, wraz z API OpenAI i trasowaniem w ChatGPT, mogą służyć do uruchamiania długich zadań badawczych, budowania agentów wywołujących zewnętrzne narzędzia, interpretowania złożonych obrazów i wykresów oraz generowania kodu produkcyjnej jakości z wyższą wiernością niż wcześniejsze wydania. Model obsługuje bardzo duże okna kontekstu (dokumenty OpenAI wymieniają 400 000 tokenów okna kontekstu i limit maksymalnego wyjścia 128 000 dla modeli flagowych), nowe funkcje API zapewniające jawne poziomy wysiłku rozumowania oraz „agentowe” zachowanie w wywoływaniu narzędzi.
5 kluczowych możliwości ulepszonych w GPT-5.2
1) czy GPT-5.2 jest lepszy w logice wieloetapowej i matematyce?
GPT-5.2 zapewnia ostrzejsze rozumowanie wieloetapowe i zauważalnie mocniejszą wydajność w matematyce i ustrukturyzowanym rozwiązywaniu problemów. OpenAI podaje, że dodano bardziej granularną kontrolę nad wysiłkiem rozumowania (nowe poziomy, takie jak xhigh), zaprojektowano wsparcie „tokenów rozumowania” oraz dostrojono model tak, by utrzymywał chain-of-thought na dłuższych wewnętrznych ścieżkach rozumowania. Benchmarki takie jak FrontierMath oraz testy w stylu ARC-AGI wykazują znaczące zyski względem GPT-5.1; Model osiąga większe marginesy na benchmarkach dziedzinowych używanych w workflowach naukowych i finansowych. Krótko mówiąc: GPT-5.2 „myśli dłużej” na żądanie i potrafi wykonywać bardziej skomplikowaną pracę symboliczną/matematyczną z lepszą spójnością.

| RC-AGI-1 (Zweryfikowane) Rozumowanie abstrakcyjne | 86.2% | 72.8% |
|---|---|---|
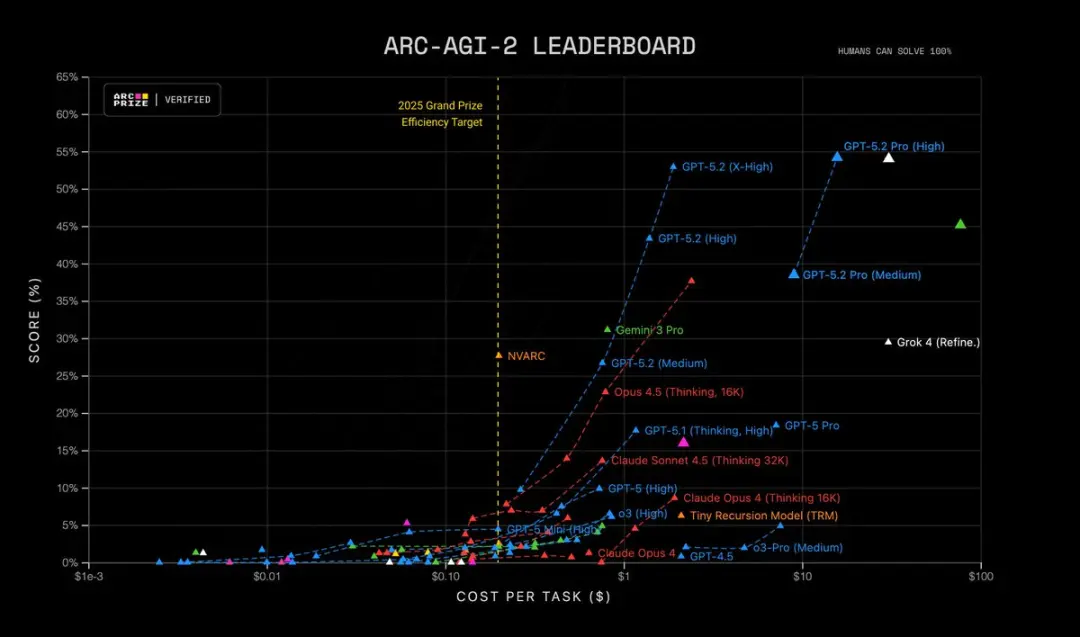
| ARC-AGI-2 (Zweryfikowane) Rozumowanie abstrakcyjne | 52.9% | 17.6% |
GPT-5.2 Thinking ustanawia rekordy w wielu zaawansowanych testach rozumowania naukowego i matematycznego:
- GPQA Diamond Science Quiz: 92.4% (wersja Pro 93.2%)
- ARC-AGI-1 Rozumowanie abstrakcyjne: 86.2% (pierwszy model, który przekroczył próg 90%)
- ARC-AGI-2 Rozumowanie wyższego rzędu: 52.9%, ustanawiając nowy rekord dla modelu Thinking Chain
- FrontierMath Zaawansowany test matematyki: 40.3%, znacznie przewyższając poprzednika;
- HMMT Zadania konkursowe z matematyki: 99.4%
- Test matematyczny AIME: 100% kompletnego rozwiązania
Co więcej, GPT-5.2 Pro (High) jest stanem sztuki na ARC-AGI-2, osiągając wynik 54.2% przy koszcie $15.72 na zadanie! Przewyższa wszystkie inne modele.
Dlaczego to ma znaczenie: wiele zadań w świecie rzeczywistym — modelowanie finansowe, projektowanie eksperymentów, synteza programów wymagająca formalnego rozumowania — jest ograniczonych przez zdolność modelu do połączenia wielu poprawnych kroków. GPT-5.2 redukuje „halucynowane kroki” i generuje bardziej stabilne pośrednie ślady rozumowania, gdy prosisz o pokazanie toku pracy.
2) Jak poprawiło się rozumienie długiego tekstu i rozumowanie między dokumentami?
Rozumienie długiego kontekstu to jedna z kluczowych popraw. Podstawowy model GPT-5.2 obsługuje okno kontekstu 400 tys. tokenów i — co ważne — utrzymuje wyższą dokładność, gdy relewantna treść przesuwa się głęboko w tym kontekście. GDPval, zestaw zadań dla „dobrze określonej pracy wiedzy” w 44 zawodach, gdzie GPT-5.2 Thinking osiąga parytet lub lepsze wyniki niż eksperccy sędziowie ludzcy w dużej części zadań. Niezależne raporty potwierdzają, że model znacznie lepiej niż wcześniejsze wersje utrzymuje i syntetyzuje informacje z wielu dokumentów. To autentyczny, praktyczny krok naprzód dla zadań takich jak due diligence, streszczenia prawne, przeglądy literatury oraz rozumienie baz kodu.
GPT-5.2 może obsługiwać konteksty do 256 000 tokenów (około 200+ stron dokumentów). Ponadto w teście rozumienia długiego tekstu „OpenAI MRCRv2” GPT-5.2 Thinking osiągnął dokładność bliską 100%.
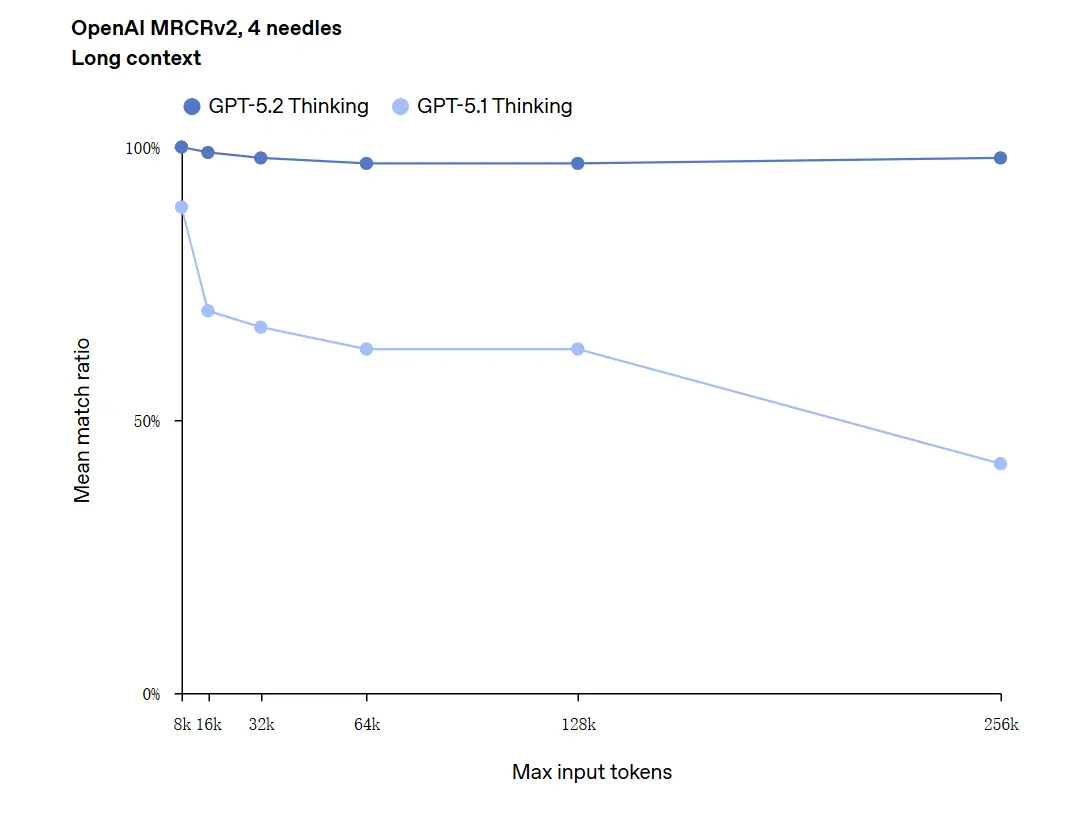
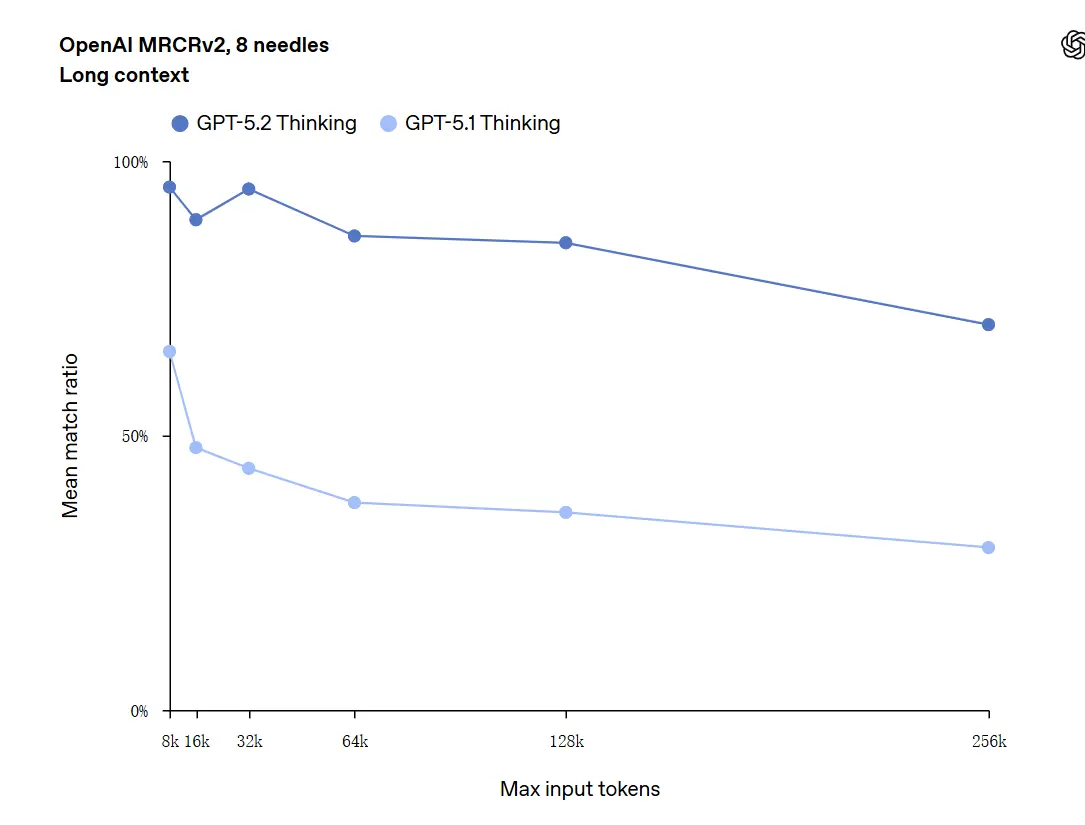
Zastrzeżenie dotyczące „100% dokładności”: Poprawy opisano jako „zbliżające się do 100%” dla wąskich mikrozadań; dane OpenAI lepiej opisać jako „stan sztuki i w wielu przypadkach na poziomie lub powyżej poziomu ludzkich ekspertów w ocenianych zadaniach”, nie dosłownie bezbłędne we wszystkich zastosowaniach. Benchmarki pokazują duże zyski, ale nie uniwersalną perfekcję.
3) Co nowego w rozumieniu obrazu i multimodalnym rozumowaniu?
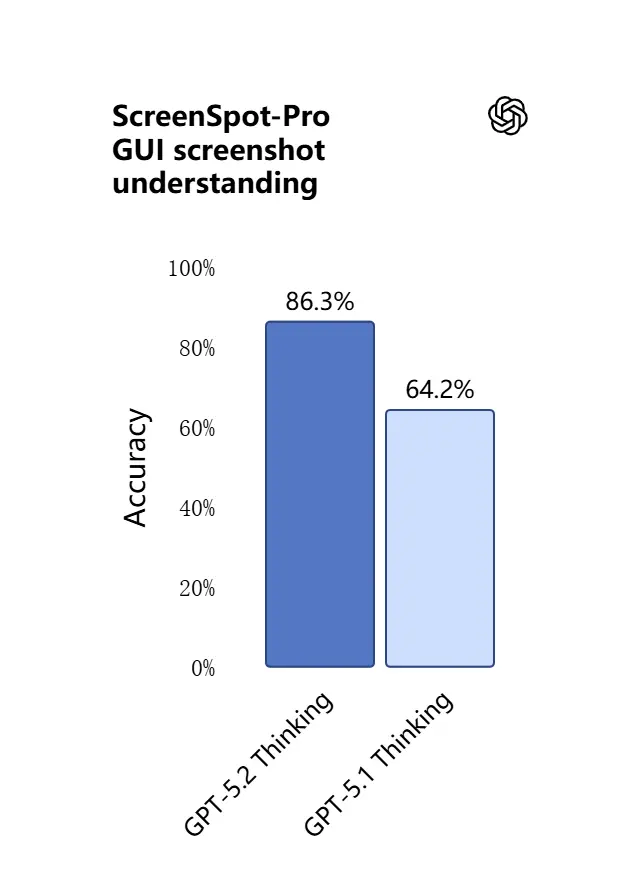
Możliwości wizji w GPT-5.2 są ostrzejsze i bardziej praktyczne. Model lepiej interpretuje zrzuty ekranu, odczytuje wykresy i tabele, rozpoznaje elementy interfejsu użytkownika oraz łączy wejścia wizualne z długim tekstowym kontekstem. To nie jest tylko opisywanie: GPT-5.2 potrafi wyodrębniać ustrukturyzowane dane z obrazów (np. tabele w PDF), wyjaśniać wykresy i rozumować o diagramach w sposób wspierający dalsze działania narzędzi (np. generowanie arkusza kalkulacyjnego na podstawie sfotografowanego raportu).
.webp)
Praktyczny efekt: zespoły mogą przekazywać całe prezentacje, zeskanowane raporty badawcze lub dokumenty bogate w obrazy bezpośrednio do modelu i prosić o syntezy międzydokumentowe — co znacząco redukuje ręczną pracę z wyodrębnianiem.
4) Jak zmieniły się wywoływanie narzędzi i wykonywanie zadań?
GPT-5.2 dalej wchodzi w zachowanie agentowe: lepiej planuje zadania wieloetapowe, decyduje, kiedy wywołać zewnętrzne narzędzia, oraz wykonuje sekwencje wywołań API/narzędzi, aby zakończyć zadanie od początku do końca. Ulepszenia „agentowego wywoływania narzędzi” — model zaproponuje plan, wywoła narzędzia (bazy danych, obliczenia, systemy plików, przeglądarkę, uruchamianie kodu) i zsyntetyzuje wyniki w końcowy produkt bardziej niezawodnie niż wcześniejsze modele. API wprowadza trasowanie i kontrolki bezpieczeństwa (listy dozwolonych narzędzi, rusztowanie narzędzi), a interfejs ChatGPT może automatycznie kierować żądania do odpowiedniego wariantu 5.2 (Instant vs Thinking).
GPT-5.2 uzyskał 98.7% w benchmarku Tau2-Bench Telecom, demonstrując dojrzałe możliwości wywoływania narzędzi w złożonych zadaniach wieloturnowych.
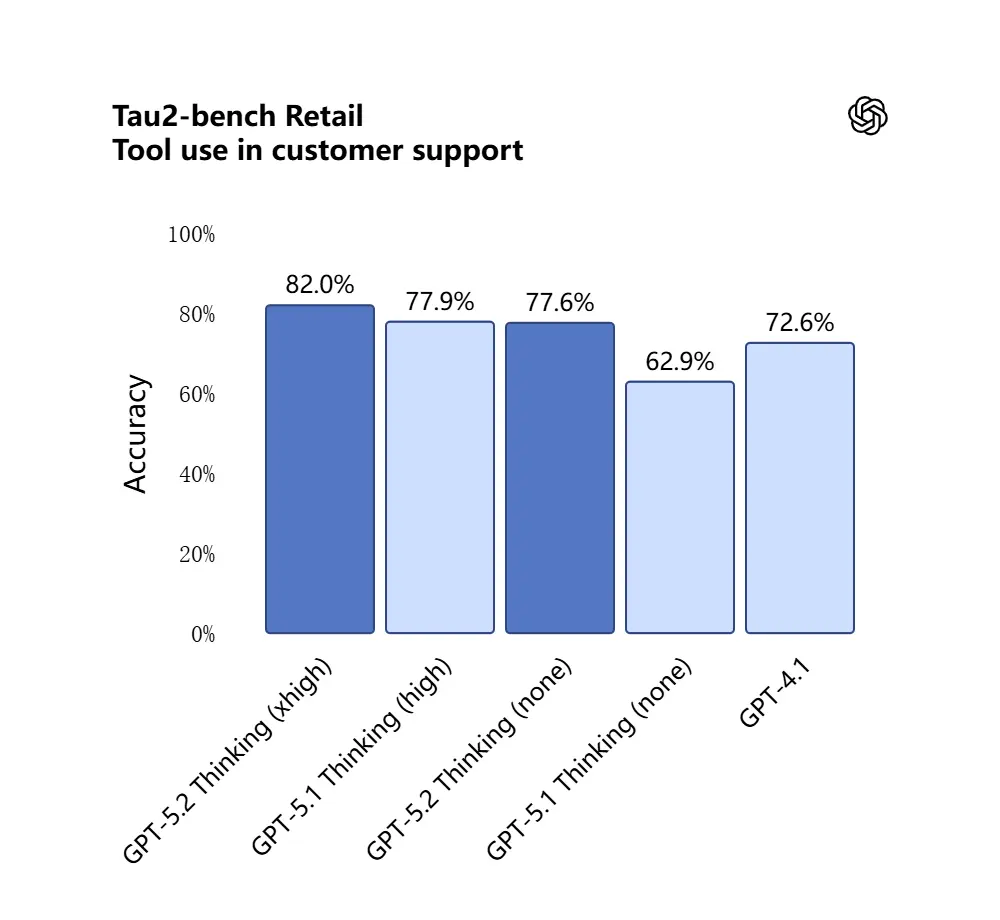
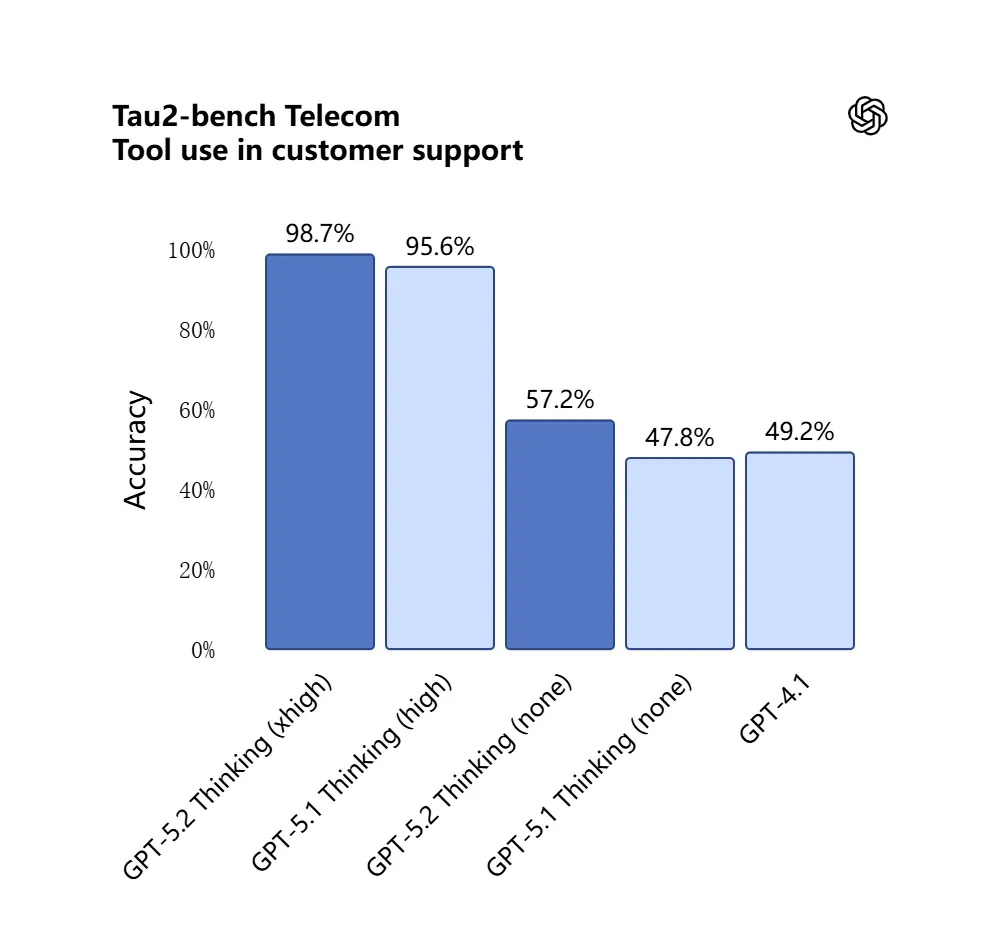
Dlaczego to ma znaczenie: czyni to GPT-5.2 bardziej użytecznym jako autonomiczny asystent dla przepływów pracy typu „wczytaj te umowy, wyodrębnij klauzule, zaktualizuj arkusz i napisz e-mail podsumowujący” — zadań, które wcześniej wymagały starannej orkiestracji.
5) Rozwinięte możliwości programistyczne
GPT-5.2 jest wyraźnie lepszy w zadaniach inżynierii oprogramowania: pisze bardziej kompletne moduły, niezawodniej generuje i uruchamia testy, rozumie złożone grafy zależności projektów i jest mniej podatny na „leniwe kodowanie” (pomijanie boilerplate lub niewłaściwe łączenie modułów). Na branżowych benchmarkach kodowania (SWE-bench Pro, itd.) GPT-5.2 ustanawia nowe rekordy. Dla zespołów korzystających z LLM jako partnerów programowania ta poprawa może zmniejszyć wymaganą ręczną weryfikację i prace poprawkowe po generowaniu.
W teście SWE-Bench Pro (realistyczne przemysłowe zadanie inżynierii oprogramowania) wynik GPT-5.2 Thinking poprawił się do 55.6%, a na teście SWE-Bench Verified osiągnął nową wartość szczytową 80%.
_Software%20engineering.webp)
W zastosowaniach praktycznych oznacza to:
- Automatyczne debugowanie kodu środowiska produkcyjnego prowadzi do większej stabilności;
- Wsparcie dla programowania wielojęzycznego (nie tylko Python);
- Zdolność do samodzielnego ukończenia zadań naprawczych typu end-to-end.
Czym różni się GPT-5.2 od GPT-5.1?
Krótko mówiąc: GPT-5.2 to iteracyjne, ale istotne usprawnienie. Zachowuje architekturę rodziny GPT-5 i podstawy multimodalne, ale rozwija cztery praktyczne wymiary:
- Głębokość i spójność rozumowania. 5.2 wprowadza wyższe poziomy wysiłku rozumowania oraz lepsze łańczenie dla problemów wieloetapowych; 5.1 wcześniej poprawił rozumowanie, ale 5.2 podnosi poprzeczkę dla złożonej matematyki i logiki wielostopniowej.
- Niezawodność w długim kontekście. Obie wersje rozszerzyły kontekst, ale 5.2 jest dostrojony tak, by utrzymywać dokładność głęboko w bardzo długich wejściach (OpenAI twierdzi o poprawionej retencji do setek tysięcy tokenów).
- Wierność wizji + multimodalności. 5.2 poprawia krzyżowe odniesienia między obrazami a tekstem — np. odczytywanie wykresu i integrowanie tych danych w arkuszu kalkulacyjnym — wykazując wyższą dokładność na poziomie zadania.
- Agentowe zachowanie przy narzędziach i funkcje API. 5.2 udostępnia nowe parametry wysiłku rozumowania (
xhigh) oraz funkcje kompresji kontekstu w API, a OpenAI dopracował logikę trasowania w ChatGPT, by interfejs mógł automatycznie dobrać najlepszy wariant. - Mniej błędów, większa stabilność: GPT-5.2 redukuje swój „wskaźnik iluzji” (odsetek fałszywych odpowiedzi) o 38%. Odpowiada na pytania badawcze, pisarskie i analityczne bardziej niezawodnie, zmniejszając przypadki „sfabrykowanych faktów”. W złożonych zadaniach jego strukturalne wyniki są jaśniejsze, a logika bardziej stabilna. Jednocześnie bezpieczeństwo odpowiedzi modelu jest znacząco poprawione w zadaniach związanych ze zdrowiem psychicznym. Działa bardziej robustowo w wrażliwych scenariuszach, takich jak zdrowie psychiczne, samookaleczenia, samobójstwo i zależność emocjonalna.
W ewaluacjach systemowych GPT-5.2 Instant uzyskał 0.995 (na 1.0) w zadaniu „Wsparcie zdrowia psychicznego”, znacząco wyżej niż GPT-5.1 (0.883).
Ilościowo, opublikowane przez OpenAI benchmarki pokazują mierzalne zyski na GDPval, benchmarkach matematycznych (FrontierMath) i ewaluacjach inżynierii oprogramowania. GPT-5.2 przewyższa GPT-5.1 w zadaniach arkuszy kalkulacyjnych na poziomie młodszego bankowca inwestycyjnego o kilka punktów procentowych.
Czy GPT-5.2 jest darmowy — ile kosztuje?
Czy mogę używać GPT-5.2 za darmo?
OpenAI wprowadza GPT-5.2 zaczynając od płatnych planów ChatGPT i dostępu do API. Historycznie OpenAI utrzymywało najszybsze/najgłębsze modele w płatnych tierach, udostępniając później lżejsze warianty szerzej; w przypadku 5.2 firma przekazała, że rollout zacznie się od planów płatnych (Plus, Pro, Business, Enterprise), a API jest dostępne dla deweloperów. Oznacza to ograniczony natychmiastowy dostęp bezpłatny: darmowy tier może później otrzymać zdegradowany lub trasowany dostęp (np. do lżejszych subwariantów) w miarę skalowania wdrożenia przez OpenAI.
Dobra wiadomość jest taka, że CometAPI integruje się teraz z GPT-5.2, a obecnie trwa wyprzedaż świąteczna. Możesz teraz używać GPT-5.2 poprzez CometAPI; playground umożliwia swobodną interakcję z GPT-5.2, a deweloperzy mogą używać API GPT-5.2 (CometAPI jest wycenione na 20% ceny OpenAI) do budowy przepływów pracy.
Ile kosztuje przez API (użycie deweloperskie/produkcyjne)?
Użycie API rozliczane jest per token. Opublikowane ceny platformy OpenAI na starcie pokazują (CometAPI jest wycenione na 20% ceny OpenAI):
- GPT-5.2 (standardowy czat) — $1.75 na 1M tokenów wejściowych i $14 na 1M tokenów wyjściowych (obowiązują zniżki na cache’owane wejścia).
- GPT-5.2 Pro (flagowy) — $21 na 1M tokenów wejściowych i $168 na 1M tokenów wyjściowych (znacznie droższy, ponieważ przeznaczony jest do obciążeń wymagających wysokiej dokładności i dużych zasobów obliczeniowych).
- Dla porównania, GPT-5.1 był tańszy (np. $1.25 wejście / $10 wyjście na 1M tokenów).
Interpretacja: Koszty API wzrosły względem poprzednich generacji; ceny sygnalizują, że premium rozumowanie i wydajność w długim kontekście w 5.2 są wycenione jako odrębny tier produktu. W systemach produkcyjnych koszty planu zależą w dużym stopniu od liczby tokenów wejścia/wyjścia oraz od tego, jak często ponownie używasz cache’owanych wejść (cache’owane wejścia otrzymują duże zniżki).
Co to oznacza w praktyce
- Dla użycia okazjonalnego przez interfejs ChatGPT, miesięczne plany subskrypcji (Plus, Pro, Business, Enterprise) są główną ścieżką. Ceny tierów subskrypcyjnych ChatGPT nie zmieniły się wraz z wydaniem 5.2 (OpenAI utrzymuje stabilne ceny planów, nawet jeśli oferta modeli się zmienia).
- Dla produkcji i deweloperów należy budżetować koszty tokenów. Jeśli Twoja aplikacja streamuje dużo długich odpowiedzi lub przetwarza długie dokumenty, wycena tokenów wyjściowych ($14 / 1M tokenów dla Thinking) będzie dominować koszty, chyba że ostrożnie cache’ujesz wejścia i ponownie używasz wyjść.
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAI uruchomił GPT-5.2 z trzema wariantami dopasowanymi do przypadków użycia: Instant, Thinking i Pro:
- GPT-5.2 Instant: Szybki, ekonomiczny, dostrojony do pracy codziennej — FAQ, instrukcje, tłumaczenia, szybkie szkice. Niższe opóźnienie; dobre pierwsze szkice i proste workflowy.
- GPT-5.2 Thinking: Głębsze, wyższej jakości odpowiedzi dla pracy ciągłej — streszczanie długich dokumentów, planowanie wieloetapowe, szczegółowe przeglądy kodu. Zrównoważone opóźnienie i jakość; domyślny „wołek roboczy” do zadań profesjonalnych.
- GPT-5.2 Pro: Najwyższa jakość i wiarygodność. Wolniejszy i droższy; najlepszy do trudnych, wysokostawkowych zadań (złożona inżynieria, synteza prawna, decyzje o dużej wartości) oraz tam, gdzie wymagany jest „xhigh” poziom wysiłku rozumowania.
Tabela porównawcza
| Funkcja / Metryka | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| Przeznaczenie | Codzienne zadania, szybkie szkice | Głęboka analiza, długie dokumenty | Najwyższa jakość, złożone problemy |
| Opóźnienie | Najniższe | Umiarkowane | Najwyższe |
| Poziom wysiłku rozumowania | Standardowy | Wysoki | xHigh dostępne |
| Najlepsze do | FAQ, tutoriale, tłumaczenia, krótkie prompty | Streszczenia, planowanie, arkusze, zadania kodowania | Złożona inżynieria, synteza prawna, badania |
| Przykładowe nazwy API | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| Cena tokenów wejściowych (API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| Cena tokenów wyjściowych (API) | $14 / 1M | $14 / 1M | $168 / 1M |
| Dostępność (ChatGPT) | Wdrażane; najpierw plany płatne, potem szerzej | Wdrażane do planów płatnych | Użytkownicy Pro / Enterprise (płatne) |
| Przykładowe zastosowanie | Szkicowanie e-maila, drobne fragmenty kodu | Budowa wieloarkuszowego modelu finansowego, Q&A z długimi raportami | Audyt bazy kodu, generowanie projektu systemu produkcyjnej jakości |
Kto powinien korzystać z GPT-5.2?
GPT-5.2 został zaprojektowany z myślą o szerokim zestawie docelowych użytkowników. Poniżej rekomendacje według ról:
Przedsiębiorstwa i zespoły produktowe
Jeśli tworzysz produkty do pracy wiedzy (asystenci badawczy, przegląd umów, pipeline’y analityczne lub narzędzia deweloperskie), możliwości długiego kontekstu i zachowanie agentowe w GPT-5.2 mogą znacząco zredukować złożoność integracji. Przedsiębiorstwa potrzebujące solidnego rozumienia dokumentów, zautomatyzowanego raportowania lub inteligentnych copilotów znajdą Thinking/Pro użytecznymi. Microsoft i inni partnerzy platformowi już integrują 5.2 w stosach produktywności (np. Microsoft 365 Copilot).
Deweloperzy i zespoły inżynieryjne
Zespoły chcące używać LLM jako partnerów programowania lub automatyzować generowanie/testowanie kodu skorzystają z poprawionej wierności programowania w 5.2. Dostęp do API (z trybami thinking lub pro) umożliwia głębsze syntezy dużych baz kodu dzięki oknu kontekstu 400k tokenów. Oczekuj wyższych kosztów w API przy użyciu Pro, ale redukcja ręcznego debugowania i przeglądu może uzasadniać ten koszt dla złożonych systemów.
Badacze i analitycy skupieni na danych
Jeśli regularnie syntetyzujesz literaturę, parsujesz długie raporty techniczne lub chcesz projektować eksperymenty z pomocą modelu, długi kontekst i ulepszenia matematyczne w GPT-5.2 przyspieszają przepływy pracy. Dla badań replikowalnych połącz model z starannym inżynierią promptów i krokami weryfikacji.
Małe firmy i power userzy
ChatGPT Plus (oraz Pro dla power userów) będzie miał trasowany dostęp do wariantów 5.2; to sprawia, że zaawansowana automatyzacja i wysokiej jakości wyniki są osiągalne dla mniejszych zespołów bez budowy integracji API. Dla użytkowników nietechnicznych, którzy potrzebują lepszego streszczania dokumentów lub tworzenia slajdów, GPT-5.2 wnosi zauważalną praktyczną wartość.
Praktyczne uwagi dla deweloperów i operatorów
Funkcje API, na które warto zwrócić uwagę
- Poziomy
reasoning.effort(np.medium,high,xhigh) pozwalają określić modelowi, ile obliczeń ma przeznaczyć na wewnętrzne rozumowanie; używaj tego, aby na żądanie wymieniać opóźnienie na dokładność. - Kompakcja kontekstu: API zawiera narzędzia do kompresji i kompaktowania historii tak, aby rzeczywiście relewantna treść była zachowana w długich łańcuchach. To kluczowe, gdy musisz utrzymać efektywne użycie tokenów w ryzach.
- Rusztowanie narzędzi i kontrola dozwolonych narzędzi: systemy produkcyjne powinny jawnie whitelistować, co model może wywołać, oraz logować wywołania narzędzi do audytu.
Wskazówki kontroli kosztów
- Cache’uj często używane osadzenia dokumentów i używaj cache’owanych wejść (które otrzymują duże zniżki) dla powtarzanych zapytań względem tego samego korpusu. Cennik platformy OpenAI uwzględnia znaczące zniżki dla cache’owanych wejść.
- Kieruj eksploracyjne/małowartościowe zapytania do Instant, a Thinking/Pro zostaw dla zadań wsadowych lub finalnych przeglądów.
- Ostrożnie szacuj użycie tokenów (wejście + wyjście) przy prognozowaniu kosztów API, ponieważ długie wyjścia multiplikują koszt.
Konkluzja — czy warto przejść na GPT-5.2?
Jeśli Twoja praca zależy od rozumowania na podstawie długich dokumentów, syntezy między dokumentami, multimodalnej interpretacji (obrazy + tekst) lub budowy agentów wywołujących narzędzia, GPT-5.2 to jednoznaczny upgrade: podnosi praktyczną dokładność i redukuje manualną pracę integracyjną. Jeśli przede wszystkim uruchamiasz chatboty o dużej przepustowości i niskim opóźnieniu lub masz rygorystyczne ograniczenia budżetowe, Instant (lub wcześniejsze modele) może nadal być rozsądnym wyborem.
GPT-5.2 reprezentuje zamierzony zwrot z „lepszego czatu” w stronę „lepszego profesjonalnego asystenta”: więcej obliczeń, więcej możliwości i wyższe tier’y cenowe — ale także realne zyski produktywności dla zespołów, które potrafią wykorzystać niezawodny długi kontekst, ulepszone rozumowanie/matematykę, rozumienie obrazów i agentowe wykonywanie narzędzi.
Aby zacząć, poznaj możliwości modeli GPT-5.2 (GPT-5.2;GPT-5.2 pro, GPT-5.2 chat) w Playground i zapoznaj się z API guide po szczegółowe instrukcje. Przed dostępem upewnij się, że zalogowano się do CometAPI i uzyskano klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby ułatwić integrację.
Gotowi do działania?→ Bezpłatna wersja próbna modeli gpt-5.2 !