

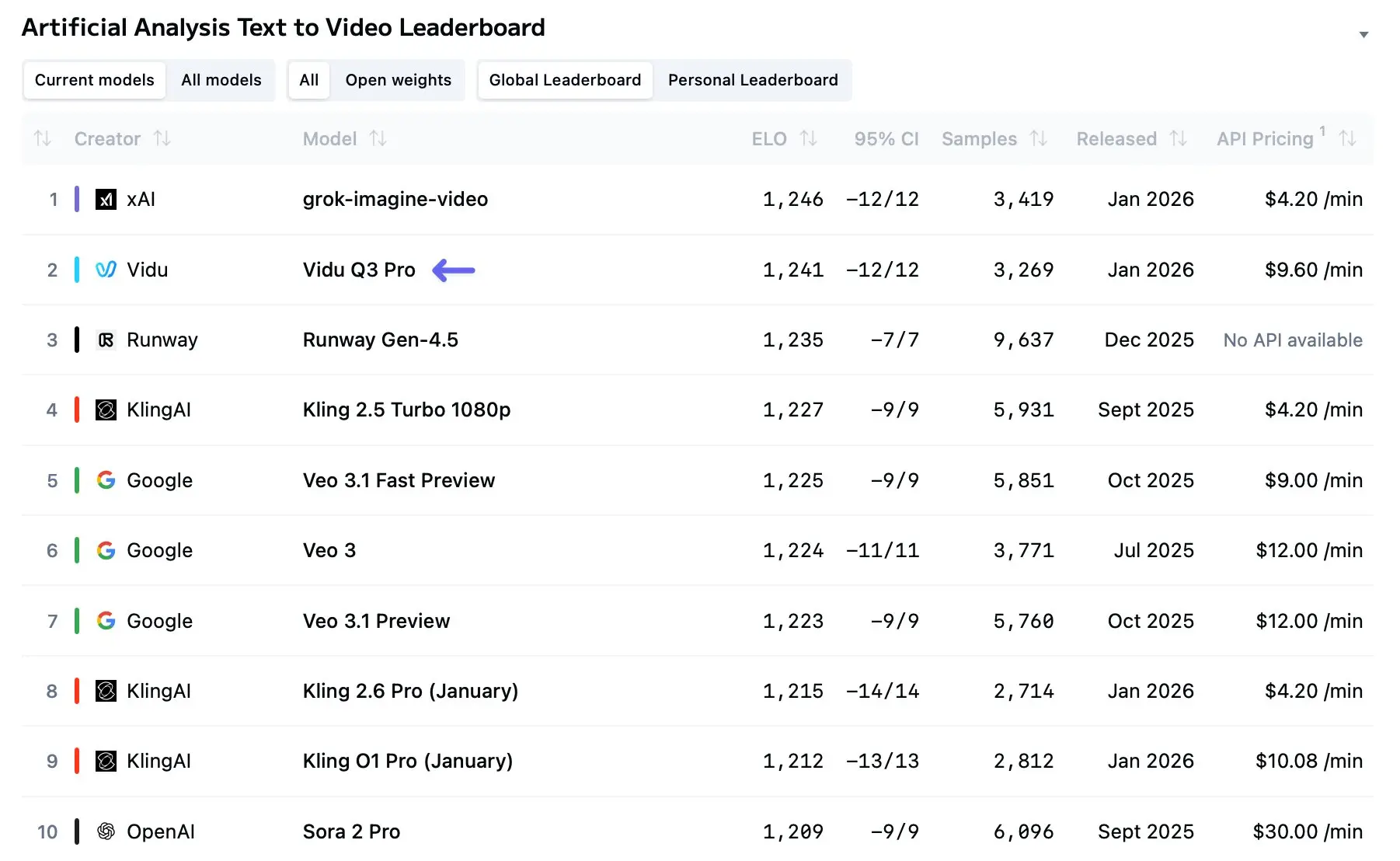
Vidu Q3 pojawił się na scenie na początku 2026 roku jako jeden z najczytelniejszych sygnałów, że generowanie wideo przez AI przechodzi od krótkich, nowinkowych klipów do prawdziwie narracyjnego, wieloujęciowego opowiadania historii. W miesiącach od szerokiego udostępnienia Vidu Q3 stał się stałym elementem workflowów twórców, pilotaży badawczych i komercyjnych — i to z dobrego powodu: przesuwa granice czasu trwania, integracji audiowizualnej i spójności wieloujęciowej dalej niż większość wcześniejszych modeli, oferując jednocześnie API dla deweloperów do użycia programistycznego.
Czym jest Vidu Q3?
Vidu Q3 to najnowsza flagowa iteracja architektury dużego modelu wideo (LVM) firmy ShengShu Technology. W przeciwieństwie do poprzedników (Vidu 1.0 i 1.5), które wymagały oddzielnych workflowów dla generowania obrazu i postprodukcji dźwięku, Vidu Q3 jest „all-in-one” silnikiem generatywnym.
Kluczowym przełomem Vidu Q3 jest zdolność do jednoczesnego generowania obrazów w wysokiej rozdzielczości i dźwięku o wysokiej wierności.[ Poprzez wspólne rozumienie fizyki dźwięku i światła, model eliminuje „dolinę niesamowitości” zdesynchronizowanego audio, często widoczną w modelach konkurencji. Wspiera do 16 sekund ciągłego generowania w natywnej rozdzielczości 1080p, co pozycjonuje go jako narzędzie gotowe do produkcji krótkometrażowych filmów, reklam i narracyjnego opowiadania. ]
Jak Vidu Q3 działa od środka?
Choć szczegóły architektury są zastrzeżone, Vidu bazuje na U-ViT fusion of diffusion models and transformers — projekcie znanym z równoważenia spójności, ciągłości czasowej i ekspresyjności w generowaniu wideo.
Ta hybrydowa architektura pozwala modelowi rozumować o ruchu, dźwięku i kontekście narracji na dłuższych sekwencjach.
6 wyróżniających się funkcji Vidu Q3
1. Generowanie o wydłużonym czasie — jak długo może trwać?
Jedną z najważniejszych cech Vidu Q3 jest dłuższy czas pojedynczego generowania. Wiele wcześniejszych modeli skupiało się na mikroklipach; Q3 celowo wydłuża długość, aby umożliwić proste łuki fabularne i sekwencje z wieloma ujęciami bez zmuszania twórców do sklejania wielu malutkich klipów. Dokumentacja platformy i portale partnerskie reklamują do ~16 sekund natywnego generowania w jednym przebiegu (format i opcje jakości mogą się różnić w zależności od dostawcy i planu API). Ma to znaczenie, ponieważ przejście z 4–8 sekund do 16 sekund zmienia sposób, w jaki twórcy planują sceny, piszą beaty i rytmizują sygnały audio.
2. Wierność wizualna i spójność czasowa
Niezależne ewaluacje i wczesne benchmarki pokazują, że Vidu Q3 generuje wyraźniejsze obrazy i mniej zniekształceń na poziomie klatek niż wcześniejsze modele konsumenckie. Usprawnienia w architekturze i augmentacji danych zdają się redukować migotanie i poprawiać ciągłość ruchu dla klipów poniżej 10–16 sekund. Jednak model nadal może mieć trudności z gęstymi scenami wielopodmiotowymi (tłumy, skomplikowane interakcje fizyczne), gdzie okluzja i drobne ruchy wymagają silnego rozumowania fizycznego. Serwisy porównawcze i leaderboardy modeli umieściły już Vidu Q3 wysoko na listach T2V (tekst-do-wideo), choć rankingi różnią się w zależności od benchmarku i zbioru danych.
3. Natywne generowanie audio + wideo
W przeciwieństwie do systemów, które generują nieme obrazy i pozostawiają dźwięk do postprodukcji, Vidu Q3 integruje generowanie audio w obrębie modelu. Efektem są dialogi zsynchronizowane z ruchem ust, odmierzane w czasie SFX oraz opcjonalna muzyka w tle generowana wraz z klatkami. Integracja dźwięku na poziomie modelu redukuje błędy dopasowania (dryf lip-sync, nietrafione wskazówki rytmiczne) i skraca pętlę produkcyjną dla dem, podglądów i wielu krótkich formatów finalnych.
4. Inteligentna kontrola kamery i narracje wieloujęciowe
Funkcje „smart camera” w Q3 interpretują prompt’y dotyczące ruchów kamery (panoramy, jazdy, śledzenie) oraz sekwencji z wieloma ujęciami. Zamiast generować pojedynczy statyczny punkt widzenia, model potrafi tworzyć zaplanowane cięcia i przejścia, dzięki czemu wynikowy klip czyta się jak wyreżyserowana scena. Dla twórców zmienia to output z „pojedynczego skomponowanego obrazu, który się porusza” w „krótką scenę z wieloma ujęciami”. Zwiększa to oglądalność i umożliwia bogatsze opowiadanie wizualne w jednym generowaniu.
5. Spójność wieloreferencyjna i wierność postaci
Vidu (jako platforma) zainwestowało w systemy „reference to video” i spójności wieloreferencyjnej, które pozwalają twórcom przesłać kilka obrazów referencyjnych, by zablokować tożsamość postaci w kolejnych klatkach. Q3 rozwija te pomysły, utrzymując wygląd postaci i rekwizyty spójne w wielu kątach kamery i cięciach — podstawowy, lecz kluczowy warunek spójnego efektu narracyjnego. Jest to szczególnie przydatne w anime lub projektach stylizowanych, gdzie utrzymanie spójnej kreski postaci ma kluczowe znaczenie.
6. Gotowość dla deweloperów: API i workflow
Zestaw modeli Vidu — w tym Q3 — jest dostępny przez webowe interfejsy użytkownika oraz programistyczne REST API. Deweloperzy mogą przesyłać zadania tekst-do-wideo lub obraz-plus-tekst do punktu końcowego inferencji, otrzymać ID zadania i odpytywać o wyniki (typowy wzorzec zadania asynchronicznego). API oferuje parametry takie jak rozdzielczość, proporcje obrazu, czas trwania, amplituda ruchu i przełącznik generowania audio. Dzięki temu Q3 jest dostępny dla automatyzacji, wsadowych workflowów i integracji z redakcyjnymi pipeline’ami.
Jak Vidu Q3 wypada w porównaniu z Sora 2 i Veo 3.1?
Krótka odpowiedź: Vidu Q3 mocno konkuruje w dłuższych wyjściach narracyjnych i zintegrowanym audio/wideo dla scen 10–20 s, Sora 2 wyróżnia się fizycznie wiarygodnym realizmem w pojedynczych ujęciach i integracją społeczną, a Veo 3.1 prowadzi w dopracowaniu na poziomie pikseli, narzędziach ciągłości wieloklatkowej oraz integracji API klasy enterprise. Poniżej rozwijamy różnice w praktycznych osiach.
Który model jest mocniejszy w realizmie i fizyce: Sora 2 czy Vidu Q3?
Sora 2 (OpenAI) była explicite trenowana pod kątem fizycznej wiarygodności i symulacji świata — jej publiczne notatki podkreślają zaawansowane zachowania fizyczne, dokładne interakcje obiektów oraz bardzo realistyczne trajektorie ruchu. Sora 2 dostarcza również zsynchronizowane audio i integracje z aplikacjami społecznymi (w tym cameos i aplikacją mobilną), co czyni ją wyjątkowo silną w realistycznych, fizycznie spójnych scenach. Jeśli Twoje zlecenie wymaga dokładnych kolizji, realistycznej dynamiki lub fotorealistycznego ruchu ludzi w krótkich, samodzielnych ujęciach, Sora 2 często będzie lepszym wyborem.
Vidu Q3 z kolei pozycjonowana jest bardziej jako silnik opowiadania historii: dłuższe klipy, sekwencje z wieloma ujęciami i reżyserska kontrola kamery. Nie oznacza to, że Vidu rezygnuje z realizmu, ale jej główne atuty to ciągłość narracyjna i połączone wyjście audiowizualne, a nie surowa symulacja fizyki. Do kinowego krótkiego storytellingu (np. 16 s demo produktu z cięciami i VO) workflow Q3 bywa szybszy i prostszy.
Który model lepszy pod względem filmowego szlifu i wysokiej wierności: Veo 3.1 vs Vidu Q3?
Veo 3.1 (Google / DeepMind / Gemini) jest promowane jako opcja o wysokiej wierności, klasy enterprise, ze silnymi narzędziami ciągłości, natywnym generowaniem audio i wsparciem w chmurze Google/Vertex/Gemini. Veo 3.1 wprowadziło zaawansowane funkcje „ingredients to video”, natywne wsparcie pionowego formatu (9:16) oraz upscalowanie do wysokich rozdzielczości (w tym 4K w niektórych przepływach). W projektach wymagających najwyższej jakości pikseli, precyzyjnej harmonii kolorów i dopracowanych API korporacyjnych Veo 3.1 często jest pierwszym wyborem.
Vidu Q3 broni się, koncentrując na wydłużonym czasie trwania + spójności opowieści z wieloma ujęciami oraz produktyzacji zorientowanej na twórców (szybkie webowe playgroundy, orkiestracja wieloreferencyjna). Jeśli priorytetem jest stworzenie krótkiej, reżyserowanej sceny z wieloma ruchami kamery i zintegrowanymi wskazówkami audio (a długość cenisz wyżej niż surowy szlif pikseli), Vidu Q3 jest przekonujące. W kwestii surowej fotorealistycznej wierności Veo 3.1 zwykle ma przewagę.
Na początku 2026 roku triumwirat wideo AI tworzą Sora 2 od OpenAI, Veo 3.1 od Google oraz Vidu Q3. Oto jak wypadają w bezpośrednim porównaniu:
| Feature | Vidu Q3 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| Max Single Clip Duration | ~16 s | Do ~25 s (Pro) | 8 s (z funkcjami zszywania narracji) |
| Native Audio Generation | Tak (zintegrowane) | Tak (eksperymentalne) | Tak (zaawansowane) |
| Cinematic Camera Control | Tak (świadomość ujęć) | Ograniczone presety | Tak (spójność wieloujęciowa) |
| Multi-shot Narrative | Tak | Tak | Tak |
| Text Rendering in Frames | Tak | Różnie | Różnie |
| Resolution | 1080p | 1080p | 1080p / 4K w specjalnych przypadkach |
| Primary Use Case | Narracyjne opowiadanie, animacja | Wysokobudżetowe concept/film | Youtube Shorts / TikTok |
Analiza:
- Vs. Sora 2: Sora 2 pozostaje ciężką wagą w zakresie czystej wierności wizualnej i surrealistycznej wyobraźni („jakość Hollywood”). Jednak Vidu Q3 przeważa pod względem efektywności workflowu dzięki limitowi 16 sekund i lepszej integracji audio. Dla twórców, którzy potrzebują klipu „zrobionego w jednym”, Q3 jest szybsze.
- Vs. Veo 3.1: Veo 3.1 od Google wyróżnia się szybkością w krótkich, formatowo zoptymalizowanych klipach (4–8 s) i głęboką integracją z YouTube. Vidu Q3 celuje wyżej w łańcuchu wartości, kierując ofertę do profesjonalnych animatorów i filmowców, którzy potrzebują dłuższych, ciągłych ujęć, jakie Veo ma trudność utrzymać konsekwentnie.
Jakie praktyczne zastosowania umożliwia Vidu Q3?
Reklama i marketing krótkich form
Marki mogą znacznie szybciej prototypować koncepcje reklam end-to-end: napisać skrypt, wygenerować 16‑sekundowy materiał wizualny z zsynchronizowanym VO i SFX, iterować nad słowami i kompozycją ujęć oraz przygotować wielojęzyczne wersje przez promptowanie wariantów językowych. W testach A/B kreacji społecznościowych skrócony czas realizacji to wyraźna korzyść biznesowa. Case studies publikowane przez platformy pokazują marketerów wykorzystujących Vidu Q3 do mikroreklam i teaserów produktów.
Storyboard i prewizualizacja dla filmu i TV
Reżyserzy i montażyści używają krótkich klipów AI jako prewizualizacji (previz) do blokowania scen, testowania ruchów kamery i pitchowania treatmentów. Sekwencje wieloujęciowe i inteligentna kontrola kamery Vidu Q3 są tu szczególnie przydatne: zespoły kreatywne mogą iterować nad ustawieniami i dialogiem bez kosztów zdjęć w plenerze. Choć AI previz nie zastępuje reżyserii na planie, skraca cykle podejmowania decyzji na wczesnym etapie.
E-learning i wideo wyjaśniające
Działy edukacyjne i korporacyjne mogą generować zwięzłe animowane segmenty wyjaśniające z zsynchronizowaną narracją i adnotowanymi SFX. W przypadku treści standaryzowanych (szkolenie produktowe, onboarding) redukuje to zależność od kosztownych domów produkcyjnych i przyspiesza lokalizację. Szybkość publikacji i natywne możliwości audio czynią Vidu Q3 atrakcyjnym dla tych zastosowań.
Gry, concept art i produkcja indie
Twórcy indie i zespoły growe wykorzystują krótkie kinowe klipy AI do trailerów, makiet dialogów NPC lub eksploracji stylu. Wsparcie obrazów referencyjnych i spójność postaci w Vidu Q3 pomaga utrzymać spójność wizualnej tożsamości IP gry w prototypowych trailerach. Model jest też stosowany w materiałach do pitchu, aby pozyskać finansowanie lub zainteresowanie wydawców.
Dostępność i szybka lokalizacja
Ponieważ audio jest generowane natywnie, Vidu Q3 upraszcza wersje wielojęzyczne: wygeneruj to samo ujęcie z różnymi promptami językowymi lub poproś o zróżnicowane barwy głosu. Umożliwia to szybką lokalizację treści marketingowych lub szkoleniowych przy zachowaniu przybliżeń lip-sync wystarczająco dobrych dla wielu krótkich formatów (choć dopasowanie ust najwyższej klasy dla emisji może nadal wymagać korekty przez człowieka).
Czy Vidu Q3 jest najlepszym modelem wideo AI w 2026 roku?
Ogłaszanie jednego „najlepszego” modelu pomija niuanse: zwycięzca zależy od zastosowania.
- W przypadku fotorealistycznej, fizycznie ugruntowanej produkcji i konserwatywnego podejścia do bezpieczeństwa Sora 2 od OpenAI często jest postrzegana jako najlepszy wybór. Kładzie nacisk na realizm i solidną moderację, co czyni ją atrakcyjną dla produkcji high‑end i ostrożnych przedsiębiorstw.
- Dla zintegrowanych z platformami, formatowo zoptymalizowanych treści krótkich natywne pionowe wyjścia Veo 3.1 i integracje aplikacji Google (YouTube Shorts, Google Photos) czynią je wyjątkowo wygodnym.
- Do szybkiego prototypowania audio‑wideo, kontroli narracji wieloujęciowej i zrównoważonego zestawu funkcji storytellingsowych Vidu Q3 wyróżnia się — zwłaszcza gdy liczy się szybkość iteracji i zintegrowane audio bardziej niż absolutny fotorealizm. Wczesne benchmarki i raporty dostawców plasują Vidu Q3 wysoko w rankingach T2V, a jego funkcje czynią go praktycznym wyborem dla marketerów, niezależnych twórców i studiów prototypujących nowe pomysły.
Ograniczenia i uwagi?
Choć Vidu Q3 oznacza przełom, ma też kompromisy:
- Czas trwania klipu nadal jest ograniczony (~16 s), więc dłuższe narracje wymagają zszywania lub wielu promptów.
- Koszt zasobów rośnie wraz z generowaniem HD i złożonym audio.
- Narzędzia AI wciąż wymagają osądu redakcyjnego, aby dopracować i zmontować output do formy finalnej.
A zatem: Vidu Q3 to pretendent z najwyższej półki w 2026 roku, szczególnie dla twórców, którzy priorytetowo traktują natywne workflowy audio i opowiadanie w wielu ujęciach. Czy jest tym najlepszym — zależy od konkretnego briefu produkcyjnego, ograniczeń regulacyjnych i Twojego pipeline’u dystrybucji.
Wnioski
Vidu Q3 wyróżnia się w 2026 roku jako wiodący model AI wideo zdolny do tworzenia klipów gotowych narracyjnie, zintegrowanych audio‑wideo, które łączą kreatywność z wymaganiami produkcyjnymi. W porównaniu z silną spójnością narracyjną Sora 2 i filmowym realizmem Veo 3.1, Vidu Q3 oferuje zrównoważone narzędzia idealne dla storytellerów, twórców treści i komercyjnych workflowów.
Jak pokazują benchmarki jego wysoką wydajność i zintegrowane funkcje, Vidu Q3 stanowi punkt zwrotny w generatywnym wideo AI — czyniąc złożoną produkcję audiowizualną bardziej dostępną i efektywną.
Deweloperzy mogą uzyskać dostęp do Vidu Q3, Veo 3.1 i Sora 2 przez CometAPI, najnowsze modele są wymienione na dzień publikacji artykułu. Aby zacząć, poznaj możliwości modelu w Playground i zapoznaj się z API guide w celu uzyskania szczegółowych instrukcji. Przed uzyskaniem dostępu upewnij się, że zalogowałeś(-aś) się do CometAPI i uzyskałeś(-aś) klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby ułatwić integrację.
Gotowy(-a) do startu?→ Zarejestruj się, aby generować wideo już dziś !
Jeśli chcesz poznawać więcej wskazówek, przewodników i wiadomości o AI, śledź nas na VK, X i Discord!