

GPT-5-Codex to nowa, skoncentrowana na inżynierii odmiana GPT-5 firmy OpenAI, dostosowana specjalnie do inżynierii oprogramowania agentowego w rodzinie produktów Codex. Została zaprojektowana z myślą o dużych, rzeczywistych procesach inżynieryjnych: tworzeniu pełnych projektów od podstaw, dodawaniu funkcji i testów, debugowaniu, refaktoryzacji i przeprowadzaniu przeglądów kodu przy jednoczesnej interakcji z zewnętrznymi narzędziami i zestawami testów. To wydanie stanowi ukierunkowane udoskonalenie produktu, a nie zupełnie nowy model bazowy: OpenAI zintegrowało GPT-5-Codex z Codex CLI, rozszerzeniem Codex IDE, Codex Cloud, przepływami pracy GitHub oraz mobilnymi środowiskami ChatGPT; dostępność API jest planowana, ale nie natychmiastowa.
Czym jest Kodeks GPT-5 i dlaczego powstał?
GPT-5-Codex to GPT-5 „specjalistyczny dla kodowania”. Zamiast być ogólnym asystentem konwersacyjnym, jest on dostrojony i trenowany z wykorzystaniem uczenia wzmacniającego i zestawów danych specyficznych dla inżynierii, aby lepiej wspierać iteracyjne zadania kodowania wspomagane narzędziami (np. uruchamianie testów, iterowanie po błędach, refaktoryzacja modułów i przestrzeganie konwencji PR). OpenAI postrzega go jako następcę wcześniejszych projektów Codex, ale opiera się na szkielecie GPT-5, aby zwiększyć głębię rozumowania w przypadku dużych baz kodu i umożliwić bardziej niezawodne wykonywanie wieloetapowych zadań inżynieryjnych.
Motywacja jest praktyczna: przepływy pracy programistów coraz częściej opierają się na agentach, którzy potrafią zrobić więcej niż tylko sugestie oparte na pojedynczych fragmentach kodu. Poprzez dopasowanie modelu do pętli „generuj → uruchom testy → napraw → powtórz” oraz do norm PR organizacji, OpenAI dąży do stworzenia sztucznej inteligencji, która będzie dawała poczucie przynależności do zespołu, a nie źródło jednorazowych zadań. To przejście od „generowania funkcji” do „dostarczania funkcjonalności” stanowi unikalną wartość tego modelu.
W jaki sposób jest tworzony i trenowany GPT-5-Codex?
Architektura wysokiego poziomu
GPT-5-Codex to wariant architektury GPT-5 (szerszej linii GPT-5), a nie architektura stworzona od podstaw. Oznacza to, że dziedziczy ona podstawową konstrukcję GPT-5 opartą na transformatorach, właściwości skalowania i ulepszenia wnioskowania, ale dodaje specyficzne dla Codexu funkcje trenowania i precyzyjnego dostrajania oparte na uczeniu maszynowym (RL), ukierunkowane na zadania inżynierii oprogramowania. Dodatek OpenAI opisuje GPT-5-Codex jako trenowany w oparciu o złożone, rzeczywiste zadania inżynieryjne i kładzie nacisk na uczenie wzmacniające w środowiskach, w których kod jest wykonywany i walidowany.
W jaki sposób został on przeszkolony i zoptymalizowany pod kątem kodu?
Program treningowy GPT-5-Codex kładzie nacisk zadania inżynierskie w świecie rzeczywistymWykorzystuje on precyzyjne dostrajanie w stylu uczenia się przez wzmacnianie (ang. reinforced learning) na zestawach danych i środowiskach zbudowanych z namacalnych przepływów pracy w procesie tworzenia oprogramowania: refaktoryzacji wieloplikowych, różnic PR, uruchamiania zestawów testów, sesji debugowania i sygnałów recenzji dokonywanych przez ludzi. Celem szkolenia jest maksymalizacja poprawności edycji kodu, zaliczenie testów i generowanie komentarzy do recenzji o wysokiej precyzji i trafności. To właśnie ta koncentracja odróżnia Codex od ogólnego dostrajania zorientowanego na czat: funkcje strat, uprzęże ewaluacyjne i sygnały nagrody są dostosowane do wyników inżynieryjnych (zaliczenie testów, poprawność różnic, mniej zbędnych komentarzy).
Jak wygląda szkolenie „agentów”
- Dostrajanie oparte na wykonaniuModel jest trenowany w kontekstach, w których wygenerowany kod jest wykonywany, testowany i oceniany. Pętle sprzężenia zwrotnego pochodzą z wyników testów i sygnałów preferencji człowieka, co zachęca model do iteracji, aż do zaliczenia zestawu testów.
- Uczenie się ze wzmocnieniem na podstawie informacji zwrotnych od ludzi (RLHF):Podobne w duchu do wcześniejszych prac RLHF, ale zastosowane do zadań kodowania wieloetapowego (tworzenie PR, uruchamianie testów, naprawianie błędów), dzięki czemu model uczy się przypisywania zasług czasowych na przestrzeni sekwencji działań.
- Kontekst na skalę repozytorium:Szkolenie i ocena obejmują duże repozytoria i refaktoryzacje, pomagając modelowi nauczyć się rozumowania międzyplikowego, konwencji nazewnictwa i wpływu na poziom bazy kodu. ()
W jaki sposób GPT-5-Codex radzi sobie z używaniem narzędzi i interakcjami ze środowiskiem?
Kluczową cechą architektoniczną modelu jest ulepszona zdolność do wywoływania i koordynowania narzędzi. Codex tradycyjnie łączył wyniki modelu z niewielkim systemem wykonawczym/agentem, który mógł uruchamiać testy, otwierać pliki lub wywoływać wyszukiwanie. GPT-5-Codex rozszerza tę funkcjonalność, ucząc się, kiedy wywoływać narzędzia i lepiej integrując informacje zwrotne z testów z późniejszą generacją kodu – skutecznie zamykając pętlę między syntezą a weryfikacją. Osiąga się to poprzez trenowanie na trajektoriach, gdzie model zarówno wydaje akcje (np. „uruchom test X”), jak i warunkuje późniejsze generacje na podstawie wyników testów i różnic.
Co właściwie potrafi GPT-5-Codex — jakie są jego funkcje?
Jedną z najważniejszych innowacji produktowych jest czas trwania adaptacyjnego myśleniaGPT-5-Codex dostosowuje zakres przeprowadzanego ukrytego wnioskowania: trywialne żądania działają szybko i tanio, podczas gdy złożone refaktoryzacje lub długotrwałe zadania pozwalają modelowi „myśleć” znacznie dłużej. Jednocześnie, w przypadku krótkich, interaktywnych tur, model zużywa znacznie mniej tokenów niż instancja GPT-5 ogólnego przeznaczenia, oszczędzając 93.7% tokenów (wliczając wnioskowanie i dane wyjściowe) w porównaniu z GPT-5. Ta strategia zmiennego wnioskowania ma na celu generowanie szybkich odpowiedzi w razie potrzeby oraz dogłębnego, dokładnego wykonania, gdy jest to uzasadnione.
Podstawowe możliwości
- Generowanie projektu i bootstrapping: Twórz kompletne szkielety projektów z CI, testami i podstawową dokumentacją z poziomu monitów wysokiego poziomu.
- Testowanie agentowe i iteracja: Generuj kod, uruchamiaj testy, analizuj błędy, łataj kod i uruchamiaj ponownie, aż testy zakończą się powodzeniem — skutecznie automatyzując części pętli programisty: edycja → test → naprawa.
- Refaktoryzacja na dużą skalę: Przeprowadzaj systematyczne refaktoryzacje w wielu plikach, zachowując przy tym zachowanie i testy. Jest to obszar optymalizacji dla GPT-5-Codex w porównaniu z generycznym GPT-5.
- Przegląd kodu i generowanie PR: Tworzenie opisów PR, sugerowanie zmian wraz z różnicami oraz przeglądanie komentarzy zgodnych z konwencjami projektu i oczekiwaniami dotyczącymi przeglądu przez człowieka.
- Rozumowanie kodu w dużym kontekście: Lepsza nawigacja i rozumowanie na temat wieloplikowych baz kodu, grafów zależności i granic API w porównaniu z ogólnymi modelami czatu.
- Dane wejściowe i wyjściowe wizualne: Pracując w chmurze, GPT-5-Codex może akceptować obrazy/zrzuty ekranu, wizualnie kontrolować postępy i dołączać artefakty wizualne (zrzuty ekranu utworzonego interfejsu użytkownika) do zadań — co jest praktycznym ułatwieniem w debugowaniu front-end i wizualnych procesach zapewniania jakości.
Integracje edytorów i przepływów pracy
Codex jest głęboko zintegrowany z procesami pracy programistów:
- Interfejs CLI Kodeksu — interakcja terminal-first, obsługuje zrzuty ekranu, śledzenie zadań i zatwierdzanie przez agentów. Interfejs wiersza poleceń jest open source i dostosowany do przepływów pracy w programowaniu agentów.
- Rozszerzenie Codex IDE — osadza agenta w kodzie VS Code (i forkach), dzięki czemu można przeglądać lokalne różnice, tworzyć zadania w chmurze i przenosić pracę między kontekstami w chmurze i lokalnymi z zachowaniem stanu.
- Codex Cloud / GitHub — zadania w chmurze można skonfigurować tak, aby automatycznie przeglądały żądania ściągnięcia, tworzyły tymczasowe kontenery do testowania oraz dołączały dzienniki zadań i zrzuty ekranu do wątków żądań ściągnięcia.
Istotne ograniczenia i kompromisy
- Wąska optymalizacja: Niektóre oceny produkcyjne bez kodu są nieco niższe w przypadku GPT-5-Codex niż w przypadku ogólnej odmiany GPT-5 — to przypomnienie, że specjalizacja może oznaczać kompromis w kwestii ogólności.
- Zaufanie do testówZachowanie agenta zależy od dostępnych testów automatycznych. Bazy kodu o słabym pokryciu testami ujawnią ograniczenia automatycznej weryfikacji i mogą wymagać nadzoru ze strony człowieka.
W jakich zadaniach GPT-5-Codex sprawdza się szczególnie dobrze lub słabo?
Dobry w: złożone refaktoryzacje, tworzenie rusztowań dla dużych projektów, pisanie i naprawianie testów, spełnianie oczekiwań PR i diagnozowanie problemów w czasie wykonywania wielu plików.
Mniej dobry w: zadania wymagające aktualnej lub zastrzeżonej wiedzy wewnętrznej, która nie jest dostępna w środowisku roboczym, lub te, które wymagają wysokiej jakości poprawności bez weryfikacji przez człowieka (systemy krytyczne dla bezpieczeństwa nadal potrzebują ekspertów). Niezależne analizy wskazują również na zróżnicowany obraz jakości kodu surowego w porównaniu z innymi specjalistycznymi modelami kodowania — mocne strony przepływów pracy opartych na agentach nie przekładają się jednolicie na najwyższą w swojej klasie poprawność w każdym teście porównawczym.
Co testy wydajnościowe ujawniają na temat wydajności GPT-5-Codex?
SWE-bench / SWE-bench Zweryfikowany:OpenAI stwierdza, że GPT-5-Codex przewyższa GPT-5 w testach porównawczych kodowania agentowego, takich jak SWE-bench Verified, i wykazuje poprawę w zadaniach refaktoryzacji kodu pochodzących z dużych repozytoriów. W zestawie danych SWE-bench Verified, zawierającym 500 rzeczywistych zadań inżynierii oprogramowania, GPT-5-Codex osiągnął wskaźnik sukcesu na poziomie 74.5%. To przewyższa 5% GPT-72.8 w tym samym teście porównawczym, co podkreśla ulepszone możliwości agenta. 500 zadań programistycznych z rzeczywistych projektów open source. Wcześniej można było przetestować tylko 477 zadań, ale teraz można przetestować wszystkie 500 zadań → pełniejsze wyniki.
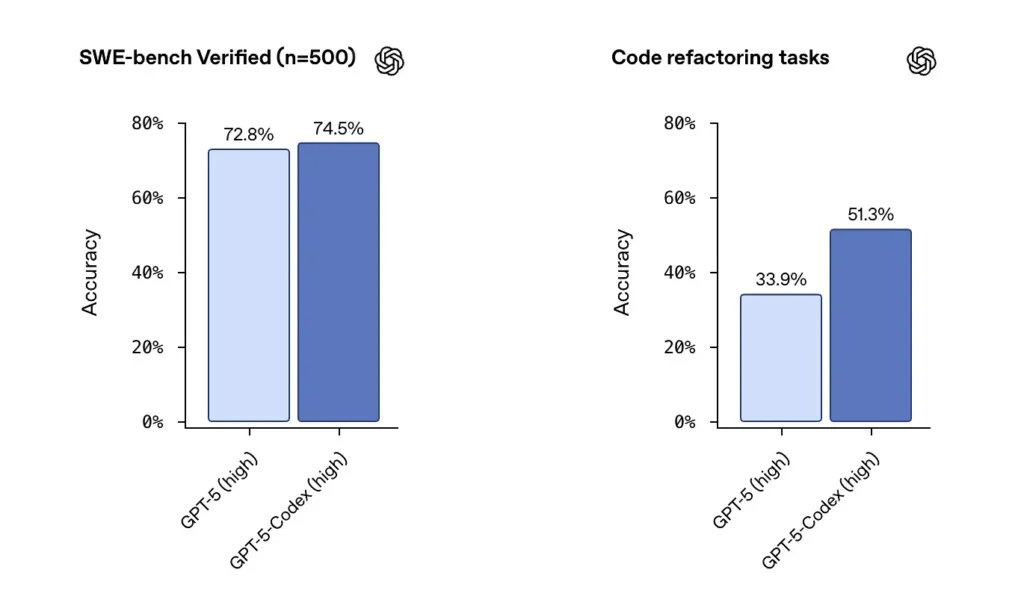
od wcześniejszych ustawień GPT-5 do GPT-5-Codex, wyniki oceny refaktoryzacji kodu znacząco wzrosły — wczesne analizy podkreślały takie liczby, jak zmiana z ~34% do ~51% w przypadku określonej metryki refaktoryzacji o dużej szczegółowości). Te korzyści są znaczące, ponieważ odzwierciedlają poprawę duże, realistyczne refaktoryzacje raczej niż przykłady zabawowe — ale nadal istnieją zastrzeżenia co do powtarzalności i dokładnego zakresu testów.
W jaki sposób programiści i zespoły mogą uzyskać dostęp do GPT-5-Codex?
OpenAI zintegrowało GPT-5-Codex z platformą Codex: jest ona dostępna wszędzie tam, gdzie obecnie działa Codex (na przykład w interfejsie wiersza poleceń Codex i zintegrowanych środowiskach Codex). Dla programistów korzystających z Codex za pośrednictwem interfejsu wiersza poleceń i logowania ChatGPT, zaktualizowane środowisko Codex będzie zawierało model GPT-5-Codex. Firma OpenAI zapowiedziała, że model ten zostanie udostępniony w szerszym API „wkrótce” dla użytkowników korzystających z kluczy API, ale od momentu wdrożenia główną ścieżką dostępu są narzędzia Codex, a nie publiczny punkt końcowy API.
Interfejs CLI Kodeksu
Włącz funkcję Codex, aby przeglądać wersje robocze żądań dostępu (PR) w repozytorium sandboxowym, co pozwoli Ci ocenić jakość komentarzy bez ryzyka. Używaj trybów zatwierdzania ostrożnie.
- Zaprojektowano na nowo w oparciu o przepływ kodowania agentowego.
- Obsługa dołączania obrazów (takich jak modele szkieletowe, projekty i zrzuty ekranu pokazujące błędy interfejsu użytkownika) zapewnia kontekst dla modeli.
- Dodano funkcję listy zadań umożliwiającą śledzenie postępu złożonych zadań.
- Zapewniono wsparcie narzędzi zewnętrznych (wyszukiwarka internetowa, połączenie MCP).
- Nowy interfejs terminala usprawnia wywoływanie narzędzi i formatowanie różnic, a tryb uprawnień został uproszczony do trzech poziomów (tylko do odczytu, automatyczny i pełny dostęp).
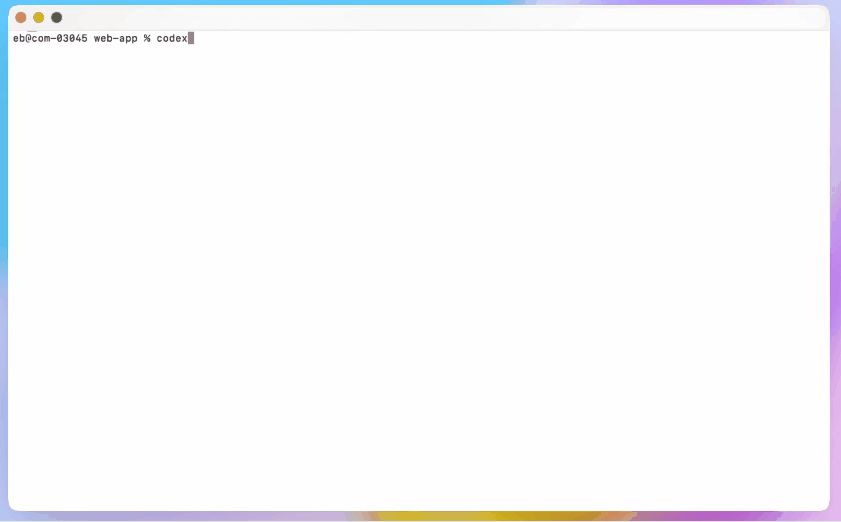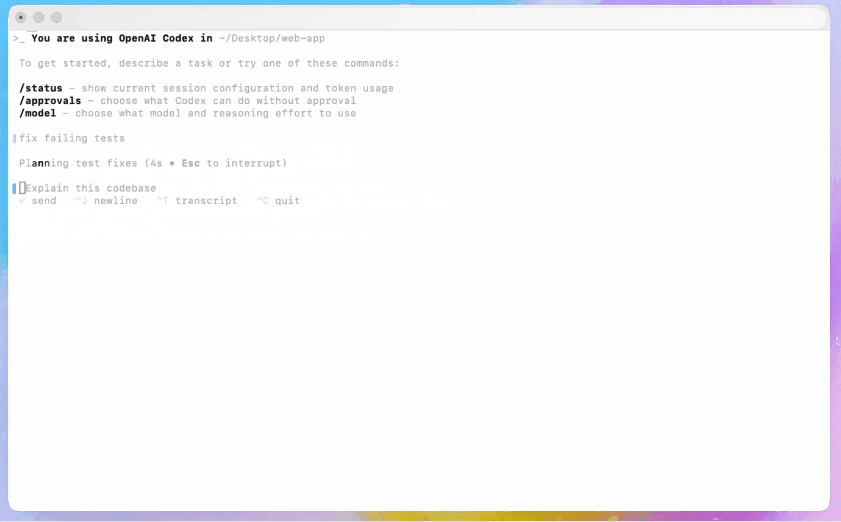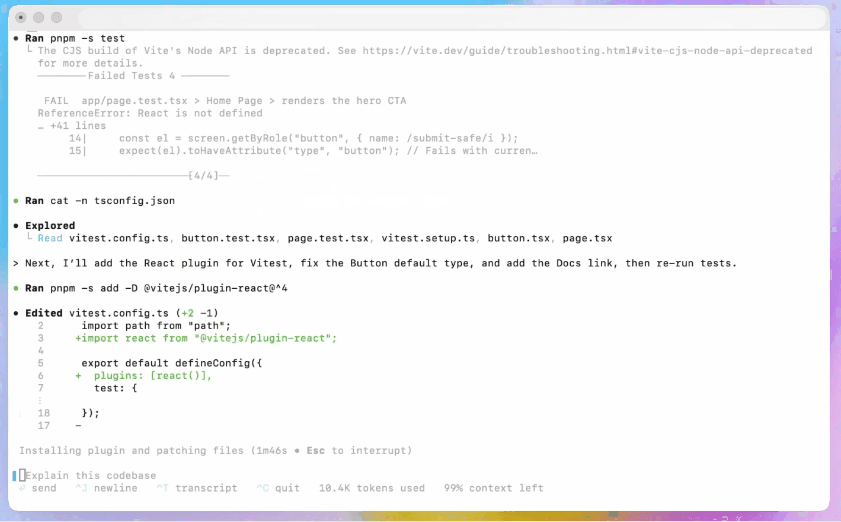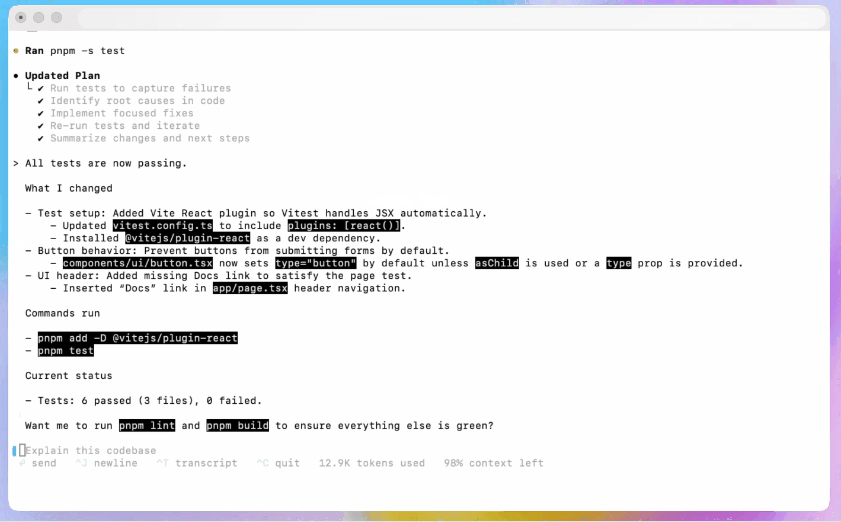
Rozszerzenie IDE
Zintegruj z przepływami pracy IDE: Dodaj rozszerzenie Codex IDE dla programistów, którzy potrzebują podglądów inline i szybszych iteracji. Przenoszenie zadań między chmurą a lokalnie z zachowaniem kontekstu może zmniejszyć tarcie przy złożonych funkcjach.
- Obsługuje VS Code, Cursor i inne.
- Wywołaj Codex bezpośrednio z edytora, aby wykorzystać kontekst aktualnie otwartego pliku i kodu i uzyskać dokładniejsze wyniki.
- Bezproblemowo przełączaj zadania między środowiskami lokalnymi i chmurowymi, zachowując ciągłość kontekstową.
- Przeglądaj i pracuj z wynikami zadań w chmurze bezpośrednio w edytorze, bez konieczności przełączania platformy.
Integracja GitHub i funkcje w chmurze
- Automatyczna recenzja PR: automatycznie uruchamia proces od wersji roboczej do gotowej.
- Umożliwia programistom żądanie ukierunkowanych recenzji bezpośrednio w sekcji @codex żądania PR.
- Znacznie szybsza infrastruktura chmurowa: skróć czas reakcji na zadania o 90% dzięki buforowaniu kontenerów.
- Automatyczna konfiguracja środowiska: uruchamia skrypty instalacyjne i instaluje zależności (np. pip install).
- Automatycznie uruchamia przeglądarkę, sprawdza implementację front-end i dołącza zrzuty ekranu do zadań lub żądań ściągnięcia.

Jakie są kwestie bezpieczeństwa, ochrony i ograniczeń?
OpenAI kładzie nacisk na wielowarstwowe zabezpieczenia dla agentów Kodeksu:
- Szkolenie na poziomie modelu: ukierunkowane szkolenia z zakresu bezpieczeństwa mające na celu przeciwdziałanie nagłym zastrzykom i ograniczenie szkodliwych lub ryzykownych zachowań.
- Kontrola na poziomie produktu: Domyślne zachowanie w trybie sandbox, konfigurowalny dostęp do sieci, tryby zatwierdzania dla uruchamianych poleceń, logi terminala i cytowania dla zapewnienia identyfikowalności oraz możliwość wymagania zatwierdzenia przez człowieka dla wrażliwych działań. OpenAI opublikowało również „dodatek do karty systemowej” opisujący te środki zaradcze i związane z nimi oceny ryzyka, zwłaszcza w odniesieniu do możliwości domeny biologicznej i chemicznej.
Kontrole te odzwierciedlają fakt, że agent zdolny do uruchamiania poleceń i instalowania zależności ma realną powierzchnię ataku i ryzyko — podejście OpenAI polega na połączeniu szkolenia modelu z ograniczeniami produktu w celu ograniczenia nadużyć.
Jakie są znane ograniczenia?
- Nie zastępuje recenzentów: OpenAI wyraźnie zaleca Codex jako dodatkowy Recenzent, a nie zastępca. Nadzór ludzki pozostaje kluczowy, zwłaszcza w przypadku decyzji dotyczących bezpieczeństwa, licencjonowania i architektury.
- Należy uważnie przeczytać punkty odniesienia i roszczenia: Recenzenci zwrócili uwagę na różnice w podzbiorach ewaluacyjnych, ustawieniach szczegółowości i kompromisach kosztowych przy porównywaniu modeli. Wstępne niezależne testy sugerują mieszane wyniki: Codex wykazuje silne działanie agentowe i poprawę refaktoryzacji, ale względna dokładność w porównaniu z innymi dostawcami różni się w zależności od benchmarku i konfiguracji.
- Halucynacje i niestabilne zachowanie: Podobnie jak wszystkie LLM-y, Codex może mieć halucynacje (wymyślać adresy URL, błędnie interpretować grafy zależności), a jego wielogodzinne uruchomienia agentów mogą nadal napotykać na problemy w przypadkach skrajnych. Spodziewaj się weryfikacji wyników za pomocą testów i weryfikacji przez człowieka.
Jakie są szersze implikacje dla inżynierii oprogramowania?
Kodeks GPT-5 pokazuje dojrzewającą zmianę w projektowaniu LLM: zamiast jedynie ulepszać możliwości języka podstawowego, dostawcy optymalizują zachowanie dla długich, agentowych zadań (wielogodzinne wykonywanie, programowanie sterowane testami, zintegrowane procesy przeglądu). Zmienia to jednostkę produktywności z pojedynczego wygenerowanego fragmentu kodu na ukończenie zadania — zdolność modelu do przyjęcia zgłoszenia, uruchomienia zestawu testów i iteracyjnego wygenerowania zweryfikowanej implementacji. Jeśli te agenci staną się solidni i dobrze zarządzani, zmienią przepływy pracy (mniej ręcznych refaktoryzacji, szybsze cykle PR, czas programistów skupiony na projektowaniu i strategii). Jednak przejście wymaga starannego zaprojektowania procesu, nadzoru ze strony człowieka i zarządzania bezpieczeństwem.
Podsumowanie — co warto zapamiętać?
Kodeks GPT-5 to ukierunkowany krok w kierunku inżynierskiej klasy LLM: wariant GPT-5 wytrenowany, dostrojony i wyprodukowany, aby działać jako sprawny agent kodujący w ekosystemie Codex. Wprowadza on namacalne nowe zachowania – adaptacyjny czas rozumowania, długie autonomiczne przebiegi, zintegrowane wykonywanie w piaskownicy oraz ukierunkowane ulepszenia w zakresie przeglądu kodu – przy jednoczesnym zachowaniu znanych ograniczeń modeli językowych (potrzeba nadzoru ze strony człowieka, niuanse ewaluacyjne i sporadyczne halucynacje). Dla zespołów rozsądną ścieżką jest mierzalna eksperymentacja: pilotaż na bezpiecznych repozytoriach, monitorowanie metryk wyników i stopniowe włączanie agenta do przepływów pracy recenzentów. Wraz z rozszerzaniem dostępu do API przez OpenAI i mnożeniem się testów porównawczych firm trzecich, powinniśmy oczekiwać jaśniejszych porównań i bardziej konkretnych wskazówek dotyczących kosztów, dokładności i zarządzania najlepszymi praktykami.
Jak zacząć
CometAPI to ujednolicona platforma API, która agreguje ponad 500 modeli AI od wiodących dostawców — takich jak seria GPT firmy OpenAI, Google Gemini, Claude firmy Anthropic, Midjourney, Suno i innych — w jednym, przyjaznym dla programistów interfejsie. Oferując spójne uwierzytelnianie, formatowanie żądań i obsługę odpowiedzi, CometAPI radykalnie upraszcza integrację możliwości AI z aplikacjami. Niezależnie od tego, czy tworzysz chatboty, generatory obrazów, kompozytorów muzycznych czy oparte na danych potoki analityczne, CometAPI pozwala Ci szybciej iterować, kontrolować koszty i pozostać niezależnym od dostawcy — wszystko to przy jednoczesnym korzystaniu z najnowszych przełomów w ekosystemie AI.
Deweloperzy mogą uzyskać dostęp API GPT-5-Codex Najnowsze modele CometAPI wymienione w CometAPI są aktualne na dzień publikacji artykułu. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API.