

xAI anunciado Grok 4 Fast, uma variante otimizada em termos de custo de sua família Grok que, segundo a empresa, oferece desempenho de referência próximo ao de um carro-chefe, ao mesmo tempo em que reduz o preço para atingir esse desempenho 98% comparado com o Grok 4. O novo modelo foi projetado para pesquisa de alto rendimento e uso de ferramentas de agente, e inclui uma janela de contexto de 2 milhões de tokens e variantes separadas de “raciocínio” e “não raciocínio” para permitir que os desenvolvedores ajustem a computação às suas necessidades.
Principais recursos e benefícios
Modelo de inferência custo-efetivo: O Grok 4 Fast é construído a partir da família Grok 4 com foco na eficiência do token e no uso de ferramentas em tempo real. O xAI relata que o modelo requer aproximadamente 40% menos tokens “pensantes” Em média. A Análise Artificial — que monitora latência, velocidade de saída e preço/desempenho em muitos modelos públicos — coloca o Grok 4 Fast em posição de destaque em sua relação inteligência versus custo e confirma as rápidas velocidades de saída do modelo e a relação custo-benefício favorável nos testes iniciais.
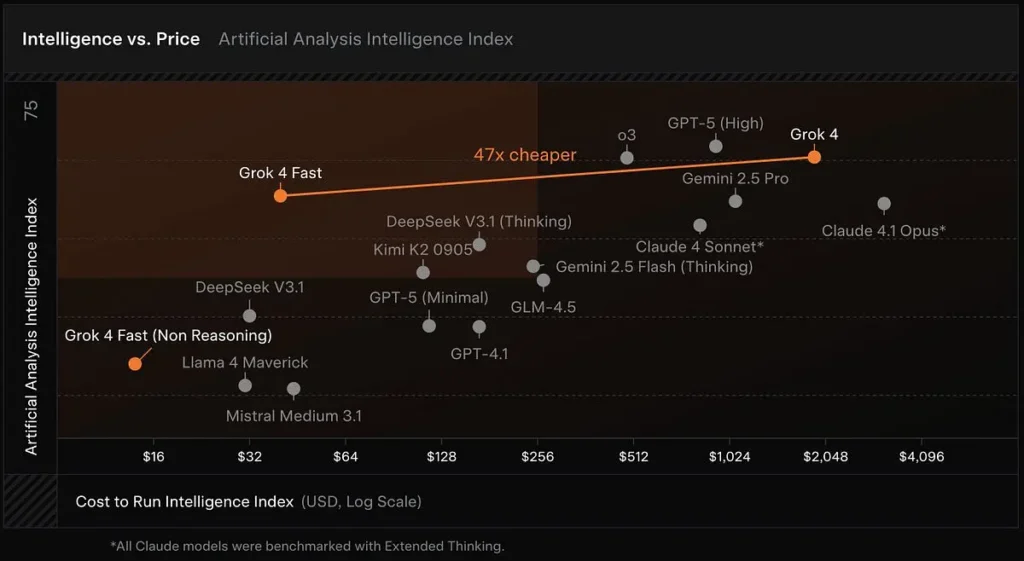
Grandes janelas de contexto: O Grok 4 Fast foi projetado para pesquisa de alto rendimento e uso de ferramentas de agente, e inclui uma janela de contexto de 2 milhões de tokens e variantes separadas de "raciocínio" e "não raciocínio" para permitir que os desenvolvedores ajustem a computação às suas necessidades.
Capacidades de uso de ferramentas nativas: O Grok 4 Fast fornece “recursos de pesquisa X e web de ponta” que melhoram a recuperação, navegação e síntese de conteúdo web durante fluxos de trabalho de agente — posicionando o Grok 4 Fast como uma ferramenta de pesquisa prática para aplicativos que exigem coleta e raciocínio de informações em tempo real em documentos longos, liderando o desempenho em vários benchmarks de pesquisa, incluindo:
- BrowseComp (zh): 51.2% (vs. 45.0%) do Grok 4
- X Bench Deepsearch (zh): 74.0% (vs. 66.0% do Grok 4)
Arquitetura Unificada: O mesmo modelo suporta modos de inferência e não inferência, eliminando a necessidade de alternar modelos separadamente. A latência e o custo reduzidos o tornam adequado para aplicações em tempo real (como pesquisa, resposta a perguntas e auxílio à pesquisa).
Comparação de desempenho (principais benchmarks)
Em testes privados do LMArena que o xAI compartilhou, o grok-4-fast-search (codinome Menlo) a variante lidera a Search Arena com uma classificação Elo de 1,163, enquanto a variante de texto (tahoe) está entre os dez primeiros no Text Arena — resultados que o xAI usa para respaldar suas afirmações sobre desempenho de pesquisa.
Grok 4 Correspondência rápida ou muito próxima do Grok 4 em vários benchmarks de fronteira (por exemplo: GPQA Diamond, AIME 2025 e HMMT 2025), ao mesmo tempo em que supera modelos menores anteriores em tarefas de raciocínio — evidência que o xAI usa para justificar a alegação de "desempenho comparável".
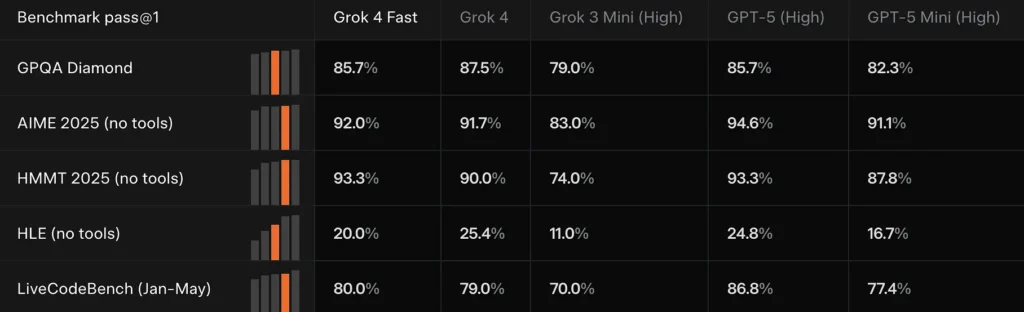
Compare os resultados
Comparado ao Grok 4: Mais barato e menos intensivo em termos computacionais, mas com desempenho semelhante.
Comparado ao Grok 3 Mini: Mais poderoso, capaz de raciocínio complexo e pesquisa em tempo real.
Comparado ao GPT-5/Gemini/Claude: Graças à sua eficiência de token extremamente alta e recursos de ferramentas, ele lidera em custo-benefício e em algumas tarefas de pesquisa.
Preços e disponibilidade
Contexto e tokens: Dois sabores de modelo: grok-4-fast-reasoning e grok-4-fast-non-reasoning, cada um com 2M de contexto.
Preços publicados (lista) na postagem de lançamento (níveis de exemplo):
- Tokens de entrada: $ 0.20 / 1 milhão (<128 mil) — $ 0.40 / 1 milhão (≥128 mil)
- Tokens de saída: $ 0.50 / 1 milhão (<128 mil) — $ 1.00 / 1 milhão (≥128 mil)
- Tokens de entrada armazenados em cache: $ 0.05 / 1 milhão.
(Consulte o anúncio do xAI para saber as regras exatas de cobrança e quaisquer promoções por tempo limitado.)
Disponibilidade do provedor: O xAI lista disponibilidade gratuita de curto prazo via OpenRouter e Vercel AI Gateway e disponibilidade geral via API do xAI.
O que isso significa para usuários e equipes
- Grande economia de custos para uso em produção — a combinação de preços mais baixos por token e menos tokens "pensantes" significa que as equipes podem executar mais consultas ou fluxos de trabalho de contexto mais amplo por uma pequena fração do custo do Grok 4, o que reduz significativamente as barreiras para experimentação e implantações em escala. (Afirmação apoiada por divulgações de custo/desempenho do xAI e análises de custo de terceiros.)
- Trabalha com documentos muito longos e raciocínio em várias etapas — Os tokens 2M tornam prático ingerir livros inteiros, grandes bases de código ou longos dossiês jurídicos/técnicos em uma única sessão, melhorando a precisão e a coerência para tarefas que exigem contexto de longo alcance (pesquisa de documentos, sumarização, geração de código de formato longo, assistentes de pesquisa).
- Saídas mais rápidas e de menor latência para aplicativos interativos — sendo uma variante "rápida", ela foi projetada para uma taxa de transferência de tokens mais rápida e menor latência, o que beneficia interfaces de bate-papo, assistentes de codificação e loops de agentes em tempo real, onde a capacidade de resposta é importante. (Análises artificiais e benchmarks de provedores enfatizam a velocidade de saída como um diferencial.)
- Bom custo-benefício para tarefas de raciocínio comparadas — para equipes que julgam modelos por benchmarks acadêmicos de ponta, o Grok 4 Fast oferece um forte compromisso: precisão quase de ponta a um custo drasticamente menor, tornando-o atraente para laboratórios de pesquisa e empresas que executam conjuntos de benchmarks caros com frequência.
Conclusão:
O Grok 4 Fast posiciona a xAI para competir em relação preço-desempenho e para aplicações de agentes centradas em busca. Se as alegações de eficiência e verificação da empresa se confirmarem em testes independentes e específicos de domínio, o Grok 4 Fast poderá reformular as expectativas de custo para implantações de LLM de alta capacidade e com ferramentas — especialmente para aplicações que dependem de recuperação web em tempo real e uso de ferramentas em várias etapas.
Começando a jornada
A CometAPI é uma plataforma de API unificada que agrega mais de 500 modelos de IA de provedores líderes — como a série GPT da OpenAI, a Gemini do Google, a Claude da Anthropic, a Midjourney e a Suno, entre outros — em uma interface única e amigável ao desenvolvedor. Ao oferecer autenticação, formatação de solicitações e tratamento de respostas consistentes, a CometAPI simplifica drasticamente a integração de recursos de IA em seus aplicativos. Seja para criar chatbots, geradores de imagens, compositores musicais ou pipelines de análise baseados em dados, a CometAPI permite iterar mais rapidamente, controlar custos e permanecer independente de fornecedores — tudo isso enquanto aproveita os avanços mais recentes em todo o ecossistema de IA.
Os desenvolvedores podem acessar Grok-4-rápido ( modelo: grok-4-fast-reasoning” / “grok-4-fast-reasoning) através do CometAPI, a versão mais recente do modelo está sempre atualizado com o site oficial. Para começar, explore as capacidades do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.
Pronto para ir?→ Inscreva-se no CometAPI hoje mesmo !