

17 czerwca 2025 r. szanghajski lider AI MiniMax (znany również jako Xiyu Technology) oficjalnie wydał MiniMax-M1 (dalej „M1”) — pierwszy na świecie otwarty, wielkoskalowy, hybrydowy model rozumowania uwagi. Łącząc architekturę Mixture-of-Experts (MoE) z innowacyjnym mechanizmem Lightning Attention, M1 osiąga wiodącą w branży wydajność w zadaniach zorientowanych na produktywność, rywalizując z najlepszymi systemami o zamkniętym kodzie źródłowym, zachowując przy tym niezrównaną opłacalność. W tym dogłębnym artykule badamy, czym jest M1, jak działa, jakie ma cechy definiujące oraz praktyczne wskazówki dotyczące uzyskiwania dostępu do modelu i korzystania z niego.
Czym jest MiniMax-M1?
MiniMax-M1 stanowi ukoronowanie badań MiniMaxAI nad skalowalnymi, wydajnymi mechanizmami uwagi. Opierając się na fundamencie MiniMax-Text-01, iteracja M1 integruje błyskawiczną uwagę z ramą MoE, aby osiągnąć bezprecedensową wydajność zarówno podczas treningu, jak i wnioskowania. Ta kombinacja umożliwia modelowi utrzymanie wysokiej wydajności nawet podczas przetwarzania ekstremalnie długich sekwencji — kluczowego wymogu w przypadku zadań obejmujących rozległe bazy kodów, dokumenty prawne lub literaturę naukową.
Podstawowa architektura i parametryzacja
W swojej istocie MiniMax-M1 wykorzystuje hybrydowy system MoE, który dynamicznie kieruje tokeny przez podzbiór eksperckich podsieci. Podczas gdy model obejmuje łącznie 456 miliardów parametrów, tylko 45.9 miliarda jest aktywowanych dla każdego tokena, co optymalizuje wykorzystanie zasobów. Ten projekt czerpie inspirację z wcześniejszych implementacji MoE, ale udoskonala logikę routingu, aby zminimalizować narzut komunikacyjny między procesorami graficznymi podczas rozproszonego wnioskowania.
Błyskawiczna uwaga i wsparcie długoterminowe
Cechą charakterystyczną MiniMax-M1 jest jego mechanizm błyskawicznej uwagi, który drastycznie zmniejsza obciążenie obliczeniowe samouwagi dla długich sekwencji. Poprzez aproksymację macierzy uwagi poprzez kombinację jąder lokalnych i globalnych, model ten zmniejsza liczbę operacji FLOP nawet o 75% w porównaniu do tradycyjnych transformatorów podczas przetwarzania sekwencji 100 tys. tokenów. Ta wydajność nie tylko przyspiesza wnioskowanie, ale także otwiera drzwi do obsługi okien kontekstowych do miliona tokenów bez zaporowych wymagań sprzętowych.
W jaki sposób MiniMax-M1 osiąga wydajność obliczeniową?
Wzrost wydajności MiniMax-M1 wynika z dwóch głównych innowacji: hybrydowej architektury Mixture-of-Experts i nowatorskiego algorytmu uczenia się przez wzmacnianie CISPO używanego podczas treningu. Razem te elementy zmniejszają zarówno czas treningu, jak i koszt wnioskowania, umożliwiając szybkie eksperymentowanie i wdrażanie.
Trasowanie hybrydowe mieszane ekspertów
Komponent MoE wykorzystuje 32 eksperckie podsieci, z których każda specjalizuje się w różnych aspektach rozumowania lub zadaniach specyficznych dla domeny. Podczas wnioskowania wyuczony mechanizm bramkowania dynamicznie wybiera najbardziej odpowiednich ekspertów dla każdego tokena, aktywując tylko te podsieci, które są potrzebne do przetworzenia danych wejściowych. Ta selektywna aktywacja eliminuje zbędne obliczenia i zmniejsza zapotrzebowanie na przepustowość pamięci, zapewniając MiniMax-M1 znaczną przewagę w zakresie efektywności kosztowej nad monolitycznymi modelami transformatorów.
CISPO: Nowy algorytm uczenia się przez wzmacnianie
Aby jeszcze bardziej zwiększyć wydajność treningu, MiniMaxAI opracował CISPO (Clipped Importance Sampling with Partial Overrides), algorytm RL, który zastępuje aktualizacje wag na poziomie tokena przycinaniem opartym na próbkowaniu ważności. CISPO łagodzi problemy z eksplozją wag, powszechne w konfiguracjach RL na dużą skalę, przyspiesza konwergencję i zapewnia stabilną poprawę polityki w różnych testach porównawczych. W rezultacie pełne szkolenie RL MiniMax-M1 na 512 procesorach graficznych H800 trwa zaledwie trzy tygodnie, kosztując około 534,700 4 USD — ułamek kosztów zgłoszonych dla porównywalnych przebiegów szkoleniowych GPT-XNUMX.
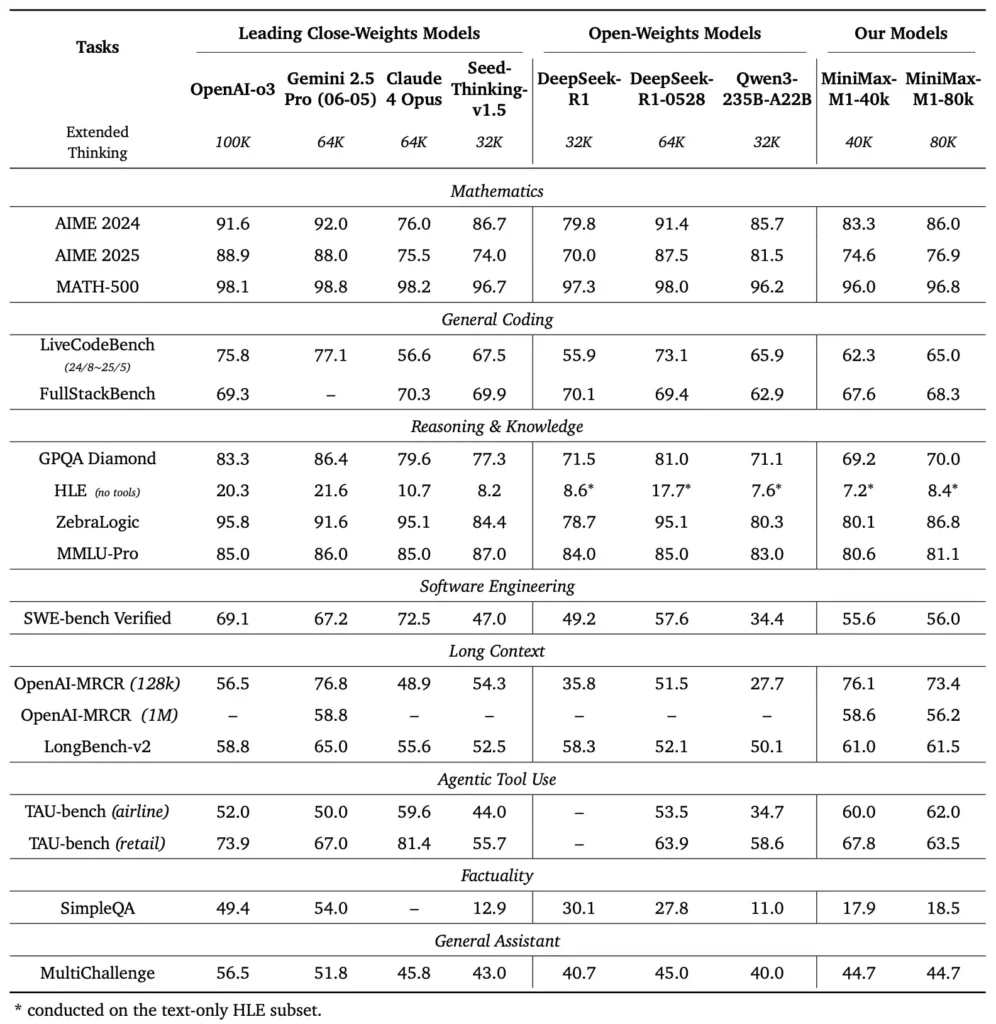
Jakie są parametry wydajnościowe MiniMax-M1?
MiniMax-M1 wyróżnia się w szeregu standardowych i specjalistycznych testów porównawczych, wykazując się doskonałą sprawnością w rozumowaniu długokontekstowym, rozwiązywaniu problemów matematycznych i generowaniu kodu.
Zadania wymagające rozumowania w długim kontekście
W obszernych testach zrozumienia dokumentów MiniMax-M1 przetwarza okna kontekstowe do 1,000,000 1 100 tokenów, przewyższając DeepSeek-RXNUMX o współczynnik ośmiokrotności w maksymalnej długości kontekstu i zmniejszając o połowę wymagania obliczeniowe dla sekwencji XNUMX tys. tokenów. W testach porównawczych, takich jak rozszerzona ocena kontekstu NarrativeQA, model osiąga najnowocześniejsze wyniki zrozumienia, co przypisuje się jego zdolności błyskawicznej uwagi do wydajnego wychwytywania zarówno lokalnych, jak i globalnych zależności.
Inżynieria oprogramowania i wykorzystanie narzędzi
MiniMax-M1 został specjalnie przeszkolony w środowiskach inżynierii oprogramowania typu sandbox przy użyciu RL na dużą skalę, co pozwoliło mu generować i debugować kod z niezwykłą dokładnością. W testach kodowania, takich jak HumanEval i MBPP, model osiąga wskaźniki zaliczeń porównywalne lub przewyższające Qwen3-235B i DeepSeek-R1, szczególnie w bazach kodu składających się z wielu plików i zadaniach wymagających wzajemnego odwoływania się do długich segmentów kodu. Ponadto wczesne demonstracje MiniMaxAI pokazują zdolność modelu do integracji z narzędziami programistycznymi, od generowania potoków CI/CD po przepływy pracy z automatyczną dokumentacją.
W jaki sposób programiści mogą uzyskać dostęp do MiniMax-M1?
Aby wspierać powszechną adopcję, MiniMaxAI udostępniło MiniMax-M1 bezpłatnie jako model o otwartej wadze. Deweloperzy mogą uzyskać dostęp do wstępnie wyszkolonych punktów kontrolnych, wag modeli i kodu wnioskowania za pośrednictwem oficjalnego repozytorium GitHub.
Wersja Open-weight na GitHub
MiniMaxAI opublikowało pliki modelu MiniMax-M1 i towarzyszące im skrypty na podstawie licencji open-source na GitHub. Zainteresowani użytkownicy mogą sklonować repozytorium na https://github.com/MiniMax-AI/MiniMax-M1, które hostuje punkty kontrolne dla wariantów budżetu tokenów 40K i 80K, a także przykłady integracji dla typowych struktur ML, takich jak PyTorch i TensorFlow.
Punkty końcowe API i integracja z chmurą
Oprócz lokalnego wdrożenia, MiniMaxAI nawiązał współpracę z głównymi dostawcami usług w chmurze, aby oferować zarządzane usługi API. Dzięki tym partnerstwom programiści mogą wywoływać MiniMax-M1 za pośrednictwem punktów końcowych RESTful, z zestawami SDK dostępnymi dla Pythona, JavaScript i Java. Interfejsy API obejmują konfigurowalne parametry dotyczące długości kontekstu, progi trasowania ekspertów i budżety tokenów, co pozwala użytkownikom dostosowywać wydajność do ich przypadków użycia, monitorując jednocześnie zużycie mocy obliczeniowej w czasie rzeczywistym.
Jak zintegrować i wykorzystać MiniMax-M1 w rzeczywistych zastosowaniach?
Aby w pełni wykorzystać możliwości narzędzia MiniMax-M1, konieczne jest zrozumienie wzorców interfejsu API, najlepszych praktyk dotyczących monitów kontekstowych i strategii orkiestracji narzędzi.
Przykład podstawowego użycia API
Typowe wywołanie API obejmuje wysłanie ładunku JSON zawierającego tekst wejściowy i opcjonalne nadpisania konfiguracji. Na przykład:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
Odpowiedź zwraca ustrukturyzowany plik JSON z wygenerowanym tekstem, statystykami wykorzystania tokenów i dziennikami routingu, co umożliwia szczegółowe monitorowanie aktywacji ekspertów.
Użycie narzędzi i agent MiniMax
Oprócz podstawowego modelu, MiniMaxAI wprowadził MiniMax Agent, beta framework agenta, który może wywoływać zewnętrzne narzędzia — od środowisk wykonywania kodu po web scrapery — pod maską. Deweloperzy mogą tworzyć instancje sesji agenta, które łączą rozumowanie modelu z wywołaniem narzędzia, na przykład w celu pobierania danych w czasie rzeczywistym, wykonywania obliczeń lub aktualizowania baz danych. Ten paradygmat agenta upraszcza kompleksowe opracowywanie aplikacji, umożliwiając MiniMax-M1 działanie jako koordynator w złożonych przepływach pracy.
Najlepsze praktyki i pułapki
- Szybka inżynieria dla długich kontekstów: Podziel dane wejściowe na spójne segmenty, osadzaj podsumowania w logicznych odstępach czasu i wykorzystuj strategie „podsumuj, a następnie uzasadnij”, aby utrzymać koncentrację modelu.
- Kompromisy między mocą obliczeniową a wydajnością: Eksperymentuj z niższymi progami eksperckimi lub ograniczonymi budżetami na myślenie (np. wariant 40K) w przypadku aplikacji wrażliwych na opóźnienia.
- Monitorowanie i zarządzanie:Wykorzystuj dzienniki trasowania i statystyki tokenów do audytu wykorzystania ekspertów i zapewnienia zgodności z budżetami kosztów, zwłaszcza w środowiskach produkcyjnych.
Stosując się do tych wytycznych, deweloperzy mogą wykorzystać mocne strony systemu MiniMax-M1 — szerokie możliwości obsługi kontekstu i efektywne wnioskowanie — ograniczając jednocześnie ryzyko związane z wdrażaniem modeli na dużą skalę.
Jak używać MiniMax-M1?
Po zainstalowaniu M1 można go wywołać za pomocą prostych skryptów Python lub interaktywnych notatników.
Jak wygląda podstawowy skrypt wnioskowania?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
W tym przykładzie przywołujemy wariant budżetu 40 tys., zamieniając go na "MiniMax-AI/MiniMax-M1-80k" odblokowuje pełny budżet rozumowania wynoszący 80 tys. ().
Jak sobie radzisz z bardzo długimi kontekstami?
W przypadku danych wejściowych przekraczających typowe rozmiary bufora, M1 obsługuje strumieniową tokenizację. Użyj stream=True flaga w tokenizerze umożliwiająca przesyłanie tokenów w blokach i wykorzystanie wnioskowania na podstawie punktu kontrolnego i ponownego uruchomienia w celu utrzymania wydajności w przypadku sekwencji składających się z miliona tokenów.
Jak można dostroić lub dostosować M1?
Podczas gdy podstawowe punkty kontrolne są wystarczające dla większości zadań, badacze mogą zastosować dostrajanie RL przy użyciu kodu CISPO zawartego w repozytorium. Poprzez dostarczanie niestandardowych funkcji nagradzania — od poprawności kodu po wierność semantyczną — praktycy mogą dostosować M1 do przepływów pracy specyficznych dla domeny.
Podsumowanie
MiniMax-M1 wyróżnia się jako przełomowy model AI, przesuwający granice rozumienia i rozumowania języka w długim kontekście. Dzięki hybrydowej architekturze MoE, mechanizmowi Lightning Attention i programowi szkoleniowemu wspieranemu przez CISPO, model ten zapewnia wysoką wydajność w zadaniach od analizy prawnej po inżynierię oprogramowania, a jednocześnie drastycznie zmniejsza koszty obliczeniowe. Dzięki otwartej wersji i ofercie API w chmurze, MiniMax-M1 jest dostępny dla szerokiego spektrum programistów i organizacji pragnących tworzyć aplikacje nowej generacji oparte na AI. W miarę jak społeczność AI nadal bada potencjał modeli dużego kontekstu, innowacje MiniMax-M1 są gotowe wpłynąć na przyszłe badania i rozwój produktów w całej branży.
Jak zacząć
CometAPI zapewnia ujednolicony interfejs REST, który agreguje setki modeli AI — w tym rodzinę ChatGPT — w ramach spójnego punktu końcowego, z wbudowanym zarządzaniem kluczami API, limitami wykorzystania i panelami rozliczeniowymi. Zamiast żonglować wieloma adresami URL dostawców i poświadczeniami.
Na początek zapoznaj się z możliwościami modeli w Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API.
Najnowsza integracja MiniMax‑M1 API wkrótce pojawi się w CometAPI, więc bądźcie czujni! Podczas gdy finalizujemy przesyłanie modelu MiniMax‑M1, zapoznaj się z naszymi innymi modelami na Strona modeli lub wypróbuj je w Plac zabaw AINajnowszy model MiniMax w CometAPI to Minimax ABAB7-Podgląd API oraz Interfejs API MiniMax Video-01 ,odnieś się do:
