

Em 3 de março de 2026, o Google apresentou o Gemini 3.1 Flash-Lite, o mais novo membro da família Gemini 3, projetado especificamente como um mecanismo de alta vazão, baixa latência e eficiência de custos para cargas de trabalho de desenvolvedores e empresas. O Google posiciona o Flash-Lite como o modelo “mais rápido e mais econômico” da linha Gemini 3: uma variante leve que visa oferecer interações em streaming, processamento em segundo plano em larga escala e tarefas de produção de alta frequência (por exemplo, tradução, extração, geração de UI e classificação em grande volume) a um preço muito mais baixo do que seus equivalentes Pro.
Abaixo, detalhamos o que é o Flash-Lite.
O que é o Gemini 3.1 Flash-Lite
O Gemini 3.1 Flash-Lite é um membro da família Gemini 3 do Google que intencionalmente troca parte da profundidade de raciocínio de nível mais alto por velocidade e eficiência de custos. Ele é multimodal de forma nativa na linhagem Gemini (capaz de aceitar texto, imagens e outras modalidades como entrada), mas é ajustado e implantado especificamente para oferecer a máxima vazão de tokens por segundo e uma cobrança substancialmente menor por token em cargas de trabalho que exigem inferência rápida e repetida, em vez de profundidade cognitiva máxima. O modelo é descrito como derivado da arquitetura 3.1 Pro, porém otimizado para vazão, latência e custo.
Principais trade-offs de design
O apelido “Lite” sinaliza a ênfase de engenharia do modelo:
- Vazão em detrimento de raciocínio pesado: o Flash-Lite reduz intencionalmente a computação por token para oferecer um tempo até o primeiro token (TTFT) mais rápido e velocidade de saída contínua. Isso o torna ideal para pipelines em que cada solicitação deve ser atendida rapidamente e em escala (por exemplo, filtros de segurança, assistentes em tempo real, geração em alto volume).
- Eficiência de custos para grandes volumes: ao reduzir a computação por token, o modelo pode ser oferecido a preços mais baixos por milhão de tokens, o que reduz o custo marginal em aplicações de grande escala (por exemplo, milhões a bilhões de tokens por mês). A precificação de preview do Google mostra um delta significativo em relação ao nível Pro.
- Qualidade ajustada para tarefas pragmáticas: segundo resumos iniciais de pontuações, o Flash-Lite mantém resultados sólidos em tarefas padrão de classificação, multilíngues e muitas multimodais, mas não é posicionado para superar o Pro nos benchmarks mais complexos de raciocínio multietapas ou geração de código, em que a profundidade é determinante.
Essas cargas de trabalho exigem saída confiável e alta vazão, mas nem sempre precisam das capacidades complexas de raciocínio multietapas dos modelos de ponta.
Principais recursos do Gemini 3.1 Flash-Lite
1. Baixa latência e tempo rápido para o primeiro token
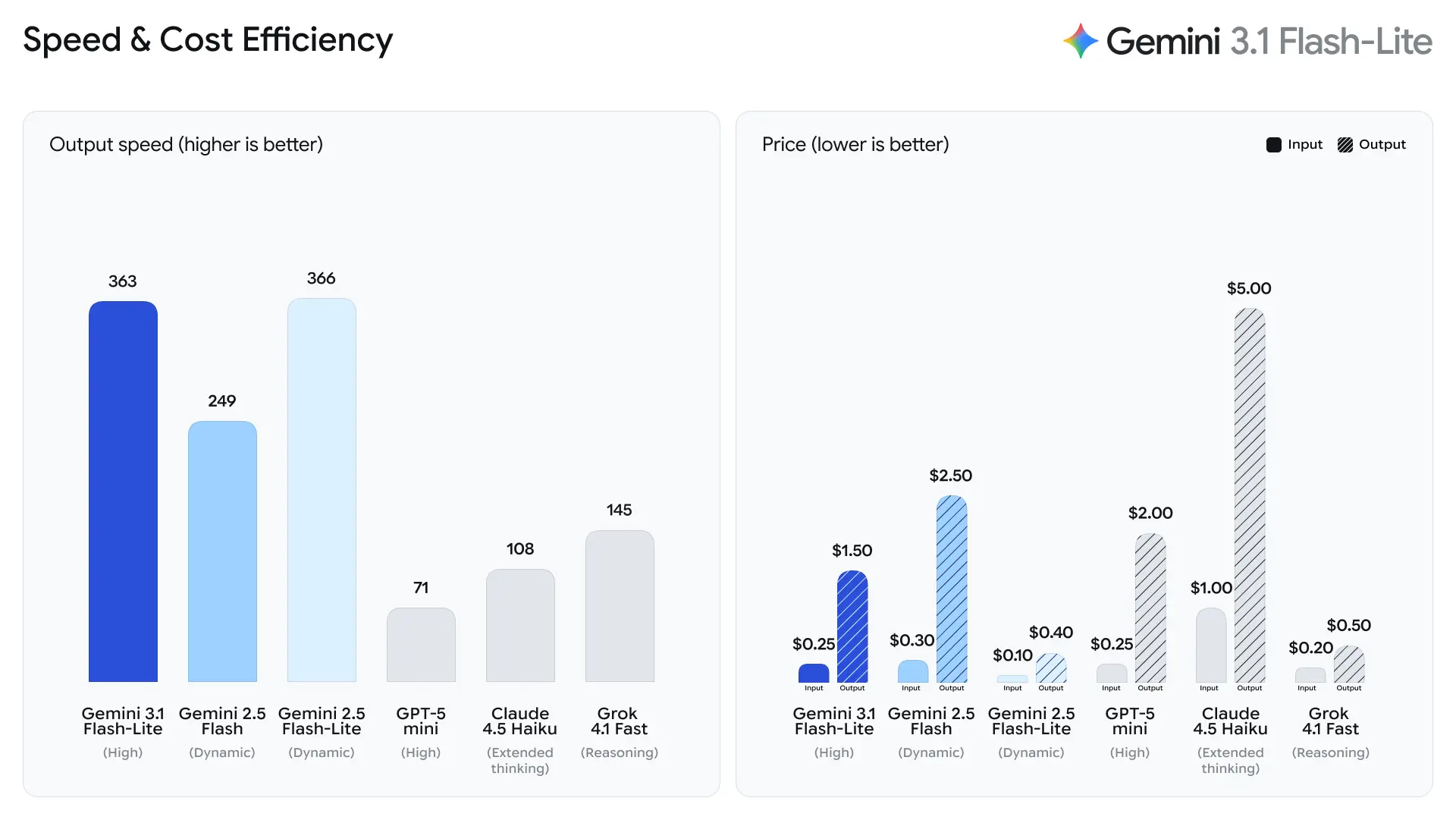
O Google enfatiza o tempo até o primeiro token de resposta como métrica principal para o Flash-Lite. A empresa relata ~2.5× mais rápido no tempo até o primeiro token em comparação ao Gemini 2.5 Flash e até 45% mais rápido na geração de saída — melhorias que impactam diretamente a responsividade percebida pelos usuários finais e os custos de vazão para sistemas de back-end. Esses ganhos tornam o Flash-Lite bem adequado a recursos interativos (por exemplo, chatbots incorporados em apps) e pipelines de alto QPS em que microssegundos importam.
Essa melhoria aprimora significativamente aplicações em tempo real, como:
- IA conversacional
- assistentes de busca com IA
- chatbots interativos
- serviços de tradução ao vivo
A menor latência melhora a experiência do usuário ao reduzir o tempo de espera e permitir interações mais fluidas.
2. Preços de tokens com eficiência de custos
Os custos de inferência de IA são frequentemente calculados por token, tornando a precificação um fator crítico para implantações em larga escala.
O Gemini 3.1 Flash-Lite introduz uma estrutura de preços altamente competitiva:
| Tipo de token | Preço |
|---|---|
| Tokens de entrada | $0.25 por 1M tokens |
| Tokens de saída | $1.50 por 1M tokens |
Isso representa uma redução em relação aos modelos Flash anteriores, tornando o modelo atraente para organizações que executam cargas de trabalho grandes.
Para comparação:
| Modelo | Preço de entrada | Preço de saída |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Essa estratégia de preços permite que desenvolvedores executem IA em escala sem aumentar dramaticamente os custos operacionais.
Se você busca um preço ainda melhor, então o Gemini Flash-Lite oferece 20% de desconto na CometAPI.
3. “Thinking levels” (profundidade de inferência controlável)
O Gemini 3.1 Flash-Lite inclui a capacidade de “thinking levels” — um controle configurável pelo desenvolvedor que instrui o modelo a preferir processamento mais rápido e raso para tarefas triviais e raciocínio mais profundo para tarefas difíceis. Isso é importante na prática porque permite trade-offs dinâmicos de custo/latência por solicitação sem trocar de modelo.
Os desenvolvedores podem configurar a profundidade de raciocínio do modelo para corresponder à complexidade da tarefa. Thinking levels: suporta quatro níveis: Minimal, Low, Medium e High.
Essa abordagem dinâmica permite que as aplicações otimizem o uso de recursos mantendo a qualidade onde importa. A estratégia prática é aproximadamente a seguinte:
- Minimal/Low: adequado para tarefas de alta concorrência, porém logicamente simples, como tradução, classificação e análise de sentimento, priorizando velocidade máxima e custo mínimo.
- Medium: adequado para a maioria das tarefas de produção, equilibrando qualidade e eficiência.
- High: adequado para tarefas que exigem raciocínio profundo, como gerar interfaces de usuário, criar simulações e executar instruções complexas.
4. Capacidade multimodal com pegada leve
Embora o Flash-Lite seja otimizado para velocidade e custo, ele mantém os fundamentos multimodais da linha Gemini 3: pode aceitar entradas de imagem para classificação ou raciocínio multimodal leve quando o caso de uso exigir — mas os desenvolvedores devem esperar que o design econômico favoreça operações multimodais mais curtas e delimitadas em vez de fluxos muito grandes e ricos em imagens. Como outros modelos Gemini, o Gemini 3.1 Flash-Lite oferece entradas multimodais, permitindo aos desenvolvedores processar diferentes tipos de dados.
As entradas compatíveis incluem:
- Texto
- Imagens
- Vídeo
- Áudio
- PDFs
A capacidade do modelo de analisar múltiplos tipos de informação habilita novos casos de uso, como:
- processamento automatizado de documentos
- extração de dados visuais
- sumarização multimídia
Modelos Gemini anteriores também demonstraram fortes capacidades de raciocínio multimodal em benchmarks visuais e de conhecimento.
Benchmarks de desempenho — números reais e o que significam
O anúncio e a documentação de produto do Google apresentam vários pontos de dados de benchmark destinados a ajudar compradores a entender onde o Flash-Lite se posiciona no ecossistema.
Métricas de velocidade voltadas para desenvolvedores
- 2.5× mais rápido no tempo até o primeiro token de resposta vs Gemini 2.5 Flash (comparação interna declarada pelo Google).
- 45% mais rápida a geração de saída vs Gemini 2.5 Flash.
São métricas de engenharia de desempenho, e não métricas de qualidade avaliadas por humanos; elas refletem melhorias na microarquitetura de runtime, batching e otimizações da pilha de inferência que reduzem a latência para respostas curtas. Tempos mais rápidos para o primeiro token reduzem a sensação de atraso em aplicações interativas e aumentam a vazão por servidor, o que pode reduzir o custo total de computação para o mesmo QPS.
Tokens por segundo (t/s) e vazão
Segundo dados de teste da Artificial Analysis, o 3.1 Flash-Lite alcançou uma velocidade de saída de 388.8 tokens por segundo (a mediana para modelos na mesma faixa de preço é de apenas 96.7 tokens/second). Essa velocidade é de nível superior entre os modelos de sua classe.
No entanto, a Artificial Analysis também apontou um problema: a latência do primeiro token (TTFT) do 3.1 Flash-Lite é de 5.18 segundos, o que é relativamente alto para modelos de inferência na mesma faixa de preço (a mediana é 1.82 segundos). Além disso, o modelo gerou 53 milhões de tokens durante o processo de avaliação, o que é relativamente alto em comparação com a média de 20 milhões. Isso significa que, se o seu cenário é muito sensível à latência do primeiro token ou tem requisitos rígidos para concisão da saída, talvez seja necessário otimizar o nível de pensamento e os prompts.
Pontuações de benchmark para raciocínio e factualidade
O Google incluiu comparações entre modelos mostrando o Gemini 3.1 Flash-Lite com desempenho sólido em relação a pares e variantes anteriores do Gemini em tarefas agregadas de raciocínio/factualidade:
- Pontuação Elo do Arena.ai: o Gemini 3.1 Flash-Lite teria alcançado um Elo de 1432 no ranking de avaliação do Arena — um ranking composto de confrontos diretos que mostra desempenho relativo competitivo em cenários de partida direta.
- GPQA Diamond: 86.9% (um indicador da robustez em perguntas e respostas).
- MMMU Pro: 76.8% (uma métrica multimodal/multitarefa usada interna e externamente por alguns laboratórios).
- LiveCodeBench (Habilidade de codificação): 72.0%
- CharXiv Reasoning (Raciocínio gráfico): 73.2%
- Video-MMMU (Compreensão de vídeo): 84.8%
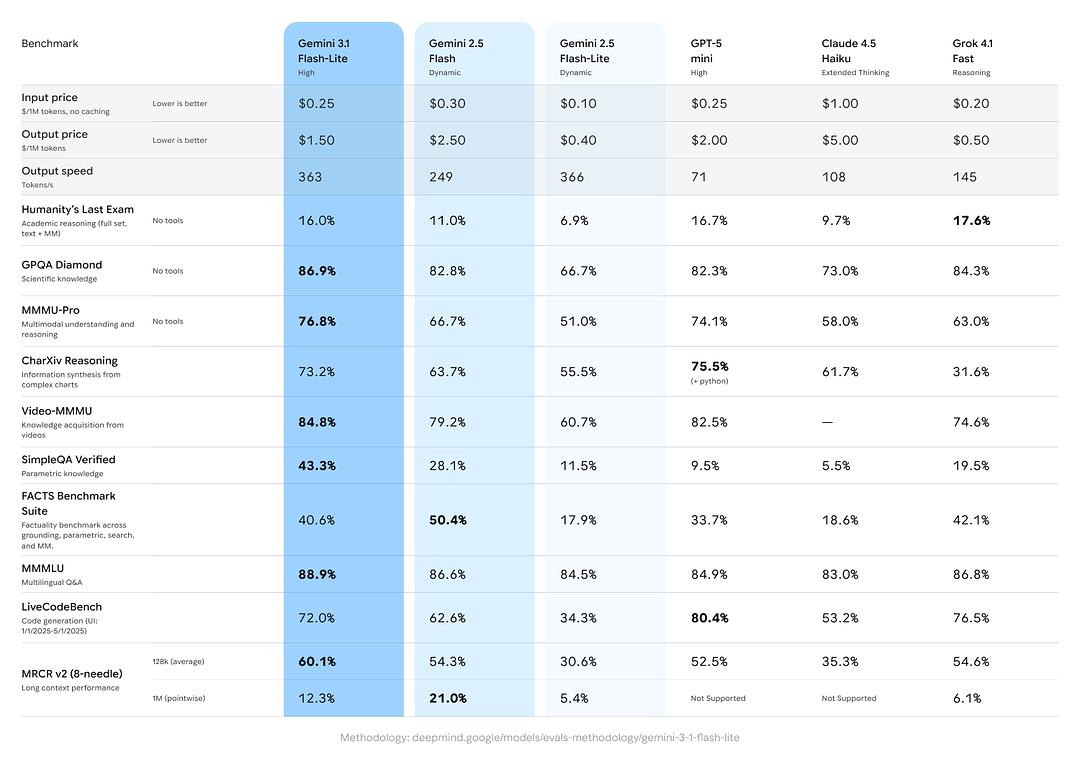
O Gemini 3.1 Flash-Lite supera o antigo Gemini 2.5 Flash em vários desses indicadores enquanto oferece muito melhor relação velocidade/custo.
Casos de uso que se encaixam no Gemini 3.1 Flash-Lite
O Gemini 3.1 Flash-Lite é projetado em torno de um conjunto claro de cargas de trabalho práticas em que alta vazão e menor custo por token são decisivos:
Agentes conversacionais de alta frequência e UI em streaming
Chatbots em tempo real, fluxos de transcrição + tradução ao vivo e UIs colaborativas que exibem respostas parciais conforme o modelo gera, se beneficiam da saída em tokens por streaming e do baixo tempo até o primeiro token do Flash-Lite.
Processamento de dados em lote (RAG, pipelines de transformação)
Ingestão massiva de documentos: extração de entidades, marcação de metadados, classificação e tarefas de tradução executadas sobre milhões de documentos — o Gemini 3.1 Flash-Lite reduz o custo de inferência ao mesmo tempo em que fornece precisão aceitável para saídas com templates ou orientadas por regras.
Computação estilo edge ou em segundo plano
Cargas de trabalho que processam continuamente telemetria recebida ou dados não estruturados (por exemplo, pipelines de classificação para moderação de conteúdo, geração automatizada de relatórios) são bons encaixes porque o Gemini 3.1 Flash-Lite minimiza o custo por unidade.
Ferramentas para desenvolvedores e autocompletar de código em lote
Para recursos como scaffolding multi-arquivo, linting de código em larga escala e geração de templates em escala, as vantagens de velocidade do Gemini 3.1 Flash-Lite reduzem latência e custos para ferramentas de experiência do desenvolvedor em que a profundidade máxima de raciocínio não é necessária.
Comparando o Gemini 3.1 Flash-Lite com outros modelos Gemini e concorrentes
Dentro da família Gemini
- Gemini 3.1 Pro: maior capacidade em raciocínio complexo e planejamento multietapas; significativamente mais caro e mais lento por token, porém melhor para tarefas profundas e nuançadas.
- Gemini 3.1 Flash (não-Lite): mira um meio-termo entre vazão bruta e capacidade — o Flash-Lite otimiza ainda mais a pilha de computação para vazão.
Em comparação com modelos “rápidos” concorrentes
O Gemini 3.1 Flash-Lite supera ou iguala vários modelos fast/mini em muitas métricas de vazão e qualidade — ainda assim, analistas independentes alertam que comparações diretas são sensíveis à metodologia de avaliação e à seleção de datasets. Espere que o Gemini 3.1 Flash-Lite seja altamente competitivo em vazão e custo, permanecendo na faixa intermediária nas métricas de raciocínio mais exigentes.
Conclusão — onde o Flash-Lite se encaixa na pilha de IA
O Gemini 3.1 Flash-Lite é uma oferta projetada deliberadamente: um membro eficiente e focado em vazão da família Gemini 3, que permite às equipes trocar parte da computação por exemplo por melhorias dramáticas em latência e custo. Para empresas e desenvolvedores que constroem pipelines de alto volume — traduções, processamento em lote, UIs em streaming e tarefas agentivas de complexidade moderada — o Flash-Lite representa um mecanismo base sensato. Para organizações que exigem a mais alta fidelidade de raciocínio, os modelos Pro continuam sendo a escolha apropriada.
Se sua carga de trabalho é dominada por muitas inferências curtas e repetíveis ou se você precisa de saída em streaming rápida em larga escala, o Flash-Lite vale um piloto. Se sua carga de trabalho depende de raciocínio profundo multietapas, planeje uma abordagem híbrida: direcione o tráfego de vazão para o Flash-Lite e encaminhe consultas complexas e de alto valor para os modelos Pro.
Os desenvolvedores podem acessar o Gemini 3.1 Flash Lite via CometAPI agora. Para começar, explore as capacidades do modelo no Playground e consulte o guia da API para instruções detalhadas. Antes de acessar, certifique-se de ter feito login na CometAPI e obtido a chave de API. A CometAPI oferece um preço muito inferior ao oficial para ajudar na sua integração.
Pronto para começar? → Inscreva-se no Gemini 3.1 Flash lite hoje!
Se você quiser conhecer mais dicas, guias e notícias sobre IA, siga-nos no VK, no X e no Discord!