

A OpenAI publicou uma prévia da pesquisa sobre gpt-oss-safeguard, uma família de modelos de inferência de peso aberto projetada para permitir que os desenvolvedores apliquem sua própria políticas de segurança no momento da inferência. Em vez de enviar um classificador fixo ou um mecanismo de moderação de caixa preta, os novos modelos são ajustados para motivo de uma política fornecida pelo desenvolvedor, emitem uma cadeia de raciocínio (CoT) explicando seu raciocínio e produzem resultados de classificação estruturados. Anunciado como uma prévia de pesquisa, o gpt-oss-safeguard é apresentado como um par de modelos de raciocínio—gpt-oss-safeguard-120b e gpt-oss-safeguard-20b—Aprimorado a partir da família gpt-oss e projetado explicitamente para executar tarefas de classificação de segurança e aplicação de políticas durante a inferência.
O que é gpt-oss-safeguard?
gpt-oss-safeguard é um par de modelos de raciocínio de peso aberto, baseados apenas em texto, que foram pós-treinados a partir da família gpt-oss para **Interpretar uma política escrita em linguagem natural e rotular o texto de acordo com essa política.**A característica distintiva é que a política é fornecido no momento da inferência (política como entrada), não incorporada nos pesos estáticos do classificador. Os modelos são projetados principalmente para tarefas de classificação de segurança — por exemplo, moderação de múltiplas políticas, classificação de conteúdo em múltiplos regimes regulatórios ou verificações de conformidade com políticas.
Por isso é importante
Os sistemas de moderação tradicionais geralmente dependem de (a) conjuntos de regras fixas mapeados para classificadores treinados em exemplos rotulados ou (b) heurísticas/expressões regulares para detecção de palavras-chave. O gpt-oss-safeguard busca mudar esse paradigma: em vez de re-treinar os classificadores sempre que uma política muda, você fornece um texto de política (por exemplo, a política de uso aceitável da sua empresa, os termos de serviço da plataforma ou uma diretriz de um órgão regulador), e o modelo analisa se um determinado conteúdo viola essa política. Isso promete agilidade (alterações de política sem necessidade de re-treinamento) e interpretabilidade (o modelo apresenta sua linha de raciocínio).
Essa é a sua filosofia central: "Substituir a memorização pelo raciocínio e o palpite pela explicação."
Isso representa um novo estágio na segurança de conteúdo, passando da "aprendizagem passiva de regras" para a "compreensão ativa de regras".
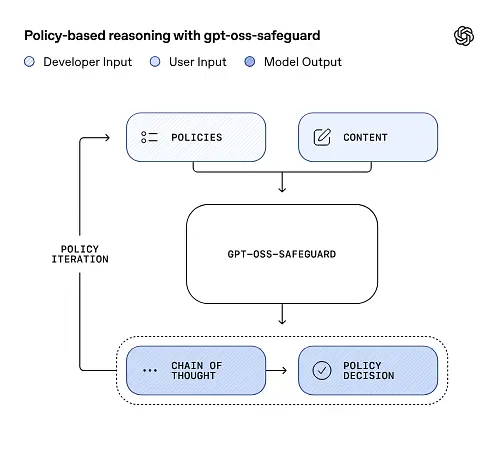
O gpt-oss-safeguard pode ler diretamente as políticas de segurança definidas pelos desenvolvedores e seguir essas políticas para fazer julgamentos durante a inferência.
Como funciona o gpt-oss-safeguard?
Raciocínio com base em políticas como entrada
No momento da inferência, você fornece duas coisas: o texto da política e conteúdo do candidato para ser rotulado. O modelo trata a política como a instrução principal e, em seguida, realiza um raciocínio passo a passo para determinar se o conteúdo é permitido, proibido ou requer etapas adicionais de moderação. Na inferência, o modelo:
- Produz um resultado estruturado que inclui uma conclusão (rótulo, categoria, confiança) e um raciocínio legível por humanos explicando por que essa conclusão foi alcançada.
- ingere a política e o conteúdo a ser classificado,
- internamente, analisa as cláusulas da política usando etapas semelhantes a uma linha de raciocínio, e
Por exemplo:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
A resposta será:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Cadeia de pensamento (CoT) e resultados estruturados
O gpt-oss-safeguard pode emitir um rastreamento CoT completo como parte de cada inferência. O CoT foi projetado para ser inspecionável — as equipes de conformidade podem ler por que o modelo chegou a uma conclusão, e os engenheiros podem usar o rastreamento para diagnosticar ambiguidades de políticas ou modos de falha do modelo. O modelo também oferece suporte a resultados estruturados—por exemplo, um JSON que contém um veredicto, as seções da política violadas, a pontuação de gravidade e as ações corretivas sugeridas—o que facilita a integração em fluxos de moderação.
Níveis de "esforço de raciocínio" ajustáveis
Para equilibrar latência, custo e abrangência, os modelos suportam esforço de raciocínio configurável: baixo / médio / altoUm esforço maior aprofunda a linha de raciocínio e geralmente resulta em inferências mais robustas, porém mais lentas e custosas. Isso permite que os desenvolvedores priorizem as cargas de trabalho — usando baixo esforço para conteúdo rotineiro e alto esforço para casos extremos ou conteúdo de alto risco.
Qual é a estrutura do modelo e quais versões existem?
Modelo de família e linhagem
gpt-oss-safeguard são pós-treinamento variantes das versões anteriores da OpenAI gpt-oss modelos abertos. A família Safeguard atualmente inclui dois tamanhos disponíveis:
- gpt-oss-safeguard-120b — um modelo de 120 bilhões de parâmetros projetado para tarefas de raciocínio de alta precisão, que ainda funciona em uma única GPU de 80 GB em tempos de execução otimizados.
- gpt-oss-safeguard-20b — um modelo de 20 bilhões de parâmetros otimizado para inferência de baixo custo e ambientes de borda ou locais (pode ser executado em dispositivos com 16 GB de VRAM em algumas configurações).
Notas sobre a arquitetura e características de tempo de execução (o que esperar)
- Parâmetros ativos por token: A arquitetura subjacente do gpt-oss utiliza técnicas que reduzem o número de parâmetros ativados por token (uma combinação de atenção densa e esparsa / design de estilo "mistura de especialistas" no gpt-oss original).
- Na prática, a classe 120B cabe em aceleradores grandes individuais, e a classe 20B foi projetada para operar em configurações de 16 GB de VRAM em tempos de execução otimizados.
Os modelos de salvaguarda eram não treinados com dados adicionais de biologia ou cibersegurançae que as análises dos piores cenários de uso indevido realizadas para a versão gpt-oss se aplicam, em linhas gerais, às variantes de salvaguarda. Os modelos são destinados à classificação, e não à geração de conteúdo para usuários finais.
Quais são os objetivos do gpt-oss-safeguard?
Objetivos
- Flexibilidade de política: Permitir que os desenvolvedores definam qualquer política em linguagem natural e que o modelo a aplique sem a necessidade de uma coleção personalizada de rótulos.
- Explicabilidade: Expor o raciocínio para que as decisões possam ser auditadas e as políticas aprimoradas.
- Acessibilidade: Oferecer uma alternativa de peso aberto para que as organizações possam executar o raciocínio de segurança localmente e inspecionar os componentes internos do modelo.
Comparação com classificadores clássicos
Prós versus classificadores tradicionais
- Não há necessidade de requalificação para alterações nas políticas: Se a sua política de moderação mudar, atualize o documento da política em vez de coletar rótulos e treinar um classificador novamente.
- Raciocínio mais rico: Os resultados do CoT podem revelar interações políticas sutis e fornecer justificativas narrativas úteis para revisores humanos.
- Personalização: Um único modelo pode aplicar diversas políticas diferentes simultaneamente durante a inferência.
Contras em relação aos classificadores tradicionais
- Limites de desempenho para algumas tarefas: A avaliação da OpenAI observa que Classificadores de alta qualidade, treinados com dezenas de milhares de exemplos rotulados, podem superar o gpt-oss-safeguard. em tarefas de classificação especializadas. Quando o objetivo é a precisão bruta da classificação e você tem dados rotulados, um classificador dedicado treinado nessa distribuição pode ser melhor.
- Latência e custo: O raciocínio com CoT exige muito poder computacional e é mais lento do que um classificador leve; isso pode tornar os pipelines baseados puramente em salvaguardas dispendiosos em grande escala.
Resumindo: gpt-oss-safeguard é mais bem utilizado onde agilidade e auditabilidade das políticas são prioridades ou quando os dados rotulados são escassos — e como um componente complementar em pipelines híbridos, não necessariamente como um substituto direto para um classificador otimizado para escala.
Qual foi o desempenho do gpt-oss-safeguard nas avaliações da OpenAI?
A OpenAI publicou os resultados iniciais em um relatório técnico de 10 páginas, que resume as avaliações internas e externas. Principais conclusões (métricas selecionadas e essenciais):
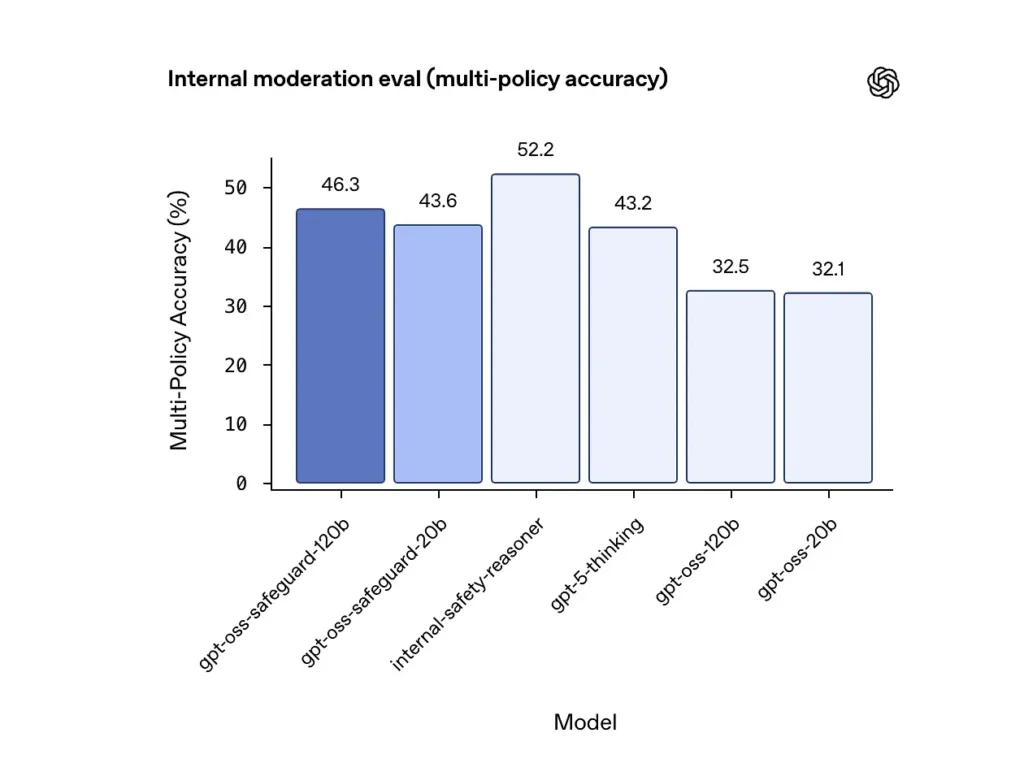
Precisão de múltiplas políticas (avaliação interna)
A OpenAI avaliou a precisão de múltiplas políticas fornecendo ao modelo múltiplo políticas simultaneamente e considerando uma previsão como correta apenas se ela correspondesse aos rótulos dourados em todas as áreas. todos os Políticas. Resultados:
- gpt-oss-safeguard-120b: 46.3% precisão de múltiplas políticas
- gpt-oss-safeguard-20b: 43.6%
- Para comparação: gpt-5-pensamento: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
O conjunto interno "safety-reasoner" da OpenAI obteve uma pontuação de 52.2% no mesmo teste. Esses números mostram que os modelos de salvaguarda superam substancialmente seus modelos base gpt-oss na tarefa de múltiplas políticas, e até mesmo ultrapassaram a linha de base gpt-5-thinking, de maior porte, na métrica interna de múltiplas políticas.
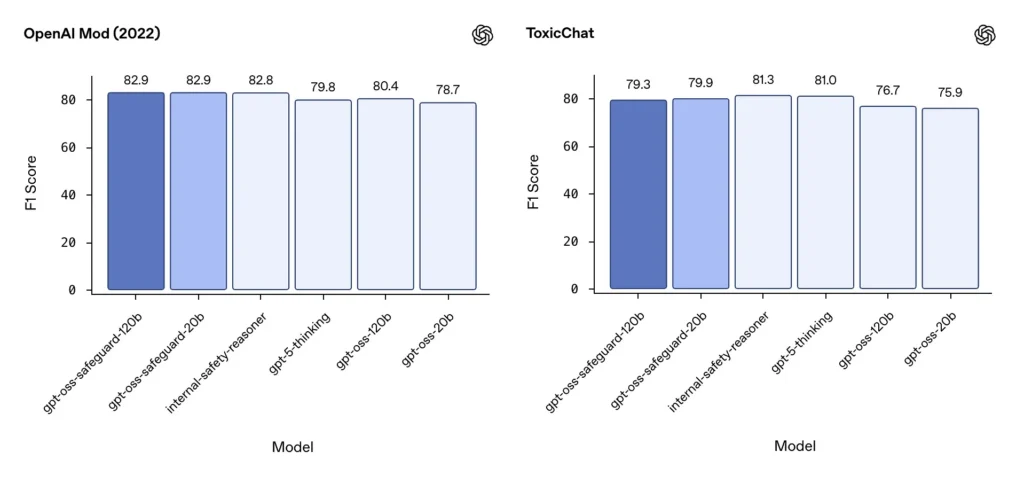
Moderação F1 (benchmarks externos)
Nos conjuntos de dados de moderação de 2022 da OpenAI e no benchmark público ToxicChat, os modelos gpt-oss-safeguard alcançaram pontuações F1 sólidas:
- OpenAI Mod (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Esses resultados colocam o gpt-oss-safeguard próximo ou ligeiramente atrás de sistemas internos especializados da OpenAI em alguns benchmarks, e geralmente à frente de suas contrapartes gpt-oss não otimizadas.
Limitações observadas
A OpenAI destaca duas limitações práticas:
- Classificadores treinados em grandes conjuntos de dados rotulados e específicos para a tarefa ainda podem superar os modelos de salvaguarda. quando a precisão da classificação é o único objetivo.
- Custos de computação e latência: O raciocínio CoT aumenta o tempo de inferência e o consumo de computação, o que complica a escalabilidade para tráfego em nível de plataforma, a menos que seja combinado com classificadores de triagem e pipelines assíncronos.
Paridade multilíngue
O gpt-oss-safeguard apresenta desempenho equivalente aos modelos gpt-oss subjacentes em diversos idiomas em testes do tipo MMMLU, indicando que as variantes de proteção otimizadas mantêm uma ampla capacidade de raciocínio.
Como as equipes podem acessar e implantar o gpt-oss-safeguard?
A OpenAI fornece os pesos sob a licença Apache 2.0 e disponibiliza os modelos para download (Hugging Face). Como o gpt-oss-safeguard é um modelo de pesos abertos, a implantação local e autogerenciada é recomendada (para privacidade e personalização).
- Baixar pesos do modelo (da OpenAI / Hugging Face) e hospede-os em seus próprios servidores ou VMs na nuvem. A licença Apache 2.0 permite modificação e uso comercial.
- RuntimeUtilize ambientes de execução de inferência padrão que suportem modelos Transformer de grande porte (ONNX Runtime, Triton ou ambientes de execução otimizados de fornecedores). Ambientes de execução da comunidade, como Ollama e LM Studio, já estão adicionando suporte para famílias gpt-oss.
- HardwareA política de 120 bits geralmente exige GPUs com muita memória (por exemplo, A100/H100 de 80 GB ou particionamento multi-GPU), enquanto a de 20 bits pode ser executada de forma mais econômica e possui opções otimizadas para configurações com 16 GB de VRAM. Planeje a capacidade considerando o pico de throughput e os custos de avaliação de múltiplas políticas.
Ambientes de execução gerenciados e de terceiros
Se executar seu próprio hardware for inviável, CometAPI O suporte para modelos gpt-oss está sendo rapidamente ampliado. Essas plataformas podem oferecer escalabilidade mais fácil, mas reintroduzem as desvantagens da exposição de dados a terceiros. Avalie a privacidade, os SLAs e os controles de acesso antes de escolher ambientes de execução gerenciados.
Estratégias de moderação eficazes com gpt-oss-safeguard
1) Utilize um pipeline híbrido (triagem → análise → julgamento)
- Camada de triagem: Classificadores (ou regras) pequenos e rápidos filtram os casos triviais. Isso reduz a carga no modelo de salvaguarda, que é dispendioso.
- Camada de proteção: Execute o gpt-oss-safeguard para verificações ambíguas, de alto risco ou com múltiplas políticas, onde as nuances da política são importantes.
- Julgamento humano: Escalar casos extremos e recursos, armazenando o CoT como evidência para transparência. Esse design híbrido equilibra produtividade e precisão.
2) Engenharia de políticas (não engenharia de prontidão)
- Trate as políticas como artefatos de software: versione-as, teste-as em relação a conjuntos de dados e mantenha-as explícitas e hierárquicas.
- Elabore políticas com exemplos e contraexemplos. Quando possível, inclua instruções que esclareçam ambiguidades (por exemplo, "Se a intenção do usuário for claramente exploratória e histórica, rotule como X; se a intenção for operacional e em tempo real, rotule como Y").
3) Configurar o esforço de raciocínio dinamicamente
- Uso baixo esforço para processamento em massa e alto esforço Para conteúdo sinalizado, recursos ou verticais de alto impacto (jurídico, médico, financeiro).
- Ajuste os limites com base no feedback de revisões humanas para encontrar o equilíbrio ideal entre custo e qualidade.
4) Valide o CoT e fique atento a raciocínios alucinatórios.
A Cadeia de Pensamento (CoT) é valiosa, mas pode gerar alucinações: o resultado é uma justificativa gerada por um modelo, não a verdade fundamental. Audite os resultados da CoT rotineiramente; utilize detectores para identificar citações alucinadas ou raciocínios inconsistentes. A OpenAI documenta as cadeias de pensamento alucinadas como um desafio observado e sugere estratégias de mitigação.
5) Criar conjuntos de dados a partir da operação do sistema
Decisões de modelos logarítmicos e correções humanas são utilizadas para criar conjuntos de dados rotulados que podem aprimorar classificadores de triagem ou orientar a reformulação de políticas. Com o tempo, um conjunto de dados rotulado pequeno e de alta qualidade, aliado a um classificador eficiente, geralmente reduz a dependência da inferência completa de CoT para conteúdo de rotina.
6) Monitorar computação e custos; empregar fluxos assíncronos
Para aplicações de baixa latência voltadas para o consumidor, considere verificações de segurança assíncronas com uma experiência do usuário conservadora de curto prazo (por exemplo, ocultar temporariamente o conteúdo enquanto aguarda revisão) em vez de realizar verificações de latência complexas de forma síncrona. A OpenAI observa que o Safety Reasoner usa fluxos assíncronos internamente para gerenciar a latência em serviços de produção.
7) Considere a privacidade e o local de implantação
Como os pesos são abertos, você pode executar a inferência totalmente localmente para cumprir as normas de governança de dados rigorosas ou reduzir a exposição a APIs de terceiros — algo valioso para setores regulamentados.
Conclusão:
gpt-oss-safeguard é uma ferramenta prática, transparente e flexível para raciocínio de segurança orientado por políticasEla brilha quando você precisa. decisões auditáveis vinculadas a políticas explícitas, quando suas políticas mudam com frequência ou quando você deseja manter verificações de segurança nas instalações. É não Uma solução milagrosa que substituirá automaticamente classificadores especializados de alto volume — as próprias avaliações da OpenAI mostram que classificadores dedicados, treinados em grandes corpora rotulados, podem superar esses modelos em precisão bruta para tarefas específicas. Em vez disso, considere o gpt-oss-safeguard como um componente estratégico: o mecanismo de raciocínio explicável no centro de uma arquitetura de segurança em camadas (triagem rápida → raciocínio explicável → supervisão humana).
Começando a jornada
A CometAPI é uma plataforma de API unificada que agrega mais de 500 modelos de IA de provedores líderes — como a série GPT da OpenAI, a Gemini do Google, a Claude da Anthropic, a Midjourney e a Suno, entre outros — em uma interface única e amigável ao desenvolvedor. Ao oferecer autenticação, formatação de solicitações e tratamento de respostas consistentes, a CometAPI simplifica drasticamente a integração de recursos de IA em seus aplicativos. Seja para criar chatbots, geradores de imagens, compositores musicais ou pipelines de análise baseados em dados, a CometAPI permite iterar mais rapidamente, controlar custos e permanecer independente de fornecedores — tudo isso enquanto aproveita os avanços mais recentes em todo o ecossistema de IA.
A integração mais recente, gpt-oss-safeguard, estará disponível em breve no CometAPI, então fique atento! Enquanto finalizamos o upload do modelo gpt-oss-safeguard, os desenvolvedores podem acessar API GPT-OSS-20B e API GPT-OSS-120B através do CometAPI, a versão mais recente do modelo está sempre atualizado com o site oficial. Para começar, explore as capacidades do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.
Pronto para ir?→ Inscreva-se no CometAPI hoje mesmo !
Se você quiser saber mais dicas, guias e novidades sobre IA, siga-nos em VK, X e Discord!