

W krajobrazie zdominowanym przez filozofię „skalowania za wszelką cenę” — gdzie modele takie jak Flux.2 i Hunyuan-Image-3.0 zwiększają liczbę parametrów do ogromnego poziomu 30B–80B — pojawił się nowy pretendent, który zaburza status quo. Z-Image, opracowany przez Tongyi Lab Alibaba, został oficjalnie uruchomiony, przełamując oczekiwania dzięki zwięzłej architekturze z 6 miliardami parametrów, która dorównuje jakości wyjściowej branżowych gigantów, a działa na sprzęcie klasy konsumenckiej.
Wydany pod koniec 2025 r., Z-Image (oraz jego błyskawiczna odmiana Z-Image-Turbo) natychmiast oczarował społeczność AI, przekraczając 500,000 downloads w ciągu 24 godzin od debiutu. Dostarczając fotorealistyczne obrazy w zaledwie 8 inference steps, Z-Image to nie tylko kolejny model; to siła demokratyzująca generatywne AI, umożliwiająca tworzenie wysokiej wierności na laptopach, które nie poradziłyby sobie z konkurencją.
What is Z-Image?
Z-Image to nowy, otwartoźródłowy model bazowy do generowania obrazów opracowany przez zespół badawczy Tongyi-MAI / Alibaba Tongyi Lab. Jest to generatywny model z 6 miliardami parametrów, zbudowany na nowej architekturze Scalable Single-Stream Diffusion Transformer (S3-DiT), która konkatenuje tokeny tekstowe, wizualno-semantyczne oraz tokeny VAE w jeden strumień przetwarzania. Cel projektowy jest jasny: zapewnić najwyższej klasy fotorealizm i zgodność z instrukcjami, jednocześnie drastycznie obniżając koszt inferencji i umożliwiając praktyczne użycie na sprzęcie klasy konsumenckiej. Projekt Z-Image publikuje kod, wagi modelu oraz demo online na licencji Apache-2.0.
Z-Image występuje w wielu wariantach. Najczęściej omawiane wydanie to Z-Image-Turbo — destylowana, kilkukrokowa wersja zoptymalizowana pod wdrożenia — plus niedestylowany Z-Image-Base (checkpoint bazowy, lepiej nadający się do fine-tuningu) oraz Z-Image-Edit (dostrojony do edycji obrazów).
The "Turbo" Advantage: 8-Step Inference
Flagowy wariant, Z-Image-Turbo, wykorzystuje progresywną technikę destylacji znaną jako Decoupled-DMD (Distribution Matching Distillation). Pozwala to skompresować proces generowania ze standardowych 30–50 kroków do zaledwie 8 steps.
Result: Czasy generowania poniżej sekundy na GPU klasy enterprise (H800) oraz praktycznie działanie w czasie rzeczywistym na kartach konsumenckich (RTX 4090), bez „plastikowego” czy „wyblakłego” wyglądu typowego dla innych modeli turbo/lightning.
4 Key Features of Z-Image
Z-Image jest pełen funkcji skierowanych zarówno do deweloperów technicznych, jak i profesjonalistów kreatywnych.
1. Unmatched Photorealism & Aesthetics
Pomimo zaledwie 6 miliardów parametrów Z-Image tworzy obrazy o zdumiewającej klarowności. Wyróżnia się w:
- Skin Texture: Odwzorowywaniu porów, niedoskonałości i naturalnego oświetlenia na ludzkich twarzach.
- Material Physics: Precyzyjnym renderowaniu szkła, metalu i faktur tkanin.
- Lighting: Lepszym prowadzeniu oświetlenia kinowego i wolumetrycznego w porównaniu ze SDXL.
2. Native Bilingual Text Rendering
Jednym z najistotniejszych problemów w generowaniu obrazów przez AI było renderowanie tekstu. Z-Image rozwiązuje to dzięki natywnemu wsparciu dla both English and Chinese.
- Potrafi generować złożone plakaty, logotypy i szyldy z poprawną pisownią i kaligrafią w obu językach — cecha często nieobecna w modelach skoncentrowanych na Zachodzie.
3. Z-Image-Edit: Instruction-Based Editing
Równolegle z modelem bazowym zespół wydał Z-Image-Edit. Ten wariant jest dostrojony do zadań image-to-image, pozwalając użytkownikom modyfikować istniejące obrazy za pomocą poleceń w języku naturalnym (np. „Spraw, aby osoba się uśmiechała”, „Zmień tło na ośnieżoną górę”). Podczas tych transformacji zachowuje wysoką spójność tożsamości i oświetlenia.
4. Consumer Hardware Accessibility
- VRAM Efficiency: Działa komfortowo na 6GB VRAM (z kwantyzacją) do 16GB VRAM (pełna precyzja).
- Local Execution: W pełni wspiera lokalne wdrożenia przez ComfyUI i
diffusers, uwalniając użytkowników od zależności chmurowych.
How does Z-Image Work?
Single-stream diffusion transformer (S3-DiT)
Z-Image odchodzi od klasycznych projektów dwustrumieniowych (oddzielne enkodery/strumienie tekstu i obrazu) i zamiast tego konkatenuje tokeny tekstowe, tokeny VAE obrazu i tokeny wizualno-semantyczne do pojedynczego wejścia transformera. To single-stream podejście poprawia wykorzystanie parametrów i upraszcza dopasowanie między modalnościami wewnątrz kręgosłupa transformera, co — jak twierdzą autorzy — daje korzystny kompromis między efektywnością a jakością dla modelu 6B.
Decoupled-DMD and DMDR (distillation + RL)
Aby umożliwić generowanie w niewielkiej liczbie kroków (8) bez zwyczajowej kary jakości, zespół opracował podejście destylacyjne Decoupled-DMD. Technika oddziela augmentację CFG (classifier-free guidance) od dopasowania rozkładu, pozwalając optymalizować je niezależnie. Następnie stosują etap szkolenia z uczeniem ze wzmocnieniem (DMDR) po treningu, aby dopracować dopasowanie semantyczne i estetykę. Razem dają Z-Image-Turbo z dużo mniejszą liczbą NFEs niż typowe modele dyfuzyjne, przy zachowaniu wysokiego realizmu.
Training throughput and cost optimisation
Z-Image był trenowany z podejściem optymalizacji cyklu życia: kuratorowane potoki danych, uproszczony program nauczania i wybory implementacyjne uwzględniające efektywność. Autorzy raportują ukończenie pełnego przebiegu treningu w około 314K H800 GPU hours (≈ USD $630K) — konkretny, replikowalny wskaźnik inżynieryjny, który pozycjonuje model jako bardziej opłacalny względem bardzo dużych alternatyw (>20B).
Benchmark Results of the Z-Image Model
Z-Image-Turbo uplasował się wysoko na kilku współczesnych listach rankingowych, w tym na czołowej pozycji open-source na Artificial Analysis Text-to-Image leaderboard oraz osiągnął mocne wyniki w ocenach preferencji użytkowników na Alibaba AI Arena.
Jednak rzeczywista jakość zależy także od formułowania promptów, rozdzielczości, potoku upscalingu i dodatkowego postprocessingu.
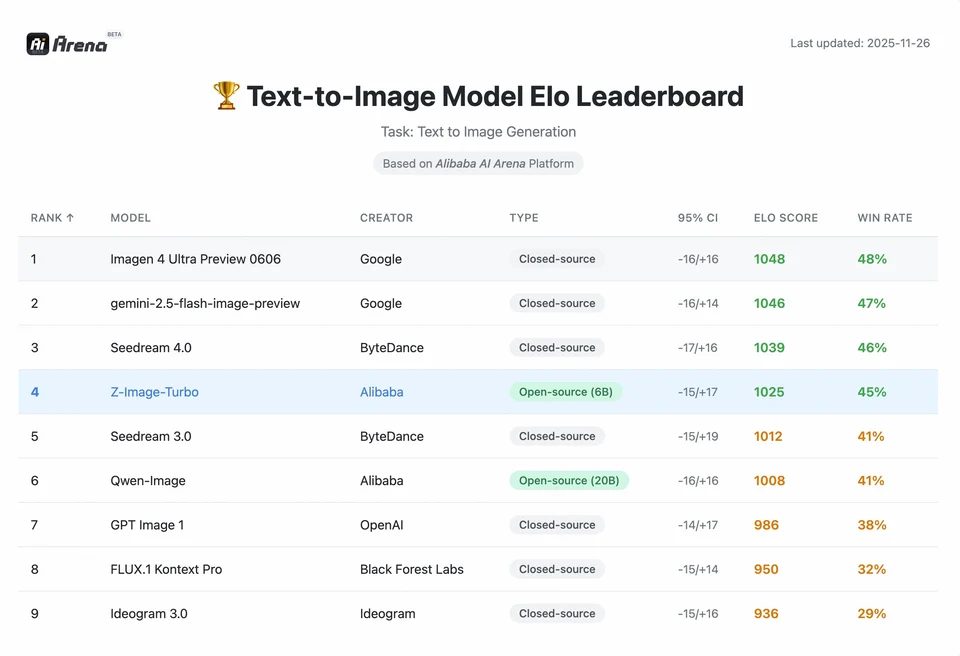
Aby zrozumieć skalę osiągnięcia Z-Image, należy spojrzeć na dane. Poniżej znajduje się analiza porównawcza Z-Image na tle wiodących modeli open-source i własnościowych.
Comparative Benchmark Summary
| Feature / Metric | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Architecture | S3-DiT (Single Stream) | MM-DiT (Dual Stream) | U-Net | Diffusion Transformer |
| Parameters | 6 Billion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Inference Steps | 8 Steps | 25 - 50 Steps | 1 - 4 Steps | 30 - 50 Steps |
| VRAM Required | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Text Rendering | High (EN + CN) | High (EN) | Moderate (EN) | High (CN + EN) |
| Generation Speed (4090) | ~1.5 - 3.0 Seconds | ~15 - 30 Seconds | ~0.5 Seconds | ~20 Seconds |
| Photorealism Score | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| License | Apache 2.0 | Non-Commercial (Dev) | OpenRAIL | Custom |
Data Analysis & Performance Insights
- Speed vs. Quality: Chociaż SDXL Turbo jest szybszy (1 krok), jego jakość znacząco spada przy złożonych promptach. Z-Image-Turbo trafia w „sweet spot” przy 8 krokach, dorównując jakości Flux.2, będąc 5x to 10x faster.
- Hardware Democratization: Flux.2, choć potężny, jest de facto ograniczony do kart z 24GB VRAM (RTX 3090/4090) dla rozsądnej wydajności. Z-Image pozwala użytkownikom z kartami ze średniej półki (RTX 3060/4060) generować lokalnie obrazy 1024x1024 o jakości profesjonalnej.
How can developers access and use Z-Image?
Istnieją trzy typowe podejścia:
- Hosted / SaaS (web UI or API): Skorzystaj z usług takich jak z-image.ai lub innych dostawców, którzy wdrażają model i udostępniają interfejs webowy lub płatne API do generowania obrazów. To najszybsza droga do eksperymentów bez lokalnej konfiguracji.
- Hugging Face + diffusers pipelines: Biblioteka Hugging Face
diffuserszawieraZImagePipelineiZImageImg2ImgPipelineoraz zapewnia typowe przepływyfrom_pretrained(...).to("cuda"). To rekomendowana ścieżka dla programistów Pythona, którzy chcą prostych integracji i powtarzalnych przykładów. - Local native inference from the GitHub repo: Repozytorium Tongyi-MAI zawiera natywne skrypty inferencji, opcje optymalizacji (FlashAttention, kompilacja, odciążenie na CPU) oraz instrukcje instalacji
diffusersze źródeł dla najnowszej integracji. Ta droga jest przydatna dla badaczy i zespołów chcących pełnej kontroli lub uruchamiania własnego treningu/fine-tuningu.
What does a minimal Python example look like?
Poniżej znajduje się zwięzły fragment Pythona używający Hugging Face diffusers, który demonstruje generowanie tekst-do-obrazu z Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Notes:guidance_scale domyślne wartości i zalecane ustawienia różnią się dla modeli Turbo; dokumentacja sugeruje, że sterowanie może być ustawione nisko lub na zero dla Turbo, w zależności od docelowego zachowania.
How do you run image-to-image (edit) with Z-Image?
ZImageImg2ImgPipeline obsługuje edycję obrazu. Przykład:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
To odzwierciedla oficjalne wzorce użycia i nadaje się do kreatywnej edycji oraz zadań inpaintingu.
How should you approach prompts and guidance?
- Be explicit with structure: Dla złożonych scen strukturyzuj prompty, uwzględniając kompozycję sceny, obiekt główny, kamerę/obiektyw, oświetlenie, nastrój oraz elementy tekstowe. Z-Image korzysta z szczegółowych promptów i dobrze radzi sobie z wskazówkami pozycyjnymi/narracyjnymi.
- Tune guidance_scale carefully: Modele Turbo mogą zalecać niższe wartości sterowania; konieczne są eksperymenty. W wielu przepływach Turbo
guidance_scale=0.0–1.0z seedem i stałą liczbą kroków daje spójne wyniki. - Use image-to-image for controlled edits: Gdy chcesz zachować kompozycję, ale zmienić styl/kolorystykę/obiekty, zacznij od obrazu inicjalnego i użyj
strength, aby kontrolować skalę zmian.
Best Use Cases and Best Practices
1. Rapid Prototyping & Storyboarding
Use Case: Reżyserzy filmowi i projektanci gier muszą natychmiast wizualizować sceny.
Why Z-Image? Dzięki czasom generowania poniżej 3 sekund twórcy mogą iterować setki koncepcji w jednej sesji, dopracowując oświetlenie i kompozycję w czasie rzeczywistym, bez czekania minut na render.
2. E-Commerce & Advertising
Use Case: Generowanie teł produktowych lub ujęć lifestyle dla towarów.
Best Practice: Użyj Z-Image-Edit.
Prześlij surowe zdjęcie produktu i użyj polecenia w stylu „Umieść ten flakon perfum na drewnianym stole w nasłonecznionym ogrodzie.” Model zachowuje integralność produktu, jednocześnie halucynując fotorealistyczne tło.
3. Bilingual Content Creation
Use Case: Globalne kampanie marketingowe wymagające zasobów dla rynków zachodnich i azjatyckich.
Best Practice: Wykorzystaj możliwość renderowania tekstu.
- Prompt: „Neonowy szyld z napisem 'OPEN' i '营业中' jarzący się w ciemnej alejce.”
- Z-Image poprawnie wyrenderuje zarówno angielskie, jak i chińskie znaki — czego większość innych modeli nie potrafi.
4. Low-Resouce Environments
Use Case: Uruchamianie generowania AI na urządzeniach brzegowych lub standardowych laptopach biurowych.
Optimization Tip: Użyj INT8 zkwantyzowanej wersji Z-Image. Obniża zużycie VRAM do poniżej 6GB przy pomijalnej utracie jakości, co czyni ją realną dla lokalnych aplikacji na laptopach bez GPU do gier.
Bottom line: who should use Z-Image?
Z-Image jest przeznaczony dla organizacji i deweloperów, którzy chcą high-quality photorealism przy praktycznej latencji i koszcie, a także preferują open licensing oraz wdrożenia on-premises lub własny hosting. Jest szczególnie atrakcyjny dla zespołów potrzebujących szybkiej iteracji (narzędzia kreatywne, makiety produktów, usługi czasu rzeczywistego) oraz dla badaczy/społeczności zainteresowanych fine-tuningiem kompaktowego, ale potężnego modelu obrazów.
CometAPI oferuje podobnie mniej ograniczone modele Grok Image, a także modele takie jak Nano Banana Pro, GPT- image 1.5, Sora 2(Can Sora 2 generate NSFW content? How can we try it?) itd. — o ile masz odpowiednie wskazówki i triki NSFW, aby obejść ograniczenia i zacząć tworzyć swobodnie. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby pomóc w integracji.
Ready to Go?→ Free trial for Creating !