

Google e sua divisão de pesquisa DeepMind impulsionaram silenciosamente (e depois não tão silenciosamente) mais um passo importante no roteiro do Gemini: Gemini 3.1 Pro. O lançamento, disponibilizado nas superfícies voltadas ao consumidor e no CometAPI, é posicionado como uma atualização de desempenho e raciocínio para a família Gemini 3 — prometendo raciocínio prolongado mais robusto, melhor compreensão multimodal e maior escalabilidade para aplicações do mundo real.
O modelo mais novo do Google — o que é o Gemini 3.1 Pro?
Gemini 3.1 Pro é a primeira atualização incremental na família Gemini 3, posicionada como um modelo de raciocínio “mais capaz”, otimizado para tarefas multietapas, multimodais e agênticas. Lançado em visualização pública em meados de fevereiro de 2026 (visualização anunciada em 19–20 de fevereiro de 2026), o modelo é direcionado explicitamente a cenários que exigem cadeias de raciocínio sustentadas, uso de ferramentas e compreensão de contexto longo — por exemplo: síntese de pesquisa em grande escala, agentes de engenharia que coordenam ferramentas e sistemas, e análise multimodal de documentos que misturam texto, imagens, áudio e vídeo.
Em um nível geral, o Gemini 3.1 Pro é descrito por seus desenvolvedores como:
- Nativamente multimodal — capaz de aceitar e raciocinar sobre texto, imagens, áudio e vídeo.
- Construído para contexto longo — suportando janelas de contexto muito grandes, adequadas para bases de código inteiras, dossiês com múltiplos documentos ou transcrições longas.
- Otimizado para raciocínio confiável e fluxos de trabalho agênticos, significando que é ajustado para planejar, chamar ferramentas e verificar saídas em tarefas multietapas.
Por que isso importa agora: organizações e desenvolvedores estão migrando de “bons assistentes conversacionais” para “agentes de suporte à decisão e pesquisa de alto risco” (redação jurídica, síntese de P&D, compreensão multimodal de documentos). Gemini 3.1 Pro é explicitamente projetado para esse corredor — para reduzir alucinações, produzir raciocínio rastreável e integrar-se ao CometAPI tanto para prototipagem quanto para produção.
Quais são os destaques técnicos e os recursos do Gemini 3.1 Pro?
Multimodalidade nativa e janelas de contexto extremas
Gemini 3.1 Pro continua o foco da linhagem Gemini em multimodalidade. Segundo o model card e as notas de produto, o modelo aceita e raciocina sobre texto, imagens, áudio e vídeo no mesmo pipeline — uma capacidade que simplifica fluxos de trabalho em que os tipos de dados são misturados (por exemplo, depoimentos jurídicos com áudio + transcrição + digitalizações). Notavelmente, o modelo suporta uma janela de contexto de 1,000,000 tokens e pode produzir saídas longas (notas publicadas indicam limites de saída em tamanhos muito grandes, apropriados para tarefas de longo formato). Essa escala o torna adequado para casos como analisar repositórios de código inteiros, documentos multicapítulo ou transcrições longas sem segmentação.
“Pensamento dinâmico”: raciocínio aprimorado e planejamento passo a passo
O Google descreve o 3.1 Pro como tendo “pensamento” aprimorado — ou seja, melhor tratamento interno de cadeias de pensamento e seleção dinâmica de estratégias de raciocínio dependendo da complexidade da tarefa. O modelo é ajustado para engajar em planejamento explícito multietapas quando necessário, sendo eficiente em tokens ao fazê-lo. Na prática, isso se traduz em menos alucinações para problemas passo a passo complexos e maior consistência factual em benchmarks de raciocínio multietapas.
Fluxos de trabalho agênticos e uso de ferramentas
Um foco de design importante do 3.1 Pro é o desempenho agêntico: coordenar ferramentas, invocar fundamentação na web ou busca, escrever e executar trechos de código e verificar saídas por meio de passagens secundárias. O Google integrou o 3.1 Pro a produtos orientados a agentes (por exemplo, o ambiente de desenvolvimento Antigravity) para permitir que modelos executem tarefas que envolvem um editor, terminal e navegador — e gravem artefatos como capturas de tela e gravações do navegador para verificar o progresso. Esses recursos visam reduzir a lacuna entre modelos que “apenas dão conselhos” e modelos que realmente executam fluxos de trabalho com múltiplas ferramentas de forma confiável.
Submodos especializados (Deep Research, Deep Think)
O Google pareia o 3.1 Pro com “Deep Research” e faz referência a uma variante “Deep Think” por vir. Esses submodos são direcionados — respectivamente — a tarefas de pesquisa com alto recall e à profundidade máxima de raciocínio (com custo computacional e latência adicionais). Eles existem para atender analistas, pesquisadores e desenvolvedores que precisam de resultados mais deliberados e de maior qualidade, em vez das respostas mais rápidas e baratas.
Como o Gemini 3.1 Pro se sai em benchmarks?
Gemini 3.1 Pro alcança ganhos fortes sobre resultados anteriores do Gemini 3 Pro, muitas vezes liderando em um conjunto amplo de medidas de raciocínio multietapas e multimodal — mas ficando atrás de alguns concorrentes em tarefas especializadas específicas (notavelmente certos conjuntos avançados de codificação ou perguntas de nível especialista). Em resumo: melhorias amplas com pequenas vantagens dos concorrentes em benchmarks de especialidade.
Principais afirmações de benchmarks e números de destaque
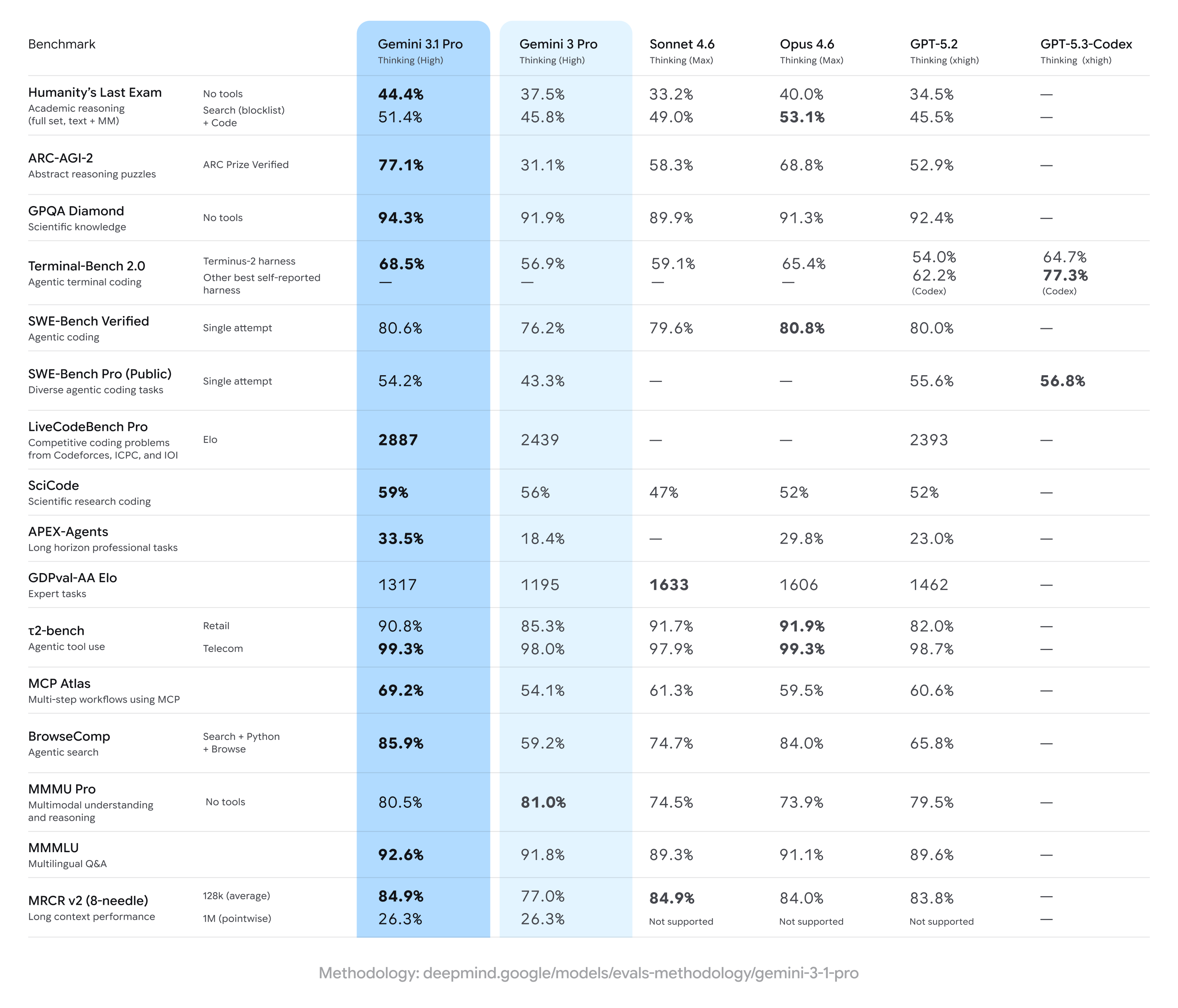
- ARC-AGI-2 (raciocínio abstrato / quebra-cabeças científicos multietapas): Aumentos relatados para o Gemini 3.1 Pro mostram melhora substancial em relação às versões anteriores do Gemini 3 Pro; um conjunto de testes da comunidade indicou uma melhoria de mais de duas vezes no ARC-AGI-2 vs o baseline anterior do Gemini 3 Pro em testes curtos e focados. Pontuações específicas relatadas (testes da comunidade) colocam o Gemini 3.1 Pro em ~77.1% em algumas agregações ao estilo ARC (divulgação pública).
- GPQA Diamond e benchmarks de ciência em nível de pós-graduação: Relatos de dados indicam que o Gemini 3.1 Pro atingiu recordes no GPQA Diamond (um benchmark de perguntas e respostas de ciência em nível de pós-graduação), superando modelos Gemini anteriores e estabelecendo um novo marco para a família em execuções independentes. Esses ganhos refletem o ajuste aprimorado de cadeia de pensamento e raciocínio passo a passo do modelo.
- “Humanity’s Last Exam” com ferramentas habilitadas (raciocínio fundamentado com múltiplas ferramentas): Em comparações diretas com o Claude Opus 4.6, o Claude alcançou 53.1% nesse benchmark complexo com ferramentas habilitadas, enquanto o Gemini 3.1 Pro atingiu 51.4% na mesma rodada de testes — mostrando o Gemini logo atrás, mas não no topo naquele exame multiherramentas específico.
- Benchmarks de codificação e terminal (Terminal-Bench 2.0, SWE-Bench Pro): Benchmarks especializados de codificação mostraram maior divergência. No Terminal-Bench 2.0 com harnesses específicos, variantes GPT-5.3-Codex marcaram cerca de 77.3% vs ~68.5% do Gemini 3.1 Pro nas mesmas comparações. No SWE-Bench Pro com resultados públicos, o Gemini 3.1 Pro marcou ~54.2% vs 56.8% do GPT-5.3-Codex — mais próximo, mas com a família Codex da OpenAI mantendo uma vantagem em tarefas de programação especializadas nessas execuções.
- GDPval-AA Elo (avaliação de tarefas de especialista): Em um ranking agregado estilo Elo para tarefas de especialista, variantes Claude Sonnet/Opus pontuaram mais alto (por exemplo, ~1606–1633 pontos), enquanto um relatório público colocou o Gemini 3.1 Pro em ~1317 pontos nesse mesmo conjunto — indicando espaço para melhoria em certos domínios de especialista estreitos.
Resultados de testes reais e avaliações práticas
Relatos práticos de analistas mostram que o Gemini 3.1 Pro se destaca particularmente em:
- Sumarização de contexto longo e síntese multidocumento, onde a janela de 1M de tokens evita segmentação propensa a artefatos.
- Tarefas de compreensão multimodal onde a ancoragem imagem + texto melhora a extração factual.
- Automação agêntica (por exemplo, coordenar cadeias simples de ferramentas) — com testes no Antigravity demonstrando que a orquestração de tarefas multiagente é viável, com artefatos que registram cada etapa.
Onde o Gemini 3.1 Pro ainda fica atrás (o que dizem os números)
Nenhum modelo é uniformemente o melhor. Comentários independentes e testes da comunidade destacam lacunas específicas:
- Benchmarks de engenharia de software e manutenção de código (SWE-Bench Pro e similares) — o Gemini 3.1 Pro fica atrás de um concorrente (Claude Opus 4.6, da Anthropic) em tarefas que testam habilidades práticas de engenharia de software: refatorações em larga escala, triagem de bugs em bases de código bagunçadas e alguns tipos de reparo automatizado de programas. Em outras palavras, para manutenção de engenharia do dia a dia, modelos especializados ainda mantêm uma vantagem em certos testbeds.
- Microtarefas sensíveis à latência — como o Gemini 3.1 Pro é ajustado para profundidade, tarefas que exigem latência ultrabaixa e alto throughput (por exemplo, microinferência para UIs conversacionais leves) podem ser melhor atendidas por “Flash” ou outras variantes otimizadas na família Gemini.
Qual é a precificação do Gemini 3.1 Pro?
você pode acessar Gemini 3.1 Pro de duas formas — assinatura para consumidor ou API para desenvolvedor — e a precificação é diferente em cada uma.
- Consumidor (app Gemini / Google AI Pro): O acesso ao Gemini 3.1 Pro está incluído na assinatura Google AI Pro, que nos EUA é $19.99 / mês (o Google também oferece o nível inferior “AI Plus” e um nível superior “AI Ultra”). Google.
- Desenvolvedor / API (baseado em tokens): Se você chama os modelos Gemini via a API de desenvolvedor Gemini/AI, a precificação é medida por tokens. Para o preview do Gemini 3.x Pro, os preços publicados para desenvolvedor são aproximadamente: $2.00 por 1M de tokens de entrada e $12.00 por 1M de tokens de saída para a faixa padrão (≤200k prompts) — com camadas superiores (por exemplo, $4/$18 por 1M) para contextos muito grandes. (Veja a tabela de preços da API Gemini para todos os detalhes e preços para lote.)
- Se você usar o Gemini 3.1 Pro via CometAPI:
| Preço Comet (USD / M tokens) | Preço oficial (USD / M tokens) |
|---|---|
| Entrada:$1.6/M; Saída:$9.6/M | Entrada:$2/M; Saída:$12/M |
Preços de assinatura para consumidor (app Gemini)
Para planos de usuário final dentro do app Gemini, o Google estrutura camadas que controlam o acesso a variantes de modelo e recursos extras: Google AI Pro e Google AI Ultra. Os preços variam por mercado e moeda; exemplos publicados mostram Google AI Pro por $19.99/mês (com testes promocionais disponíveis) e preços por moeda em camadas são mostrados na página do produto (incluindo ofertas de teste e tarifas reduzidas de curto prazo). O AI Ultra agrupa acesso superior (por exemplo, acesso prioritário a novas inovações, mais créditos para geração de vídeo) por uma mensalidade maior. Esses preços de plano para consumidor são competitivos com outras assinaturas de IA de alto nível e são posicionados para dar a usuários avançados individuais ou pequenas equipes acesso aos recursos do 3.1 Pro sem integração de API.
Dicas práticas de prompt e uso (o que eu faria)
Use estas para obter resultados confiáveis e repetíveis:
- Planejador de etapas explícito
Padrão de prompt:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Isso aproveita a execução passo a passo mais forte do 3.1 Pro e oferece pontos de verificação. - Saída estruturada com esquemas
Peça JSON com um esquema estrict: true. Como o 3.1 Pro produz saídas longas e aderentes a esquemas com mais confiabilidade, você obterá respostas únicas maiores que podem ser analisadas a jusante. - Sanduíche de checagem de ferramentas
Ao invocar ferramentas externas (APIs, executores de código), faça o modelo produzir: plano → chamada exata da ferramenta (amigável a copiar/colar) → etapas de validação. Em seguida, verifique as etapas de validação fora do modelo antes de continuar. - Cuidado com confiança em etapa única
Mesmo que o modelo escreva código ou comandos com aparência perfeita, execute validação independente (testes, linters, execução em sandbox) — especialmente para ações agênticas/autônomas.
Experiência prática com o Gemini 3.1 Pro
Caso de teste 1: Assistente de pesquisa de contexto longo (NotebookLM / Deep Research)
Objetivo: Avaliar a capacidade do modelo de sintetizar 10–50 documentos longos (por exemplo, relatórios, whitepapers) em um resumo executivo de várias páginas com citações e itens de ação.
Configuração: Forneça um corpus totalizando 200k–800k tokens; peça ao modelo para produzir um resumo de 2–4 páginas com citações explícitas e recomendações de “próximos passos”. Use um template de prompt repetível e meça tempo, uso de tokens (custo) e precisão factual.
Resultados: Sumarização fim a fim mais rápida com menos artefatos decorrentes de segmentação em relação a modelos anteriores, maior fidelidade das citações no resumo e coerência melhorada em escala — ao custo de uso significativo de tokens (então planeje o orçamento). Benchmarks e testes práticos mostram que o Gemini 3.1 Pro se destaca em síntese multidocumento devido à janela de 1M de tokens.
Caso de teste 2: Assistente de codificação agêntico (Antigravity + GitHub Copilot)
Objetivo: Medir a redução no tempo para concluir tarefas de desenvolvedor multietapas (por exemplo, implementar um recurso em vários arquivos, executar testes, corrigir testes com falha).
Configuração: Use Antigravity ou GitHub Copilot em preview com o Gemini 3.1 Pro selecionado. Defina tarefas reprodutíveis (criação de issue → implementar → executar testes), registre etapas e artefatos do agente e compare com uma linha de base apenas humana.
Resultados: Orquestração aprimorada de tarefas multietapas (registro de artefatos, sugestão automática de candidatos a patch), melhor raciocínio multiarquivo do que o Gemini 3 Pro anterior e economia de tempo mensurável em trabalho rotineiro de recursos. Tarefas especializadas de depuração de sistemas de baixo nível podem ainda favorecer modelos especializados focados em código (resultados da comunidade mostram uma lacuna em relação a algumas variantes GPT-Codex em certos benchmarks de terminal).
Caso de teste 3: Revisão multimodal de documentos jurídicos/médicos
Objetivo: Usar o modelo para ingerir um corpus misto (PDFs escaneados, imagens, transcrições de áudio), extrair fatos-chave e produzir uma matriz de risco e ações priorizadas.
Configuração: Forneça um conjunto de dados com imagens digitalizadas e texto OCR, além de áudio de suporte. Meça a precisão na extração de entidades nomeadas, a taxa de falsos positivos e a capacidade do modelo de referenciar artefatos de origem.
resultados: Raciocínio integrado mais forte entre modalidades e saídas mais rastreáveis (capacidade de apontar para a imagem / página / carimbo de data/hora do áudio que sustentam uma afirmação). A janela de contexto longa reduz a necessidade de segmentação e referência cruzada manual. No entanto, em domínios regulamentados, as saídas devem ser validadas por especialistas do domínio e deve-se usar um pipeline de fundamentação/validação.
Primeiras impressões (o que parece diferente)
- Raciocínio passo a passo mais profundo. Tarefas que anteriormente precisavam de múltiplas idas e vindas — por exemplo, síntese multidocumento, matemática/lógica multietapas — tendem a se concluir em menos passagens e com saídas no estilo cadeia de pensamento mais claras (sem expor texto de instruções internas). Este é o destaque enfatizado pelo Google.
- Saídas estruturadas mais longas e de maior qualidade. JSON e automações de formato longo são mais consistentes e frequentemente muito mais extensas (alguns usuários relataram tamanhos de saída muito maiores do que no 3.0). Isso o torna ótimo para trabalhos geradores em que você deseja um único payload grande. Espere lidar com saídas maiores e streaming.
- Manuseio mais eficiente de tokens/contexto. Maior eficiência de tokens e um comportamento mais “fundamentado, consistentemente factual” para cenários com uso de ferramentas. Isso aparece em menos alucinações em consultas factuais curtas.
Análise final: vale a pena adotar o Gemini 3.1 Pro agora?
Gemini 3.1 Pro representa um avanço significativo na família Gemini, com melhorias demonstráveis em benchmarks de raciocínio, codificação e desempenho agêntico — respaldado pelo model card publicado pelo Google e rastreadores independentes que citam grandes saltos em quadros de liderança selecionados. Para equipes que precisam de raciocínio avançado, coordenação de ferramentas agênticas ou capacidades multimodais de longo contexto, o 3.1 Pro é um candidato convincente.
Desenvolvedores podem acessar Gemini 3.1 Pro via CometAPI agora. Para começar, explore as capacidades do modelo no Playground e consulte o guia da API para instruções detalhadas. Antes de acessar, certifique-se de que você fez login no CometAPI e obteve a chave de API. CometAPI oferece um preço muito inferior ao oficial para ajudar você a integrar.
Pronto para começar?→ Inscreva-se no Gemini 3.1 Pro hoje !
Se você quiser saber mais dicas, guias e notícias sobre IA, siga-nos no VK, X e Discord!