

O Google DeepMind anunciou hoje expansões significativas para sua família Gemini 2.5, revelando as versões estáveis Gemini 2.5 Pro e Gemini 2.5 Flash, além de uma prévia do novíssimo modelo Gemini 2.5 Flash-Lite. Essas atualizações refletem o compromisso contínuo do Google em oferecer uma gama de modelos de IA que equilibram custo, velocidade e desempenho para diversas cargas de trabalho.
Versões estáveis: Gemini 2.5 Pro e Flash
Em 17 de junho de 2025, o Google anunciou a disponibilidade geral do Gemini 2.5 Pro e do Gemini 2.5 Flash. A versão Pro oferece o máximo poder de raciocínio e é adequada para tarefas de alta complexidade, como geração avançada de código, análise científica e síntese de dados em larga escala. Em contrapartida, o Gemini 2.5 Flash oferece uma opção intermediária otimizada para usos diários que exigem baixa latência — ideal para chatbots, sumarização e criação de conteúdo em larga escala.
Visão geral: Três modelos da família Gemini -2.5
| Modelo | Status | Pontos fortes | Casos de uso ideais |
|---|---|---|---|
| Gemini 2.5 Flash‑Lite (visualização) | visualização | Mais rápido e mais barato; multimodal; raciocínio controlável; habilitado por ferramentas | Tarefas de alto volume, como chatbots, sumarização, pesquisa |
| Gemini 2.5 Flash | Estável | Balanceado: baixa latência, bom raciocínio, multimodal | Conversas em tempo real, suporte ao cliente |
| Gêmeos 2.5 Pro | Estável | Mais capaz: raciocínio profundo, contexto amplo, multimodal | Pesquisa, codificação complexa, tarefas científicas |
Gemini 2.5 Flash‑Lite: Destaques da pré-visualização
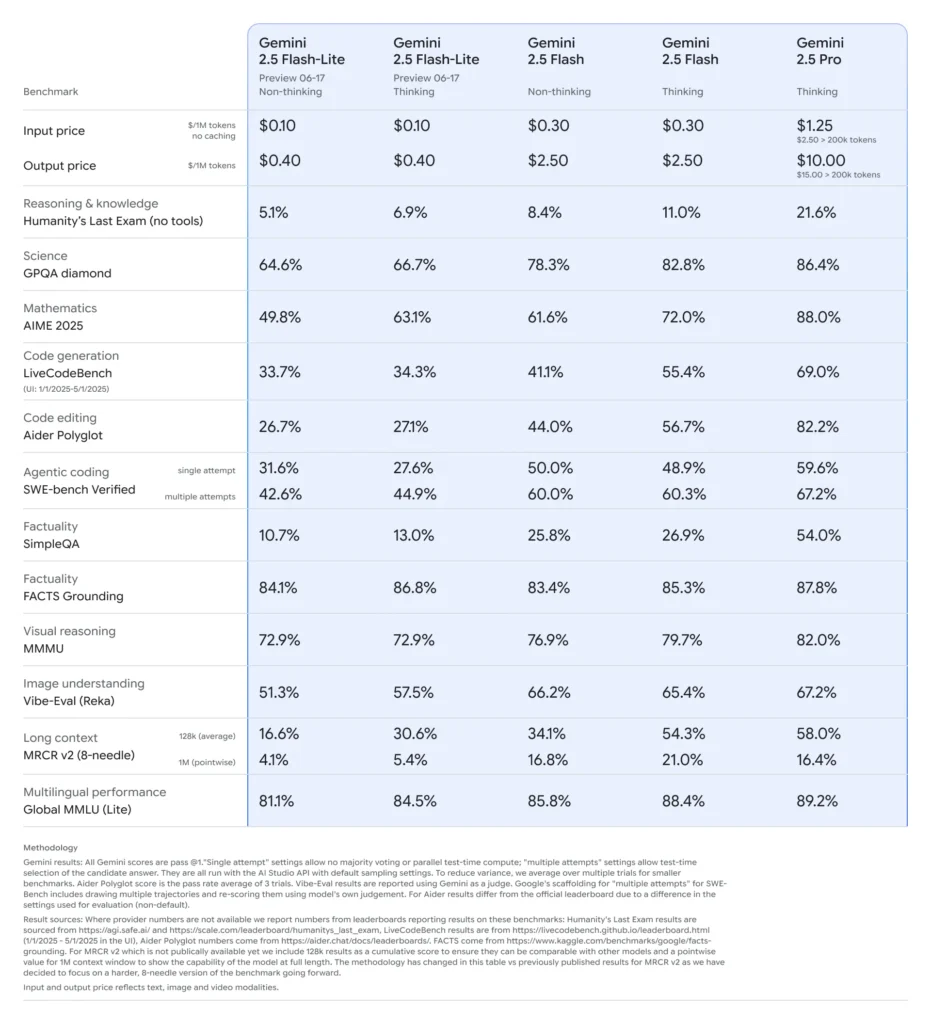
Latência ultrabaixa e economia de custosProjetado para aplicações de alto volume e em tempo real, como tradução, classificação e sumarização. Oferece inferência mais rápida e menor custo por chamada em comparação com o Flash‑Lite 2.0 e a versão completa do Flash.
Desempenho fundamental aprimorado: Supera modelos Flash-Lite anteriores em benchmarks de geração de código, lógica, matemática, raciocínio multimodal e ciência.
Custo e eficiência: Preço do Flash‑Lite (prévia): ~$0.10 por 1M de tokens de entrada e ~$0.40 por 1M de tokens de saída — significativamente mais barato que o Flash ($0.30/$2.50) e o Pro ($1.25/$10).
Capacidades completas do Gemini -2.5:
- Pensamento controlável: Os usuários podem definir “orçamentos de pensamento” (limites de token) para trocar velocidade por profundidade — o Flash‑Lite pode ativar isso conforme necessário.
- Entrada multimodal: Suporta texto, imagem, áudio e vídeo (incluindo clipes de uma hora), com capacidade de analisar gráficos, interface do usuário, cenas e resumos de eventos.
- Integração de ferramentas: Inclui Pesquisa Google, execução de código e uma janela de contexto de um milhão de tokens, correspondendo aos recursos do Flash e do Pro.
Posicionamento na Curva Preço-Desempenho
O Google posiciona a alta velocidade e o baixo custo do Flash-Lite no topo Fronteira de Pareto, o que significa que está entre os modelos mais econômicos e capazes do mundo (). Em avaliações comparativas, O Flash‑Lite representa o melhor valor: inteligente e acessível.
Sobre Flash e Pro
- Gemini 2.5 Flash: Modelo de pensamento estável, de baixa latência e multimodal. Posicionado abaixo do Pro, mas aproximadamente no mesmo nível do GPT-4o em capacidade, com velocidade e custo-benefício superiores ().
- Gêmeos 2.5 Pro: O modelo mais avançado do Google. Reconhecido por lidar com horas de vídeo/áudio, código e matemática complexos e raciocínio em contextos amplos. Também introduz "orçamentos de pensamento" seletivos e qualidade de código aprimorada para servir como uma IA principal estável a longo prazo.
Implantação e preços
- Disponibilidade:Todos os três modelos são acessíveis através de Estúdio de IA do Google, IA do Google Cloud Vertex, e a Aplicativo Gemini .
- Estrutura de custos (Preços do Vertex AI a partir de 16 de junho de 2025):
- Pro: $1.25/1M de entrada, $10/1M de saída (acima de 200K tokens)
- Flash: $0.15/1M de entrada, $3.50/1M de saída no modo “pensamento” — e inclui 1,500 prompts gratuitos diariamente ()
- Flash‑Lite (prévia): ~$0.10/$0.40 por 1M de tokens
Começando a jornada
A CometAPI fornece uma interface REST unificada que agrega centenas de modelos de IA — em um endpoint consistente, com gerenciamento de chaves de API, cotas de uso e painéis de faturamento integrados. Em vez de lidar com várias URLs e credenciais de fornecedores.
Os desenvolvedores podem acessar API Gemini 2.5 Flash-Lite (prévia) através de CometAPI, os modelos mais recentes listados são da data de publicação do artigo. Para começar, explore as capacidades do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.