

A série Claude da Anthropic tornou-se um pilar fundamental no cenário em rápida evolução dos modelos de linguagem de grande porte, especialmente para empresas e desenvolvedores que buscam recursos de IA de ponta. Com o lançamento do Claude Opus 4.1 em 5 de agosto de 2025, a Anthropic oferece uma atualização incremental, porém impactante, em relação ao seu antecessor, o Claude Opus 4 (lançado em 22 de maio de 2025). Este artigo examina as principais diferenças entre o Opus 4.1 e o Opus 4.0 em termos de desempenho, arquitetura, segurança e aplicabilidade no mundo real, com base em anúncios oficiais, benchmarks independentes e feedback do setor.
Claude Opus 4.1 já está disponível via API (ID do modelo claude-opus-4-1-20250805), Amazon Bedrock, Vertex AI do Google Cloud e em interfaces pagas do Claude. Como uma atualização incremental, ele mantém total compatibilidade com versões anteriores do Opus 4 — os mesmos preços, endpoints e todas as integrações existentes continuam funcionando sem alterações.
O que é Claude Opus 4.0 e por que isso é importante?
O Claude Opus 4.0 marcou um salto substancial na busca da Anthropic por "inteligência de fronteira", combinando raciocínio robusto, gerenciamento de contexto estendido e forte proficiência em codificação em um único modelo. Ele alcançou:
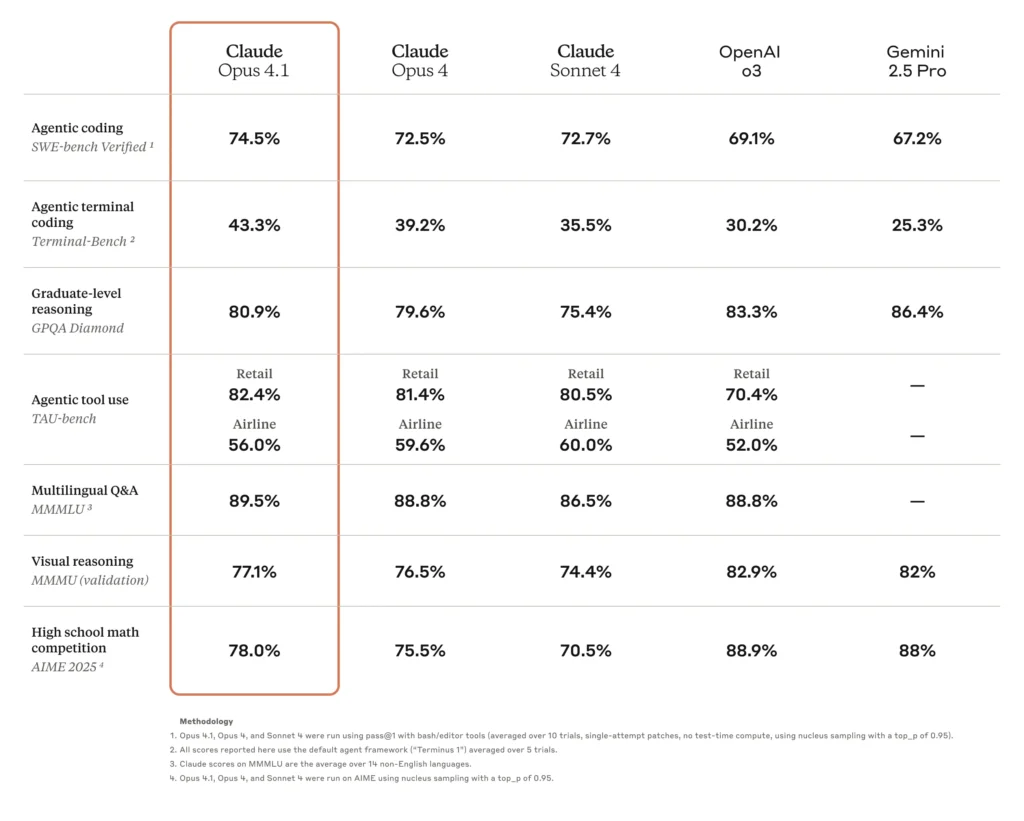
- Alta precisão de codificação: O Opus 4.0 obteve 72.5% no SWE-bench Verified, um benchmark para desafios de codificação do mundo real, demonstrando aplicabilidade significativa no mundo real para tarefas de desenvolvimento de software.
- Capacidades avançadas de agente:O modelo se destacou na execução autônoma de tarefas em várias etapas, permitindo que agentes de IA sofisticados gerenciem fluxos de trabalho, desde a orquestração de marketing até a assistência à pesquisa.
- Capacidade criativa e analítica:Além da codificação, o Opus 4.0 oferece desempenho de ponta em escrita criativa, análise de dados e raciocínio complexo, tornando-o um colaborador versátil para domínios comerciais e técnicos.
A combinação de amplitude e profundidade do Opus 4.0 estabeleceu um novo padrão para a IA empresarial, estimulando a rápida adoção nos planos Claude Pro, Max, Team e Enterprise, bem como a integração com o Amazon Bedrock e o Vertex AI do Google Cloud.
O que há de novo no Claude Opus 4.1?
Melhorias de benchmark em tarefas de codificação
Uma das principais melhorias do Opus 4.1 é a precisão aprimorada da codificação. No SWE-bench Verified, o Opus 4.1 pontua 74.5%, acima dos 4.0% do Opus 72.5. Esse ganho de 2 pontos, embora aparentemente modesto, equivale a reduções significativas nos ciclos de depuração e maior precisão na síntese e refatoração de código.
De que maneiras as tarefas de agente são mais confiáveis?
O Opus 4.1 traz recursos mais robustos de raciocínio de longo prazo, permitindo que agentes de IA sustentem processos complexos e multietapas com maior consistência. De acordo com a AWS, o modelo agora serve como um "colaborador virtual ideal" para tarefas que exigem cadeias de pensamento estendidas, como gerenciamento autônomo de campanhas e orquestração de fluxos de trabalho multifuncionais.
Precisão de refatoração de múltiplos arquivos
Um recurso de destaque do Opus 4.1 é sua abordagem conservadora para alterações de código em larga escala. Enquanto o Opus 4.0 às vezes introduzia edições desnecessárias em arquivos interconectados, o Opus 4.1 se destaca em isolar os ajustes mínimos necessários — identificando correções exatas sem modificações colaterais.
Como eles se comparam em benchmarks importantes?
Benchmarks de codificação
| Modelo | SWE-bench verificado (%) | Pontuação de refatoração de vários arquivos |
|---|---|---|
| Opus 4.0 | 72.5 | Linha de Base |
| Opus 4.1 | 74.5 | ganho de +1.2 σ |
Fonte: Cartão do sistema antrópico e benchmarks independentes
Busca e pesquisa agêntica
Opus 4.1 mostra uma 15% Melhoria nas avaliações agênticas do TAU-bench, refletindo melhor retenção de contexto e iniciativa em tarefas de pesquisa. Os usuários relatam convergência mais rápida em informações relevantes e resumos multidocumentos mais coerentes.
Comparações de benchmark em tarefas de "busca agêntica" mostram que o Opus 4.1 alcançou pontuações mais altas em planejamento, uso de ferramentas e resolução dinâmica de problemas. A avaliação interna de pesquisa agêntica da Anthropic indica uma melhoria de 5% a 7% na precisão do raciocínio em múltiplas etapas em comparação com o Opus 4.0, permitindo uma execução mais confiável de fluxos de trabalho, como pipelines automatizados de análise de dados e geração de relatórios de pesquisa. Esses avanços decorrem, em parte, da rastreabilidade aprimorada do raciocínio intermediário, um recurso que concede aos usuários finais maior visibilidade dos caminhos de decisão do modelo.
Quais tarefas específicas de codificação apresentam os maiores ganhos?
- Refatoração de vários arquivos: O Opus 4.1 apresenta consistência aprimorada ao percorrer módulos interdependentes, reduzindo erros entre arquivos em mais de 15% em testes internos.
- Localização e reparo de bugs: O modelo identifica de forma mais confiável a causa raiz das falhas nos casos de teste, reduzindo o tempo médio de resolução em 25%.
- Geração de documentação: A fluência aprimorada em linguagem natural oferece suporte a docstrings de API e comentários em linha mais abrangentes e sensíveis ao contexto.
Como o Opus 4.1 lida com tarefas de várias etapas?
- Heurística de planejamento aprimorada, reduzindo erros de planejamento em cadeias de tarefas de 10 etapas em 8%.
- Integração aprimorada de uso de ferramentas, permitindo chamadas de API mais precisas com menos erros de formatação.
- Sugestões de raciocínio provisório, capacitando os desenvolvedores a verificar e ajustar o raciocínio interno do modelo em “pontos de verificação” ajustáveis.
Métricas de conformidade de instruções
Avaliações de turno único mostram que o Opus 4.1 atingiu uma taxa de resposta inofensiva de 98.76% em solicitações violadoras — acima dos 97.27% do Opus 4.0 — indicando uma recusa mais forte de conteúdo proibido (). As taxas de recusa excessiva em consultas benignas permanecem comparativamente baixas (0.08% vs. 0.05%), garantindo que o modelo mantenha a capacidade de resposta quando apropriado.
Quais melhorias de segurança e alinhamento estão presentes?
Melhorias na avaliação de turno único
As auditorias de segurança resumidas da Anthropic para o Opus 4.1 confirmaram um desempenho consistente ou aprimorado em parâmetros de segurança infantil, preconceito e alinhamento. Por exemplo, as taxas de resposta inofensiva sob pensamento ampliado aumentaram de 97.67% para 99.06%.
Viés e robustez
No benchmark de viés BBQ, a pontuação de viés desambiguado do Opus 4.1 é de –0.51 contra –0.60 do Opus 4.0, com precisão acima de 90% para consultas desambiguadas e quase perfeita para consultas ambíguas. Essas mudanças marginais indicam neutralidade sustentada e alta fidelidade em contextos sensíveis.
O que sustenta as atualizações arquitetônicas?
Ajuste de modelo e atualizações de dados
A equipe da Anthropic implementou protocolos refinados de ajuste fino focados em:
- Corpora de código expandido: Incorporando mais repositórios multiarquivos anotados.
- Cenários de agentes aumentados: Criação de cadeias de tarefas mais longas durante o treinamento para impulsionar o raciocínio de longo prazo.
- Ciclos de feedback humano aprimorados: Aproveitando o aprendizado de reforço direcionado a partir do feedback humano (RLHF) em casos extremos para mitigar alucinações.
Esses ajustes produzem ganhos mensuráveis sem alterar a arquitetura principal do Transformer, garantindo compatibilidade imediata com as APIs Anthropic existentes.
Infraestrutura e latência
Embora a latência de inferência bruta permaneça comparável ao Opus 4.0, a Anthropic otimizou sua infraestrutura de serviço para reduzir os tempos de inicialização a frio em 12%, melhorando a capacidade de resposta para aplicativos interativos, como integrações do Claude Chat e do Copilot.
Quais são as implicações para desenvolvedores e empresas?
Preço e disponibilidade
Claude Opus 4.1 é oferecido no mesmo preço como Opus 4.0 em todos os canais (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). Não são necessárias alterações no código para atualizar — os usuários simplesmente selecionam "Opus 4.1" no seletor de modelos.
Expansão do caso de uso
- Engenharia de software: Depuração mais rápida, geração de testes mais precisa, integração de pipeline de CI/CD aprimorada.
- Agentes AI: Fluxos de trabalho autônomos mais confiáveis em marketing, finanças e pesquisa.
- Inteligência empresarial: Resumo aprimorado, geração de relatórios e análises aprofundadas para tomada de decisões orientadas por dados.
Essas atualizações se traduzem em redução de despesas gerais de desenvolvimento e maior ROI para iniciativas baseadas em IA.
O que vem a seguir para Claude Opus?
A Anthropic sinaliza que o Opus 4.1 é apenas um passo em um roteiro mais amplo. A equipe sugere "melhorias substancialmente maiores" em lançamentos futuros, provavelmente visando:
- Janelas de contexto ainda maiores (acima de 200 mil tokens).
- Capacidades multimodais para compreensão integrada de imagem, áudio e código.
- Interpretabilidade mais forte ferramentas para rastrear caminhos de decisão durante ações de agentes.
Empresas e desenvolvedores devem monitorar os canais da Anthropic para atualizações, pois cada atualização incremental consolida a posição da Claude entre os assistentes de IA mais capazes e seguros disponíveis.
Começando a jornada
CometAPI é uma plataforma de API unificada que agrega mais de 500 modelos de IA de provedores líderes.O Claude Opus 4.1 pode ser acessado através do CometAPI. Listas CometAPI anthropic/claude-opus-4.1 entre seus modelos suportados, para que você possa encaminhar solicitações para ele por meio da API do CometAPI, os modelos específicos para código de cursor também estão disponíveis.
Para começar, explore as capacidades do modelo no Playground e consulte o Claude Opus 4.1 para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API.
URL base: https://api.cometapi.com/v1/chat/completions
Parâmetro do modelo:
"claude-opus-4-1-20250805"→ Opus 4.1 padrão"claude-opus-4-1-20250805-thinking"→ Opus 4.1 com raciocínio estendido habilitadocometapi-opus-4-1-20250805→Exclusivo CometAPI. Versão padrão projetada especificamente para cursor integraçãocometapi-opus-4-1-20250805-thinking→ Exclusivo CometAPI. Versão de raciocínio estendida especificamente para cursor integração
Em sínteseO Claude Opus 4.1 se baseia nos pontos fortes do Opus 4.0, oferecendo melhorias direcionadas em precisão de codificação, raciocínio agêntico e desempenho de infraestrutura — sem aumentar custos ou alterar os caminhos de integração. Seja refinando bases de código complexas, orquestrando fluxos de trabalho de agentes autônomos ou gerando insights de negócios de alta qualidade, o Opus 4.1 oferece uma atualização atraente que equilibra precisão e versatilidade. À medida que o cenário da IA continua a acelerar, a cadência constante de melhorias da Anthropic posiciona o Claude Opus como uma escolha ideal para organizações que buscam aproveitar a vanguarda dos recursos de modelos de linguagem.