

Em julho de 2025, o Alibaba revelou Codificador Qwen3, seu modelo de IA de código aberto mais avançado, projetado especificamente para fluxos de trabalho de codificação complexos e tarefas de programação agêntica. Este guia profissional o guiará passo a passo por tudo o que você precisa saber — desde a compreensão de seus principais recursos e principais inovações até a instalação e o uso do software que o acompanha. Código Qwen Ferramenta CLI para codificação automatizada no estilo agente. Ao longo do caminho, você aprenderá práticas recomendadas, dicas de solução de problemas e como otimizar seus prompts e alocação de recursos para aproveitar ao máximo o Qwen3-Coder.
O que é Qwen3‑Coder e por que ele é importante?
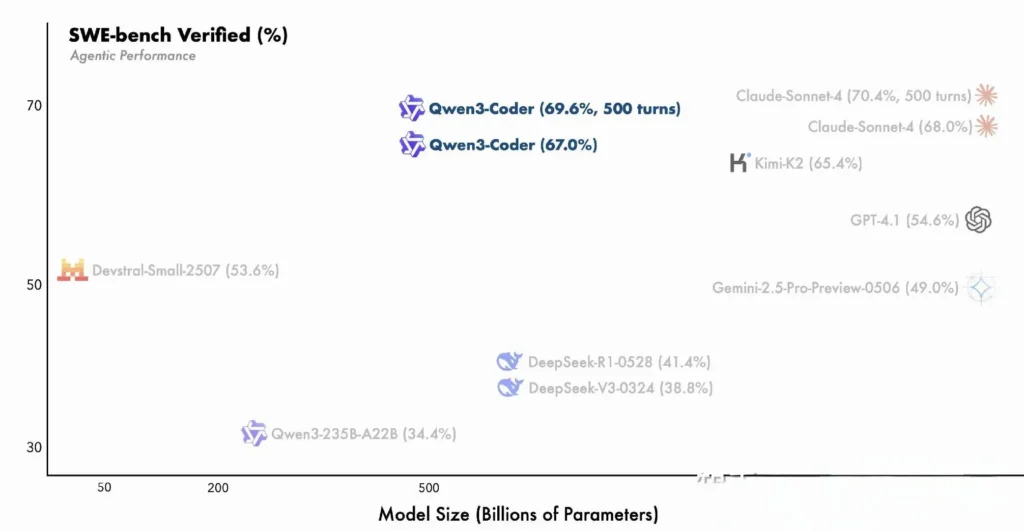
O Qwen3-Coder da Alibaba é um modelo de Mistura de Especialistas (MoE) com 480 bilhões de parâmetros e 35 bilhões de parâmetros ativos, desenvolvido para suportar tarefas de codificação em contextos amplos — processando nativamente 256 mil tokens (e até 1 milhão com métodos de extrapolação). Lançado em 23 de julho de 2025, ele representa um grande avanço na "codificação de IA agêntica", onde o modelo não apenas gera código, mas também pode planejar, depurar e iterar de forma autônoma em desafios complexos de programação, sem intervenção manual.
Como o Qwen3‑Coder difere de seus antecessores?
O Qwen3-Coder baseia-se nas inovações da família Qwen3 — integrando o "modo de pensamento" para raciocínio em várias etapas e o "modo não-pensante" para respostas rápidas — em uma estrutura única e unificada que alterna os modos dinamicamente com base na complexidade da tarefa. Ao contrário do Qwen2.5-Coder, que era denso e limitado a contextos menores, o Qwen3-Coder emprega uma arquitetura esparsa de Mistura de Especialistas para oferecer desempenho de ponta em benchmarks como o SWE-Bench Verified e as classificações ELO do CodeForces, igualando ou superando modelos como o Claude da Anthropic e o GPT-4 da OpenAI em métricas-chave de codificação.
principais recursos do Qwen3‑Coder:
- Janela de contexto massiva: 256 K tokens nativamente, até 1 M via extrapolação, permitindo processar bases de código inteiras ou documentação longa em uma única passagem.
- Capacidades de agente: Um “modo agente” dedicado que pode planejar, gerar, testar e depurar código de forma autônoma, reduzindo a sobrecarga de engenharia manual.
- Alto rendimento e eficiência: O design de mistura de especialistas ativa apenas 35 bilhões de parâmetros por inferência, equilibrando o desempenho com o custo computacional.
- Código aberto e extensível: Lançado no Apache 2.0, com APIs totalmente documentadas e melhorias conduzidas pela comunidade disponíveis no GitHub.
- Multi-idioma e domínio cruzado: Treinado em 7.5 trilhões de tokens (70% de código) em dezenas de linguagens de programação, de Python e JavaScript a Go e Rust.
Como os desenvolvedores podem começar a usar o Qwen3‑Coder?
Onde posso baixar e instalar o Qwen3‑Coder?
Você pode obter os pesos do modelo e as imagens do Docker em:
- GitHub: https://github.com/QwenLM/Qwen3-Coder
- Abraçando o rosto: https://huggingface.co/QwenLM/Qwen3-Coder-480B-A35B-Instruct
- Escopo do modelo: Repositório oficial do Alibaba
Basta clonar o repositório e puxar o contêiner Docker pré-construído:
git clone https://github.com/QwenLM/Qwen3-Coder.git
cd Qwen3-Coder
docker pull qwenlm/qwen3-coder:latest
Carregando o modelo com transformadores
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-480B-A35B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
Este código inicializa o modelo e o tokenizador, distribuindo automaticamente camadas entre as GPUs disponíveis.
Como configuro meu ambiente?
- Requisitos de hardware:
- GPUs NVIDIA com ≥ 48 GB de VRAM (A100 80 GB recomendado)
- 128–256 GB de RAM do sistema
-
Dependências:
pip install -r requirements.txt # PyTorch, CUDA, tokenizers, etc. -
Chaves de API (opcional):
Para inferência hospedada na nuvem, defina seuALIYUN_ACCESS_KEYeALIYUN_SECRET_KEYcomo variáveis de ambiente.
Como você usa o Qwen Code para codificação agêntica?
Aqui está um guia passo a passo para começar a usar Qwen3‑Coder via Código Qwen CLI (invocado simplesmente como qwen):
1. Pré-requisitos
- Node.js 20+ (você pode instalar através do instalador oficial ou através do script abaixo)
- npm, que vem junto com o Node.js
# (Linux/macOS)
curl -qL https://www.npmjs.com/install.sh | sh
2. Instale o Qwen Code CLI
npm install -g @qwen-code/qwen-code
Alternativamente, para instalar a partir da fonte:
git clone https://github.com/QwenLM/qwen-code.git
cd qwen-code
npm install
npm install -g
3. Configure seu ambiente
O código Qwen usa o Compatível com OpenAI Interface de API por baixo dos panos. Defina as seguintes variáveis de ambiente:
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
export OPENAI_MODEL="qwen3-coder-plus"
OPENAI_MODEL pode ser definido como um dos seguintes:
qwen3-coder-plus(também conhecido como Qwen3‑Coder-480B-A35B-Instruct)- ou qualquer outra variante do Qwen3‑Coder que você tenha implantado.
4. Uso Básico
- Inicie um REPL de codificação interativa:
qwen
Isso o levará a uma sessão de codificação de agente com tecnologia Qwen3‑Coder.
- Prompt único do Shell para solicitar um trecho de código ou concluir uma função:
qwen code complete \
--model qwen3-coder-plus \
--prompt "Write a Python function that reverses a linked list."
- Complementação de código baseada em arquivo, preencha ou refatore automaticamente um arquivo existente:
qwen code file-complete \
--model qwen3-coder-plus \
--file ./src/utils.js
- Interação estilo chat, use o Qwen no modo “chat”, ideal para diálogos de codificação multi-turno:
qwen chat \
--model qwen3-coder-plus \
--system "You are a helpful coding assistant." \
--user "Generate a REST API endpoint in Express.js for user authentication."
Como invocar o Qwen3-Coder via API CometAPI?
A CometAPI é uma plataforma de API unificada que agrega mais de 500 modelos de IA de provedores líderes — como a série GPT da OpenAI, a Gemini do Google, a Claude da Anthropic, a Midjourney e a Suno, entre outros — em uma interface única e amigável ao desenvolvedor. Ao oferecer autenticação, formatação de solicitações e tratamento de respostas consistentes, a CometAPI simplifica drasticamente a integração de recursos de IA em seus aplicativos. Seja para criar chatbots, geradores de imagens, compositores musicais ou pipelines de análise baseados em dados, a CometAPI permite iterar mais rapidamente, controlar custos e permanecer independente de fornecedores — tudo isso enquanto aproveita os avanços mais recentes em todo o ecossistema de IA.
Se você for um usuário do cometaAPI, poderá fazer login no cometapi para obter a chave e a URL base e fazer login no cometapi para obter a chave e a URL base, consulte API do codificador Qwen3Para começar, explore as capacidades dos modelos no Playground e consulte o Guia de API para instruções detalhadas.
Para chamar o Qwen3‑Coder por meio do CometAPI, você usa os mesmos pontos de extremidade compatíveis com OpenAI de qualquer outro modelo - basta apontar seu cliente para o URL base do CometAPI, apresentar sua chave CometAPI como um token Bearer e especificar o qwen3-coder-plus or qwen3-coder-480b-a35b-instruct modelo.
1. Pré-requisitos
- Inscreva-se at https://cometapi.com e adicione/gere um token de API no seu painel.
- Observe o seu Chave API (começa com
sk-…). - Familiaridade com o protocolo OpenAI Chat API (funções + mensagens).
2. URL base e autenticação
URL base:
arduinohttps://api.cometapi.com/v1
Ponto final:
bashPOST https://api.cometapi.com/v1/chat/completions
3. Exemplo de cURL / REST
curl https://api.cometapi.com/v1/chat/completions \
-H "Authorization: Bearer sk-xxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-coder-plus",
"messages": [
{ "role": "system", "content": "You are a helpful coder." },
{ "role": "user", "content": "Generate a SQL query to find duplicate emails." }
],
"temperature": 0.7,
"max_tokens": 512
}'
- Automatizadas: JSON com
choices.message.contentcontendo o código gerado.
Como você aproveita os recursos de agente do Qwen3-Coder?
Os recursos de agente do Qwen3-Coder permitem invocação dinâmica de ferramentas e fluxos de trabalho autônomos de várias etapas, permitindo que o modelo chame funções externas ou APIs durante a geração de código.
Invocação de ferramentas e ferramentas personalizadas
Defina ferramentas personalizadas — como linters, executores de testes ou formatadores — na sua base de código e exponha-as ao modelo por meio de esquemas de funções. Por exemplo:
tools = [
{"name":"run_tests","description":"Execute the test suite and return results","parameters":{}},
{"name":"format_code","description":"Apply black formatter to the code","parameters":{}}
]
response = client.chat.completions.create(
messages=,
functions=tools,
function_call="auto"
)
O Qwen3-Coder pode então gerar, formatar e validar código de forma autônoma em uma sessão, reduzindo a sobrecarga de integração manual ().
Usando Qwen Code CLI
O qwen-code A ferramenta de linha de comando oferece um REPL interativo para codificação de agente:
qwen-code --model qwen3-coder-480b-a35b-instruct
> generate: "Create a REST API in Node.js with JWT authentication."
> tool: install_package(express)
> tool: create_file(app.js)
> tool: run_tests
Esta CLI orquestra fluxos de trabalho complexos com logs transparentes, tornando-a ideal para prototipagem exploratória ou integração em pipelines de CI/CD.
O Qwen3-Coder é adequado para grandes bases de código?
Graças à sua janela de contexto estendida, o Qwen3-Coder pode ingerir repositórios inteiros — até centenas de milhares de linhas de código — antes de gerar patches ou refatorações. Esse recurso permite refatorações globais, análises entre módulos e sugestões arquitetônicas que modelos de contexto menor simplesmente não conseguem igualar.
Quais são as melhores práticas para maximizar a utilidade do Qwen3-Coder?
Adotar o Qwen3-Coder de forma eficaz requer configuração e integração cuidadosas ao seu pipeline de CI/CD.
Como você deve ajustar as configurações de amostragem e feixe?
- Temperatura: 0.6–0.8 para criatividade equilibrada; menor (0.2–0.4) para tarefas de refatoração determinística.
- Topo-p: 0.7–0.9 para focar nas continuações mais prováveis, permitindo sugestões ocasionais de novidades.
- Top-k: 20–50 para uso padrão; reduza para 5–10 quando buscar resultados altamente focados.
- Penalidade por Repetição: 1.05–1.1 para desencorajar o modelo de repetir padrões clichê.
Experimentar esses parâmetros de acordo com a tolerância de variação do seu projeto pode gerar ganhos significativos de produtividade.
Quais são as melhores práticas para usar o Qwen3-Coder de forma eficaz?
Engenharia Rápida para Qualidade de Código
- Seja específico: Especifique o idioma, as diretrizes de estilo e a complexidade desejada no seu prompt.
- Refinamento Iterativo: Use os recursos de agente do modelo para depurar e otimizar iterativamente o código gerado.
- Ajuste de temperatura: Reduzir a temperatura de geração (por exemplo,
temperature=0.2) para resultados mais determinísticos em contextos de produção.
Gerenciando a utilização de recursos
- Variantes do modelo: Comece com variantes menores do Qwen3-Coder para prototipagem e depois aumente conforme necessário.
- Quantização Dinâmica: Experimente pontos de verificação quantizados FP8 e GGUF para reduzir o consumo de memória da GPU sem queda significativa no desempenho.
- Geração Assíncrona: Transfira gerações de código de longa execução para trabalhadores em segundo plano para manter a capacidade de resposta.
Seguir essas diretrizes garante que você maximize o ROI da integração do Qwen3-Coder ao seu ciclo de vida de desenvolvimento de software.
Seguindo as orientações acima — entendendo sua arquitetura, instalando e configurando o modelo e o Qwen Code CLI e aproveitando as melhores práticas — você estará bem equipado para aproveitar todo o potencial do Qwen3-Coder para qualquer coisa, desde simples trechos de código até agentes de programação totalmente autônomos.