

a partir de 15 de dezembro de 2025, os fatos públicos mostram que o Gemini 3 Pro (preview) da Google e o GPT-5.2 da OpenAI estabelecem novas fronteiras em raciocínio, multimodalidade e trabalho com contexto longo — mas seguem rotas de engenharia diferentes (Gemini → MoE esparso + contexto enorme; GPT-5.2 → designs densos/de “roteamento”, compactação e modos de raciocínio x-high) e, portanto, trocam vitórias máximas em benchmarks por previsibilidade de engenharia, ferramentas e ecossistema. Qual é “melhor” depende da sua necessidade principal: aplicações agênticas multimodais com contexto extremo tendem ao Gemini 3 Pro; ferramentas de desenvolvimento empresariais estáveis, custos previsíveis e disponibilidade imediata de API favorecem o GPT-5.2.
O que é o GPT-5.2 e quais são seus principais recursos?
O GPT-5.2 é o lançamento de 11 de dezembro de 2025 da OpenAI na família GPT-5 (variantes: Instant, Thinking, Pro). Ele é posicionado como o modelo mais capaz da empresa para “trabalho profissional de conhecimento” — otimizado para planilhas, apresentações, raciocínio com contexto longo, chamadas de ferramentas, geração de código e tarefas de visão. A OpenAI disponibilizou o GPT-5.2 para usuários pagos do ChatGPT e via API da OpenAI (Responses API / Chat Completions) sob nomes de modelo como gpt-5.2, gpt-5.2-chat-latest e gpt-5.2-pro.
Variantes do modelo e uso pretendido
- gpt-5.2 / GPT-5.2 (Thinking) — melhor para raciocínio complexo e de múltiplas etapas (a variante padrão da família “Thinking” usada na Responses API).
- gpt-5.2-chat-latest / Instant — assistente do dia a dia com menor latência e uso de chat.
- gpt-5.2-pro / Pro — a maior fidelidade/confiabilidade para os problemas mais difíceis (cálculo extra, suporta
reasoning_effort: "xhigh").
Principais recursos técnicos (voltados ao usuário)
- Melhorias em visão e multimodalidade — melhor raciocínio espacial em imagens e compreensão de vídeo aprimorada quando combinada com ferramentas de código (ferramenta Python), além de suporte a ferramentas ao estilo code-interpreter para executar trechos.
- Esforço de raciocínio configurável (
reasoning_effort: none|minimal|low|medium|high|xhigh) para equilibrar latência/custo versus profundidade.xhighé novo no GPT-5.2 (e é suportado no Pro). - Melhoria no tratamento de contexto longo e recursos de compactação para raciocinar sobre centenas de milhares de tokens (a OpenAI reporta métricas fortes em MRCRv2 / contexto longo).
- Chamadas de ferramentas avançadas e fluxos de trabalho agênticos — coordenação mais robusta em múltiplas rodadas, melhor orquestração de ferramentas em uma arquitetura de “mega-agente único” (a OpenAI destaca desempenho em ferramentas no benchmark Tau2).
O que é o Gemini 3 Pro Preview?
O Gemini 3 Pro Preview é o modelo de IA generativa mais avançado da Google, lançado como parte da família Gemini 3 em novembro de 2025. O modelo foi construído com ênfase na compreensão multimodal — capaz de compreender e sintetizar texto, imagens, vídeo e áudio — e traz uma janela de contexto grande (~1 milhão de tokens) para lidar com documentos extensos ou bases de código.
A Google posiciona o Gemini 3 Pro como sendo o estado da arte em profundidade e nuances de raciocínio, e ele serve como o motor central para várias ferramentas de desenvolvedores e empresas, incluindo o Google AI Studio, Vertex AI e plataformas de desenvolvimento agêntico como o Google Antigravity.
Até o momento, o Gemini 3 Pro está em preview — o que significa que funcionalidades e acesso ainda estão se expandindo —, mas o modelo já apresenta pontuações altas em lógica, compreensão multimodal e fluxos de trabalho agênticos.
Principais recursos técnicos e de produto
- Janela de contexto: o Gemini 3 Pro Preview suporta uma janela de contexto de entrada de 1.000.000 tokens (e até 64k tokens de saída), o que é uma grande vantagem prática para ingestão de documentos extremamente extensos, livros ou transcrições de vídeo em uma única solicitação.
- Recursos de API: parâmetro
thinking_level(low/high) para equilibrar latência e profundidade de raciocínio; configuraçõesmedia_resolutionpara controlar fidelidade multimodal e uso de tokens; grounding de busca, contexto por arquivos/URLs, execução de código e function calling são suportados. Assinaturas de pensamento e cache de contexto ajudam a manter o estado em fluxos de múltiplas chamadas. - Modo Deep Think / raciocínio superior: uma opção “Deep Think” faz uma passada extra de raciocínio para impulsionar pontuações em benchmarks difíceis. A Google publica o Deep Think como um caminho de alto desempenho separado para problemas complexos.;
- Suporte multimodal nativo: entradas de texto, imagem, áudio e vídeo com grounding firme para Busca e integrações de produto (pontuações em Video-MMMU e outros benchmarks multimodais são destacadas).
Prévia rápida — GPT-5.2 vs Gemini 3 Pro
Tabela de comparação compacta com os fatos mais importantes (fontes citadas).
| Aspecto | GPT-5.2 (OpenAI) | Gemini 3 Pro (Google / DeepMind) |
|---|---|---|
| Fornecedor / posicionamento | OpenAI — upgrade carro-chefe GPT-5.x focado em trabalho profissional de conhecimento, codificação e fluxos de trabalho agênticos. | Google DeepMind / Google AI — geração carro-chefe Gemini focada em raciocínio multimodal com contexto ultralongo e integração de ferramentas. |
| Principais variantes do modelo | Instant, Thinking, Pro (e alternância automática entre elas). Pro adiciona maior esforço de raciocínio. | Família Gemini 3 incluindo Gemini 3 Pro e modos Deep-Think; foco multimodal/agêntico. |
| Janela de contexto (entrada/saída) | ~400.000 tokens de capacidade total de entrada; até 128.000 tokens de saída/raciocínio (projetado para documentos e bases de código muito extensos). | Até ~1.000.000 tokens de janela de contexto de entrada (1M) com até 64K tokens de saída |
| Pontos fortes / foco | Raciocínio com contexto longo, chamadas de ferramentas agênticas, codificação, tarefas estruturadas de escritório (planilhas, apresentações); atualizações de segurança/system card enfatizam confiabilidade. | Compreensão multimodal em escala, raciocínio + composição de imagens, contexto muito grande + modo de raciocínio “Deep Think”, integrações sólidas de ferramentas/agentes no ecossistema Google. |
| Capacidades multimodais e de imagem | Visão e grounding multimodal aprimorados; ajustado para uso de ferramentas e análise de documentos. | Geração de imagens de alta fidelidade + composição aprimorada por raciocínio, edição de imagens com múltiplas referências e renderização legível de texto. |
| Latência / interatividade | O fornecedor enfatiza inferência mais rápida e maior responsividade de prompt (menor latência que modelos GPT-5.x anteriores); múltiplos níveis (Instant / Thinking / Pro). | A Google enfatiza “Flash”/serving otimizado e velocidades interativas comparáveis em muitos fluxos; o modo Deep Think troca latência por raciocínio mais profundo. |
| Recursos notáveis / diferenciais | Níveis de esforço de raciocínio (medium/high/xhigh), chamadas de ferramentas aprimoradas, geração de código de alta qualidade, alta eficiência de tokens para fluxos de trabalho empresariais. | Contexto de 1M tokens, ingestão multimodal nativa robusta (vídeo/áudio), modo de raciocínio “Deep Think”, integrações estreitas com produtos Google (Docs/Drive/NotebookLM). |
| Melhores usos típicos (resumo) | Análise de documentos longos, fluxos agênticos, projetos de codificação complexos, automação empresarial (planilhas/relatórios). | Projetos multimodais extremamente grandes, fluxos agênticos de longo horizonte que precisam de contexto de 1M tokens, pipelines avançados de imagem + raciocínio. |
Como GPT-5.2 e Gemini 3 Pro se comparam arquiteturalmente?
Arquitetura central
- Benchmarks / avaliações de trabalho real: o GPT-5.2 Thinking alcançou 70,9% de vitórias/empates no GDPval (avaliação de trabalho do conhecimento em 44 ocupações) e grandes ganhos em benchmarks de engenharia e matemática vs. variantes anteriores do GPT-5. Melhorias significativas em codificação (SWE-Bench Pro) e QA científico de domínio (GPQA Diamond).
- Ferramentas e agentes: suporte nativo forte para chamadas de ferramentas, execução em Python e fluxos de trabalho agênticos (busca em documentos, análise de arquivos, agentes de ciência de dados). Velocidade 11x / <1% do custo vs. especialistas humanos para algumas tarefas do GDPval (medida de valor econômico potencial , 70,9% vs. ~38,8% anterior), e mostra ganhos concretos em modelagem de planilhas (ex.: +9,3% em uma tarefa de analista júnior de investment banking vs. GPT-5.1).
- Gemini 3 Pro: Transformer de Mixture-of-Experts esparso (MoE). O modelo ativa um pequeno conjunto de especialistas por token, permitindo capacidade de parâmetros total extremamente alta com custo de computação por token sublinear. A Google publica um model card esclarecendo que o design Sparse MoE é um contribuidor central para o perfil de desempenho aprimorado. Essa arquitetura torna viável elevar muito a capacidade do modelo sem custo de inferência linear.
- GPT-5.2 (OpenAI): a OpenAI continua usando arquiteturas baseadas em Transformer com estratégias de roteamento/compactação na família GPT-5 (um “roteador” aciona modos diferentes — Instant vs. Thinking — e a empresa documenta técnicas de compactação e gerenciamento de tokens para contextos longos). O GPT-5.2 enfatiza treinamento e avaliação para “pensar antes de responder” e compactação para tarefas de longo horizonte em vez de anunciar MoE esparso clássico em escala.
Implicações das arquiteturas
- Trade-offs de latência e custo: modelos MoE como o Gemini 3 Pro podem oferecer maior capacidade de pico por token mantendo o custo de inferência menor para muitas tarefas porque apenas um subconjunto de especialistas é executado. Eles podem, contudo, adicionar complexidade ao serving e ao agendamento (balanceamento de especialistas em cold start, IO). A abordagem do GPT-5.2 (denso/roteado com compactação) favorece latência previsível e ergonomia para desenvolvedores — especialmente quando integrado às ferramentas estabelecidas da OpenAI como Responses, Realtime, Assistants e APIs em lote.
- Escalonando contexto longo: a capacidade de entrada de 1M tokens do Gemini permite fornecer documentos extremamente longos e fluxos multimodais de forma nativa. O contexto combinado do GPT-5.2 de ~400k (entrada+saída) ainda é massivo e cobre a maioria das necessidades empresariais, mas é menor que os 1M do Gemini. Para corpora muito grandes ou transcrições de vídeo de muitas horas, a especificação do Gemini oferece uma vantagem técnica clara.
Ferramentas, agentes e infraestrutura multimodal
- OpenAI: integração profunda para chamadas de ferramentas, execução em Python, modos de raciocínio “Pro” e ecossistemas de agentes pagos (ChatGPT Agents / integrações empresariais de ferramentas). Forte foco em fluxos centrados em código e geração de planilhas/slides como saídas de primeira classe.
- Google / Gemini: grounding integrado ao Google Search (recurso opcional faturado), execução de código, contexto por URL e arquivos, e controles explícitos de resolução de mídia para trocar tokens por fidelidade visual. A API oferece
thinking_levele outros ajustes para calibrar custo/latência/qualidade.
Como os números de benchmark se comparam
Janelas de contexto e manipulação de tokens
- Gemini 3 Pro Preview: 1.000.000 tokens de entrada / 64k tokens de saída (model card do Pro preview). Corte de conhecimento: janeiro de 2025 (Google).
- GPT-5.2: a OpenAI demonstra forte desempenho em contexto longo (pontuações MRCRv2 em tarefas de “agulha” de 4k–256k com faixas >85–95% em muitos cenários) e usa recursos de compactação; exemplos públicos de contexto da OpenAI indicam desempenho robusto mesmo em contextos muito grandes, mas a OpenAI lista janelas específicas por variante (e enfatiza compactação em vez de um único número de 1M). Para uso na API, os nomes de modelos são
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-pro.
Benchmarks de raciocínio e agênticos
- OpenAI (selecionados): Tau2-bench Telecom 98,7% (GPT-5.2 Thinking), ganhos fortes em uso de ferramentas de múltiplas etapas e tarefas agênticas (a OpenAI destaca a colapsação de sistemas multiagente em um “mega-agente”). GPQA Diamond e ARC-AGI mostraram incrementos sobre o GPT-5.1.
- Google (selecionados): Gemini 3 Pro: LMArena 1501 Elo, MMMU-Pro 81%, Video-MMMU 87,6%, GPQA alto e Humanity’s Last Exam; a Google também demonstra planejamento de longo horizonte por meio de exemplos agênticos.
Ferramentas e agentes:
GPT-5.2: suporte nativo forte para chamadas de ferramentas, execução em Python e fluxos de trabalho agênticos (busca em documentos, análise de arquivos, agentes de ciência de dados). Velocidade 11x / <1% do custo vs especialistas humanos para algumas tarefas do GDPval (medida de valor econômico potencial , 70,9% vs. ~38,8% anterior), e mostra ganhos concretos em modelagem de planilhas (por exemplo, +9,3% em uma tarefa de analista júnior de investment banking vs. GPT-5.1).
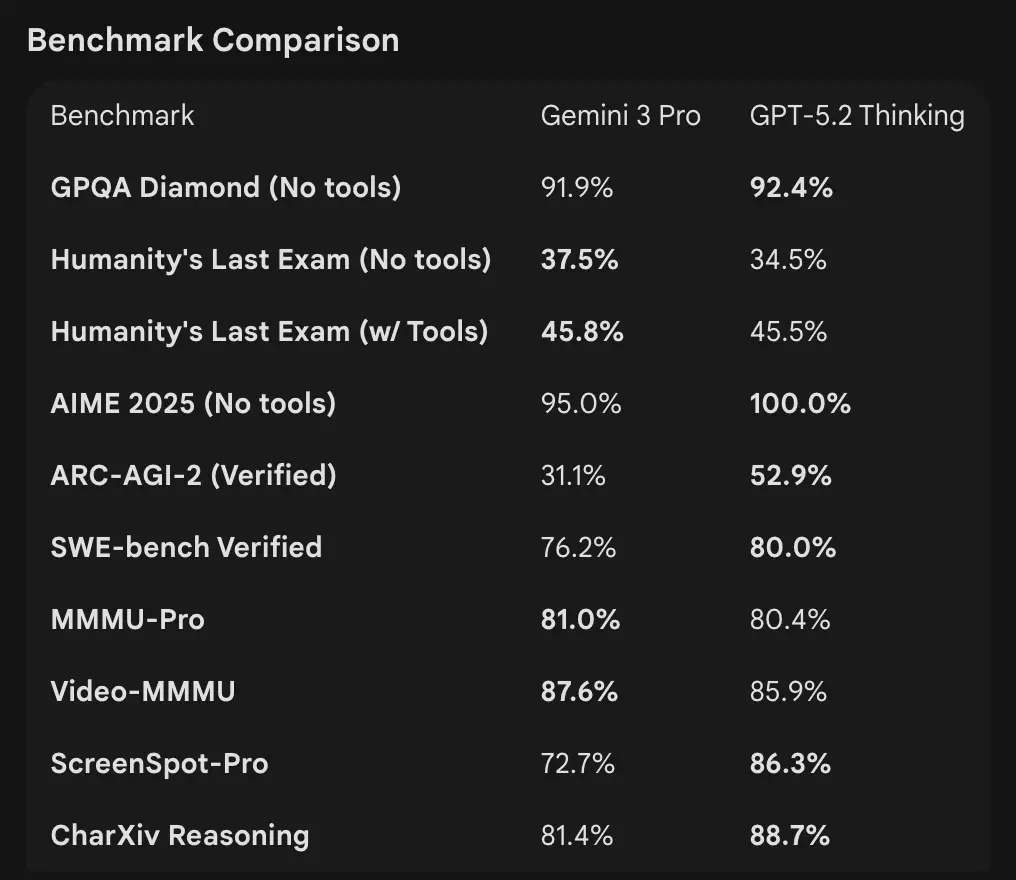
Interpretação: os benchmarks são complementares — a OpenAI enfatiza benchmarks de “trabalho real de conhecimento” (GDPval) mostrando que o GPT-5.2 se destaca em tarefas de produção como planilhas, slides e sequências agênticas longas. A Google enfatiza rankings de “raciocínio bruto” e janelas de contexto extremamente grandes por solicitação. O que importa mais depende da sua carga de trabalho: pipelines empresariais agênticos com documentos longos favorecem o desempenho comprovado do GPT-5.2 no GDPval; ingestão de contexto bruto massivo (por exemplo, corpora inteiros de vídeo / livros completos em um único passo) favorece a janela de entrada de 1M do Gemini.
Como as capacidades multimodais se comparam?
Entradas e saídas
- Gemini 3 Pro Preview: suporta entradas de texto, imagem, vídeo, áudio, PDF e saídas em texto; a Google fornece controles granulares de
media_resolutione um parâmetrothinking_levelpara ajustar custo versus fidelidade em trabalhos multimodais. Limite de tokens de saída 64k; entrada até 1M tokens. - GPT-5.2: suporta fluxos de trabalho ricos de visão e multimodalidade; a OpenAI destaca raciocínio espacial aprimorado (rótulos estimados de bounding de componentes de imagem), compreensão de vídeo (pontuações Video MMMU) e visão habilitada por ferramentas (ferramenta Python em tarefas de visão melhora pontuações). O GPT-5.2 enfatiza que tarefas complexas de visão + código se beneficiam muito quando o suporte a ferramentas (execução de código Python) está habilitado.
Diferenças práticas
Granularidade vs. abrangência: o Gemini expõe um conjunto de ajustes multimodais (media_resolution, thinking_level) voltados a permitir que desenvolvedores sintonizem trade-offs por tipo de mídia. O GPT-5.2 enfatiza uso de ferramentas integradas (executar Python no loop) para combinar visão, código e tarefas de transformação de dados. Se seu caso de uso é análise pesada de vídeo + imagem com contextos extremamente grandes, a alegação de 1M de contexto do Gemini é convincente; se seus fluxos exigem execução de código no loop (transformações de dados, geração de planilhas), as ferramentas de código e a “simpatia” a agentes do GPT-5.2 podem ser mais convenientes.
E quanto ao acesso à API, SDKs e preços?
OpenAI GPT-5.2 (API e preços)
- API:
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-provia Responses API / Chat Completions. SDKs estabelecidos (Python/JS), guias “cookbook” e um ecossistema maduro. - Preços (público): US$ 1,75 / 1M tokens de entrada e US$ 14 / 1M tokens de saída; descontos de cache (90% para entradas em cache) reduzem o custo efetivo para dados repetidos. A OpenAI enfatiza eficiência de tokens (preço por token mais alto, mas menor custo total para atingir um patamar de qualidade).
Gemini 3 Pro Preview (API e preços)
- API:
gemini-3-pro-previewvia Google GenAI SDK e Vertex AI/GenerativeLanguage endpoints. Novos parâmetros (thinking_level,media_resolution) e integração com groundings e ferramentas da Google. - Preços (public preview): aproximadamente US$ 2 / 1M tokens de entrada e US$ 12 / 1M tokens de saída para níveis de preview abaixo de 200k tokens; cobranças adicionais podem ser aplicadas para Search grounding, Maps ou outros serviços Google (faturamento do Search grounding começa em 5 de janeiro de 2026).
Use GPT-5.2 e Gemini 3 via CometAPI
CometAPI é uma API de gateway/aggregator: um único endpoint REST no estilo OpenAI que oferece acesso unificado a centenas de modelos de diversos fornecedores (LLMs, modelos de imagem/vídeo, embeddings etc.). Em vez de integrar muitos SDKs de fornecedores, a CometAPI permite chamar endpoints em formato OpenAI (chat/completions/embeddings/images) conhecidos enquanto alterna modelos ou fornecedores sob o capô.
Desenvolvedores podem aproveitar modelos carro-chefe de duas empresas diferentes simultaneamente via CometAPI without trocar de fornecedor, e os preços da API são mais acessíveis, geralmente com 20% de desconto.
Exemplo: snippets rápidos de API (copiar e colar para testar)
A seguir estão exemplos mínimos que você pode executar. Eles refletem os quickstarts publicados pelos fornecedores (OpenAI Responses API + Google GenAI client). Substitua $OPENAI_API_KEY / $GEMINI_API_KEY por suas chaves.
GPT-5.2 — Python (OpenAI Responses API, reasoning definido para xhigh em problemas profundos)
# Python (requires openai SDK that supports responses API)from openai import OpenAIclient = OpenAI(api_key="YOUR_OPENAI_API_KEY")resp = client.responses.create( model="gpt-5.2-pro", # gpt-5.2 or gpt-5.2-pro input="Summarize this 50k token company report and output a 10-slide presentation outline with speaker notes.", reasoning={"effort": "xhigh"}, # deeper reasoning max_output_tokens=4000)print(resp.output_text) # or inspect resp to get structured outputs / tokens
Notas: reasoning.effort permite equilibrar custo versus profundidade. Use gpt-5.2-chat-latest para estilo de chat Instant. A documentação da OpenAI mostra exemplos para responses.create.
GPT-5.2 — curl (simples)
curl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5.2", "input": "Write a Python function that converts a PDF with tables into a normalized CSV with typed columns.", "reasoning": {"effort":"high"} }'
(Inspecione o JSON para output_text ou saídas estruturadas.)
Gemini 3 Pro Preview — Python (Google GenAI client)
# Python (google genai client) — example from Google docsfrom google import genaiclient = genai.Client(api_key="YOUR_GEMINI_API_KEY")response = client.models.generate_content( model="gemini-3-pro-preview", contents="Find the race condition in this multi-threaded C++ snippet: <paste code here>", config={ "thinkingConfig": {"thinking_level": "high"} })print(response.text)
Notas: thinking_level controla a deliberação interna do modelo; media_resolution pode ser definido para imagens/vídeos. Exemplos REST e JS estão no guia de desenvolvimento do Gemini da Google.;
Gemini 3 Pro — curl (REST)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Explain the race condition in this C++ code: ..."}] }], "generationConfig": {"thinkingConfig": {"thinkingLevel": "high"}} }'
A documentação da Google inclui exemplos multimodais (dados inline de imagem, media_resolution).
Qual modelo é “melhor” — orientações práticas
Não há um “vencedor” universal; em vez disso, escolha com base no caso de uso e nas restrições. Abaixo está uma matriz curta de decisão.
Escolha o GPT-5.2 se:
- Você precisa de integração estreita com ferramentas de execução de código (ecossistema de interpreter/ferramentas da OpenAI) para pipelines programáticos de dados, geração de planilhas ou fluxos agênticos de código. A OpenAI destaca melhorias na ferramenta Python e uso de mega-agente.
- Você prioriza eficiência de tokens segundo alegações do fornecedor e deseja preços por token explícitos e previsíveis da OpenAI com grandes descontos em entradas em cache (ajuda em fluxos em lote/produção).
- Você quer o ecossistema OpenAI (integração com o produto ChatGPT, parcerias Azure/Microsoft e ferramentas em torno da Responses API e Codex).
Escolha o Gemini 3 Pro se:
- Você precisa de entrada multimodal extrema (vídeo + imagens + áudio + PDFs) e quer um único modelo que aceite nativamente todas essas entradas com uma janela de 1.000.000 tokens. A Google comercializa explicitamente isso para vídeos longos, pipelines de documentos grandes + vídeo e casos de uso de Search/AI Mode interativos.&
- Você está construindo no Google Cloud / Vertex AI e quer integração estreita com grounding de busca da Google, provisionamento no Vertex e as APIs do cliente GenAI. Você se beneficiará das integrações de produto da Google (Search AI Mode, AI Studio, ferramentas agênticas Antigravity).
Conclusão: qual é melhor em 2026?
No confronto GPT-5.2 vs. Gemini 3 Pro Preview, a resposta é dependente do contexto:
- O GPT-5.2 lidera em trabalho profissional de conhecimento, profundidade analítica e fluxos estruturados.
- O Gemini 3 Pro Preview se destaca em compreensão multimodal, ecossistemas integrados e tarefas com contexto grande.
Nenhum modelo é universalmente “melhor” — em vez disso, seus pontos fortes atendem a demandas reais diferentes. Adotantes inteligentes devem combinar a escolha do modelo com casos de uso específicos, restrições de orçamento e alinhamento de ecossistema.
O que está claro em 2026 é que a fronteira da IA avançou significativamente, e tanto o GPT-5.2 quanto o Gemini 3 Pro estão expandindo os limites do que sistemas inteligentes podem alcançar na empresa e além.
Se quiser experimentar agora, explore as capacidades do GPT-5.2 e do Gemini 3 Pro da CometAPI no Playground e consulte o guia de API para instruções detalhadas. Antes de acessar, certifique-se de ter feito login na CometAPI e obtido a chave de API. A CometAPI oferece um preço muito inferior ao oficial para ajudar na sua integração.
Pronto para começar?→ Teste grátis do GPT-5.2 e Gemini 3 Pro !
Se você quiser