

Em suas atualizações de outubro, a OpenAI relatou que cerca de 0.15% dos usuários ativos semanais ter conversas que contenham indicadores explícitos de potencial planeamento ou intenção suicida — uma percentagem que, quando dimensionada para a grande base de utilizadores do ChatGPT, corresponde a mais de um milhão de pessoas por semana Ao discutir tópicos relacionados ao suicídio com o serviço, isso colocou em evidência uma questão complexa: os grandes modelos de linguagem podem responder de forma significativa e segura quando as pessoas trazem preocupações graves de saúde mental — incluindo psicose, mania, intenção suicida e profunda dependência emocional — para um bate-papo?
Portanto, as atualizações de outubro da OpenAI para o GPT-5 — lançadas em produção como gpt-5-oct-3 atualização — representam o esforço mais explícito e ponderado da empresa para tornar os modelos de linguagem de grande porte (LLMs) mais seguros e úteis quando os usuários mencionam preocupações com saúde mental. As mudanças não são uma solução mágica; são um conjunto de medidas técnicas, processuais e de avaliação destinadas a reduzir resultados prejudiciais ou inúteis, expor recursos profissionais e desencorajar os usuários a confiar no modelo como substituto do atendimento clínico. Mas quão melhor é o sistema na prática, o que exatamente mudou e quais são os riscos restantes?
O que a OpenAI atualizou no gpt-5 e por que isso é importante?
A OpenAI implementou uma atualização do modelo GPT-5 padrão do ChatGPT (comumente referenciado nas comunicações como gpt-5-oct-3) destinado especificamente a fortalecer o comportamento do modelo em conversas sensíveis — aqueles que incluem sinais de psicose ou mania, ideação ou planejamento suicida, ou o tipo de dependência emocional de uma IA que pode deslocar relacionamentos do mundo real.
As mudanças foram informadas por consultas com mais de 170 especialistas em saúde mental e por novas taxonomias internas e avaliações automatizadas projetadas em torno de “comportamentos desejados” concretos, após serem otimizadas por especialistas em psicologia, o modelo GPT-5:
- Em conjuntos de desafios de saúde mental direcionados, o novo modelo GPT-5 obteve pontuação ~% 92 compatível com a taxonomia de comportamento desejada pela empresa (em comparação com porcentagens muito mais baixas para versões anteriores em conjuntos de testes difíceis).
- Para cenários de automutilação e suicídio, as avaliações automatizadas aumentaram para ~% 91 conformidade de 77% na variante GPT-5 anterior no benchmark específico descrito. A OpenAI também relata ~% 65 redução nas taxas de respostas que “não estão em total conformidade” em vários domínios de saúde mental no tráfego de produção.
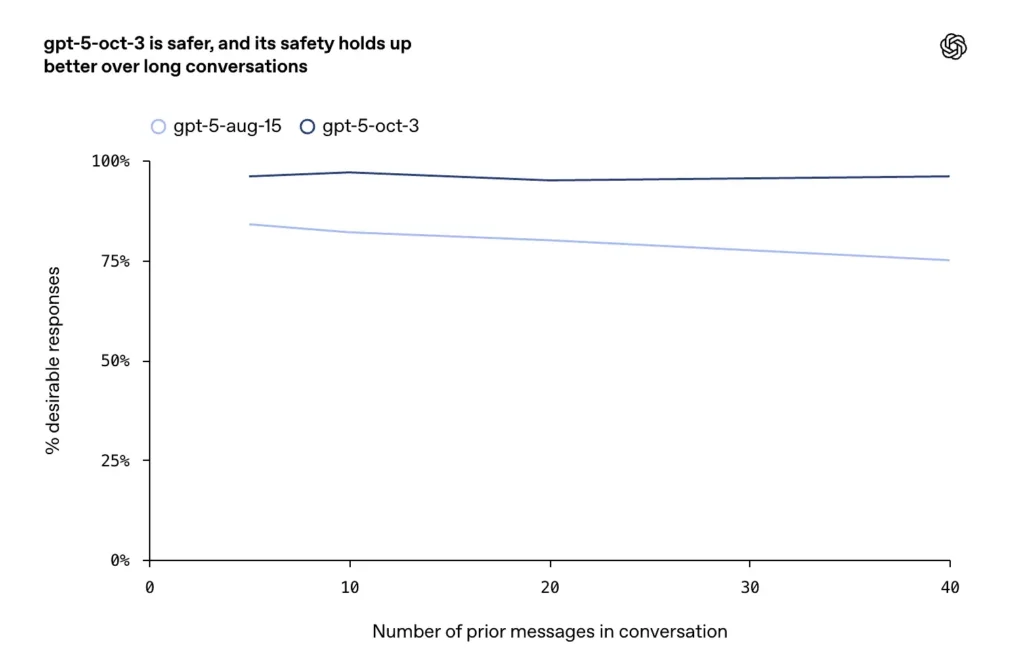
- Melhorias foram relatadas em conversas longas, conflituosas ou prolongadas (um modo de falha conhecido para modelos de bate-papo), onde a empresa diz que as atualizações de outubro mantêm maior consistência e segurança em turnos de diálogo prolongados.
por que isso Importa
A OpenAI afirmou que — dada a escala atual do ChatGPT — mesmo porcentagens muito pequenas de conversas sensíveis correspondem a números absolutos muito grandes de pessoas. A empresa relatou que, em uma semana típica:
- sobre 0.07% de usuários ativos apresentam possíveis sinais consistentes com psicose ou mania; e
- sobre 0.15% dos usuários ativos têm conversas que incluem indicadores explícitos de potencial planejamento ou intenção suicida; e
- grosseiramente 0.15% dos usuários ativos mostram “níveis elevados” de apego emocional ao ChatGPT.
Para tornar essas porcentagens concretas: o CEO da OpenAI disse que o ChatGPT tem ~800 milhões de usuários ativos semanais. A multiplicação produz contagens absolutas de usuários:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
As categorias são ruidosas e sobrepostas (uma única conversa pode aparecer em mais de uma categoria) e que estas são estimativas derivados de taxonomias de detecção interna em vez de diagnósticos clínicos.
Como a OpenAI implementou essas mudanças — mecanismo de melhoria de cinco etapas?
O OpenAI descreve um processo multifacetado e informado por especialistas. Abaixo, um resumo reprodutível mecanismo de melhoria de cinco etapas que mapeia as divulgações da empresa e as práticas comuns em engenharia de segurança de modelos.
Mecanismo de melhoria de cinco etapas
- Taxonomia e rotulagem guiadas por especialistas. Reúna psiquiatras, psicólogos e clínicos de atenção primária para definir os comportamentos e a linguagem que indicam psicose/mania, intenção de automutilação ou dependência emocional doentia; crie conjuntos de dados rotulados e regras de adjudicação.
- Coleta de dados direcionada e prompts selecionados. Reúna trechos de conversas representativas, exemplos de casos extremos e contribuições adversas; complemente com transcrições de dramatizações controladas produzidas com a supervisão do médico.
- Ajuste/ajuste fino do modelo com objetivos de segurança. Treine ou ajuste o modelo base no conjunto de dados selecionado com termos de perda que penalizam o reforço de delírios, fornecem modelos de resposta segura e promovem o roteamento para recursos de crise.
- Classificador + camada de proteção (segurança em tempo de execução). Implante um classificador rápido ou uma camada de monitoramento que detecte desvios de alto risco em tempo real e altere os parâmetros de decodificação do modelo, alterne para um respondedor especializado ou encaminhe para pipelines de revisão humana. (Isso é crucial para evitar comportamentos frágeis quando a conversa se desvia.)
- Avaliação de especialistas humanos e calibração contínua. Peça aos médicos que avaliem cegamente as respostas do modelo usando rubricas de avaliação clínica; meçam as taxas de resposta indesejadas; iterem na taxonomia, nos dados de treinamento e nos prompts do sistema. Mantenha a telemetria da produção e execute novamente os benchmarks regularmente.
Abaixo está um pseudocódigo compacto/esboço técnico que captura o fluxo de tempo de execução que a maioria das equipes de segurança implementa (este é ilustrativo e não proprietários):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
O pipeline de produção normalmente inclui classificadores de curto prazo (rápidos), respondedores mais lentos, mas de maior qualidade (avisos especializados/pontos de verificação ajustados) e revisão humana para casos sinalizados. Isso não é puramente acadêmico: médicos revisaram mais de 1,800 respostas modelo e as classificou de acordo com a taxonomia, e que essas revisões moldaram materialmente como os prompts e comportamentos de fallback foram escritos.
A OpenAI informou publicamente que utilizou variações de todas as cinco etapas, além de avaliações clínicas, para avaliar os resultados:
- Especialistas analisaram mais de 1,800 respostas de modelos.
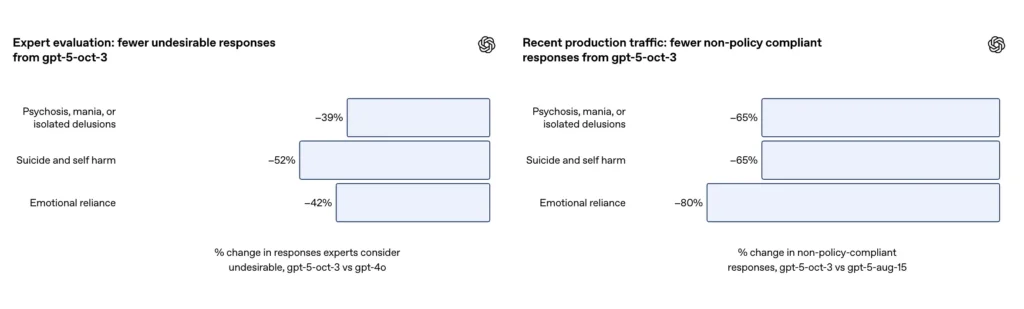
- O GPT-5 reduziu as “respostas insatisfatórias” em 39–52% em todas as categorias.
- A confiabilidade entre avaliadores variou de 71% a 77%, indicando um alto grau de consenso geral, apesar das diferenças subjetivas.
Como o GPT-5 reage atualmente à psicose ou à mania?
O que a OpenAI ensinou o modelo a fazer (e o que não fazer)
A medida: Aprimorar o reconhecimento e a resposta do modelo a sintomas graves, como alucinações e mania. Para conversas que sinalizam possíveis crenças delirantes, alucinações ou mania, a OpenAI reescreveu partes da especificação do modelo e forneceu exemplos de treinamento supervisionado para que o GPT-5 responda sem confirmar ou amplificar crenças infundadas. O modelo é incentivado a ser empático, a evitar validar delírios e a reformular ou redirecionar o usuário gentilmente para medidas práticas de segurança e ajuda profissional quando necessário.
O que a avaliação mostra
A OpenAI relata que, em um conjunto de testes com conversas complexas sobre psicose/mania, a versão mais recente do GPT-5 reduziu substancialmente as respostas indesejadas em comparação com as versões anteriores, e que as avaliações automatizadas classificam o modelo atualizado com alta conformidade em sua taxonomia.
| métrico | GPT-4o | GPT-5 | Melhoria |
|---|---|---|---|
| Taxa de resposta de não conformidade | Linha de Base | ↓ 65% | Melhoria significativa |
| Avaliação Clínica Especializada | - | Redução de 39% nas reações adversas. | - |
| Taxa de conformidade de autoavaliação | 27% | 92% | ↑65 pontos percentuais |
| Taxa de envolvimento do usuário | ~0.07% de usuários ativos semanais | Extremamente baixo, mas claramente monitorado. | - |
Nota:
- As respostas inadequadas diminuíram em 65%;
- Apenas 0.07% dos usuários e 0.01% das mensagens continham esse tipo de conteúdo;
- Em avaliações de especialistas, o GPT-5 produziu 39% menos respostas inadequadas do que o GPT-4;
- Em avaliações automatizadas, o GPT-5 alcançou uma taxa de conformidade de 92% (em comparação com 27% para seu antecessor).
Como o GPT-5 lida com ideação suicida e automutilação?
Encaminhamento mais robusto para suporte e recusa em fornecer instruções.
A OpenAI descreve um treinamento expandido e explícito para casos de automutilação e suicídio: o modelo é treinado para reconhecer sinais diretos e indiretos de intenção ou planejamento, fornecer linguagem empática e desescaladora, apresentar recursos de crise (linhas de apoio, instruções de emergência locais) e recusar-se a fornecer instruções para automutilação. As atualizações de outubro enfatizam um comportamento mais consistente em conversas longas, onde os modelos anteriores às vezes tendiam a dar respostas inseguras ou inconsistentes.
Resultados medidos
Em um conjunto de avaliações selecionadas de conversas desafiadoras sobre automutilação e suicídio, a OpenAI relata que o GPT-5 atualizado alcançou 91% de conformidade com os comportamentos desejados da OpenAI, em comparação com 77% para o modelo GPT-5 anterior. A empresa também afirma que especialistas no assunto avaliaram que o modelo atualizado reduziu as respostas indesejadas em aproximadamente 52% versus GPT-4o no mesmo conjunto de problemas. Além disso, a OpenAI afirma que estima-se que Redução de 65% no tráfego de produção de respostas que "não cumprem totalmente" sua taxonomia para situações de autolesão após a implementação das novas salvaguardas.
| métrico | GPT-4o | GPT-5 | Melhoria |
|---|---|---|---|
| Taxa de resposta inadequada | Linha de Base | ↓ 65% | Melhoria significativa |
| Avaliação de especialistas clínicos | - | Respostas inadequadas reduzidas em 52% | - |
| Taxa de conformidade de autoavaliação | 77% | 91% | ↑14 pontos percentuais |
| Taxa de envolvimento do usuário | 0.15% semanalmente (milhões de usuários) | Muito baixo, mas socialmente significativo. | - |
Nota:
- As respostas inadequadas diminuíram em 65%;
- Aproximadamente 0.15% dos usuários e 0.05% das mensagens envolviam riscos potenciais de suicídio;
- Avaliações de especialistas mostraram que o GPT-5 reduziu as respostas inadequadas em 52% em comparação com o GPT-4o;
- A taxa de conformidade nas avaliações automatizadas aumentou para 91% (em comparação com 77% na geração anterior);
- Em conversas prolongadas, o GPT-5 manteve uma estabilidade superior a 95%.
O que é “dependência emocional” e como foi abordada?
O desafio dos usuários em criar vínculos afetivos
A OpenAI define dependência emocional como padrões em que um usuário demonstra uma dependência potencialmente prejudicial da IA, em detrimento de seus relacionamentos, responsabilidades ou bem-estar no mundo real. Isso não representa uma falha imediata de segurança física, como instruções para automutilação, mas sim um problema de segurança comportamental que pode corroer o apoio social e a resiliência de uma pessoa ao longo do tempo. A empresa tornou a dependência emocional uma categoria explícita em seu trabalho de especificação do modelo e o treinou para incentivar a conexão com o mundo real, normalizar o contato com outras pessoas e evitar linguagem que reforce a exclusividade do apego.
Nessas conversas, o modelo foi treinado para:
- Incentive os usuários a entrarem em contato com amigos, familiares ou um terapeuta;
- Evite reforçar o apego à IA;
- Responda a delírios ou crenças falsas de maneira gentil e racional.
Resultados relatados
De acordo com o adendo da OpenAI, a atualização produziu um ~80% de redução na taxa de respostas do modelo que não estão totalmente em conformidade com a taxonomia de dependência emocional no tráfego de produção. Em conversas de avaliação selecionadas, as avaliações automatizadas pontuaram o modelo atualizado em 97% de conformidade com o comportamento desejado para cenários de dependência emocional, em comparação com 50% para o GPT-5 anterior. Os números sugerem uma grande melhoria na taxonomia específica e no conjunto de testes; no entanto, medir a dependência emocional em situações reais é inerentemente impreciso e sensível a diferenças culturais e contextuais.
| métrico | GPT-4o | GPT-5 | Melhoria |
|---|---|---|---|
| Taxa de resposta de não conformidade | 50% | 97% compliant | ↓80% de respostas inadequadas |
| Avaliação especializada | Respostas inadequadas reduzidas em 42% | - | - |
| Taxa de envolvimento do usuário | 0.15% de usuários/semana, 0.03% de mensagens | Raro, mas existe. | - |
| Comportamento do modelo | Incentiva relacionamentos no mundo real; rejeita o "romance social simulado". | - | - |
Nota:
- As respostas inadequadas diminuíram em 80%;
- Aproximadamente 0.15% dos usuários/0.03% das mensagens apresentaram sinais de potencial dependência emocional da IA;
- A avaliação de especialistas mostrou que o GPT-5 reduziu as respostas inadequadas em 42% em comparação com o GPT-4o;
- A conformidade com a avaliação automatizada melhorou significativamente, passando de 50% para 97%.
Quais são os limites e os riscos existentes?
Falsos negativos e falsos positivos
- Falsos negativosO modelo pode não conseguir identificar sinais sutis ou codificados de que um usuário está em perigo iminente — especialmente quando as pessoas se comunicam de forma indireta ou em código.
- Falso-positivoO sistema pode intensificar o alerta ou fornecer mensagens de crise em casos que não exigem isso, o que pode minar a confiança do usuário ou gerar alarmes desnecessários. Ambos os tipos de erro são importantes porque moldam o comportamento do usuário e a percepção do atendimento. A OpenAI reconhece que a detecção é imperfeita.
Excesso de confiança na automação
Mesmo o melhor modelo pode levar alguns usuários a dependerem de respostas instantâneas e sempre disponíveis da IA, em vez de buscarem suporte humano contínuo. A OpenAI sinaliza explicitamente a dependência emocional como uma categoria de risco devido a essa vulnerabilidade; as atualizações da empresa tentam incentivar os usuários a buscarem conexões humanas, mas a dinâmica social é difícil de ser alterada apenas por meio de mensagens.
Lacunas contextuais e culturais
Frases de segurança que parecem apropriadas em uma cultura ou idioma podem não captar as nuances necessárias em outro. Uma localização minuciosa e uma avaliação culturalmente sensível são imprescindíveis; os resultados publicados pela OpenAI ainda não fornecem uma análise completa por idioma ou região.
Exposição legal e ética
Quando falhas raras têm consequências graves, as empresas enfrentam riscos legais e de reputação (como evidenciado pela cobertura da mídia e pelos processos judiciais). A transparência da OpenAI sobre a dimensão do problema e seus esforços para mitigar os danos é um passo importante, mas também atrai a atenção de órgãos reguladores e da justiça.
Então, o GPT-5 agora consegue lidar com problemas de saúde mental?
Resposta curta: **É significativamente melhor em muitas tarefas específicas e mensuráveis.**As métricas publicadas pela OpenAI mostram reduções significativas em respostas indesejadas em conjuntos de testes sobre automutilação, psicose/mania e dependência emocional. Essas são melhorias reais, possibilitadas pela contribuição de especialistas, taxonomias mais claras e avaliação e monitoramento rigorosos. Os números públicos da empresa — altas taxas de conformidade e reduções acentuadas em respostas não conformes em conjuntos selecionados — são a evidência mais forte até o momento de que a colaboração deliberada e multidisciplinar entre engenharia e clínica pode alterar substancialmente o comportamento dos modelos.
Como acessar a API mais recente do GPT-5?
A CometAPI é uma plataforma de API unificada que agrega mais de 500 modelos de IA de provedores líderes — como a série GPT da OpenAI, a Gemini do Google, a Claude da Anthropic, a Midjourney e a Suno, entre outros — em uma interface única e amigável ao desenvolvedor. Ao oferecer autenticação, formatação de solicitações e tratamento de respostas consistentes, a CometAPI simplifica drasticamente a integração de recursos de IA em seus aplicativos. Seja para criar chatbots, geradores de imagens, compositores musicais ou pipelines de análise baseados em dados, a CometAPI permite iterar mais rapidamente, controlar custos e permanecer independente de fornecedores — tudo isso enquanto aproveita os avanços mais recentes em todo o ecossistema de IA.
Os desenvolvedores podem acessar API GPT-5 através do CometAPI, a versão mais recente do modelo está sempre atualizado com o site oficial. Para começar, explore as capacidades do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.
Pronto para ir?→ Inscreva-se no CometAPI hoje mesmo !
Se você quiser saber mais dicas, guias e novidades sobre IA, siga-nos em VK, X e Discord!