

GLM-5 é o novo modelo fundamental de pesos abertos, centrado em agentes, da Zhipu AI, criado para programação de longo horizonte e agentes de múltiplas etapas. Está disponível por meio de várias APIs hospedadas (incluindo CometAPI e endpoints de provedores) e como um lançamento de pesquisa com código e pesos; você pode integrá-lo usando chamadas REST compatíveis com OpenAI, streaming e SDKs.
O que é o GLM-5 da Z.ai?
GLM-5 é o modelo fundamental carro-chefe de quinta geração da Z.ai, projetado para engenharia orientada a agentes: planejamento de longo horizonte, uso de ferramentas em múltiplas etapas e design de código/sistemas em larga escala. Lançado publicamente em fevereiro de 2026, o GLM-5 é um modelo de Mistura de Especialistas (MoE) com ~744 bilhões de parâmetros totais e um conjunto de parâmetros ativos na faixa de 40B por passagem direta; a arquitetura e as escolhas de treinamento priorizam coerência de longo contexto, chamadas de ferramentas e inferência com custo eficiente para cargas de trabalho de produção. Essas escolhas permitem que o GLM-5 execute fluxos de trabalho agentic estendidos (por exemplo: navegar → planejar → escrever/testar código → iterar) preservando o contexto em entradas muito longas.
Principais destaques técnicos:
- Arquitetura MoE com ~744B total / ~40B parâmetros ativos; pré-treinamento em escala (~28.5T tokens relatados) para reduzir a distância em relação aos modelos fechados de fronteira.
- Suporte e otimizações de longo contexto (atenção esparsa profunda, DSA) para reduzir o custo de implantação em comparação com o escalonamento denso ingênuo.
- Recursos agentic embutidos: chamada de ferramentas/funções, suporte a sessões com estado e saídas integradas (capaz de produzir artefatos
.docx,.xlsx,.pdfcomo parte de fluxos de trabalho de agentes em UIs de fornecedores). - Disponibilidade de pesos abertos (pesos publicados em hubs de modelos) e opções de acesso hospedado (APIs de fornecedores, microsserviços de inferência).
Quais são as principais vantagens do GLM-5?
Planejamento agentic e memória de longo horizonte
A arquitetura e o ajuste do GLM-5 priorizam raciocínio consistente em múltiplas etapas e memória ao longo de fluxos de trabalho — um benefício para:
- agentes autônomos (pipelines de CI, orquestradores de tarefas),
- geração de código em múltiplos arquivos ou refatorações grandes, e
- inteligência de documentos que precisa manter históricos extensos.
Janelas de contexto grandes
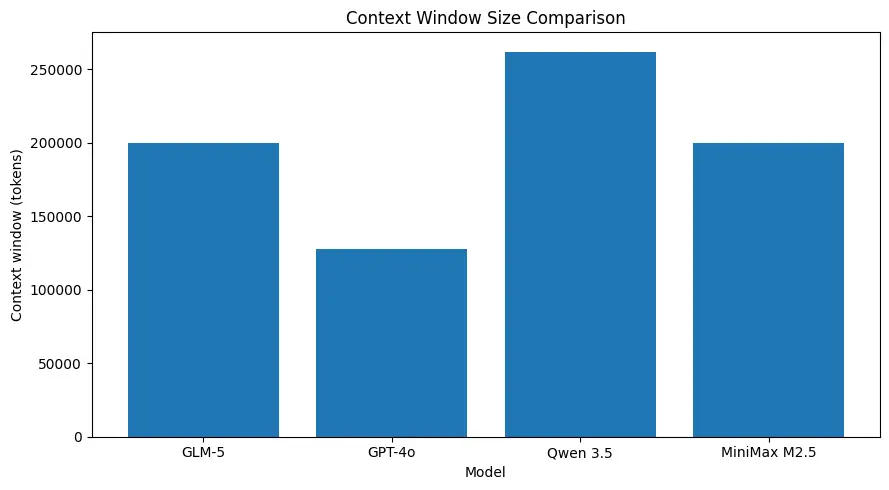
O GLM-5 suporta tamanhos de contexto muito grandes (na ordem de ~200k tokens nas especificações do modelo publicadas), permitindo manter mais da sessão em uma única requisição e reduzindo a necessidade de fragmentação agressiva ou memória externa para muitos casos de uso. (Veja o gráfico comparativo abaixo.)
Forte desempenho em programação para tarefas de nível de sistema
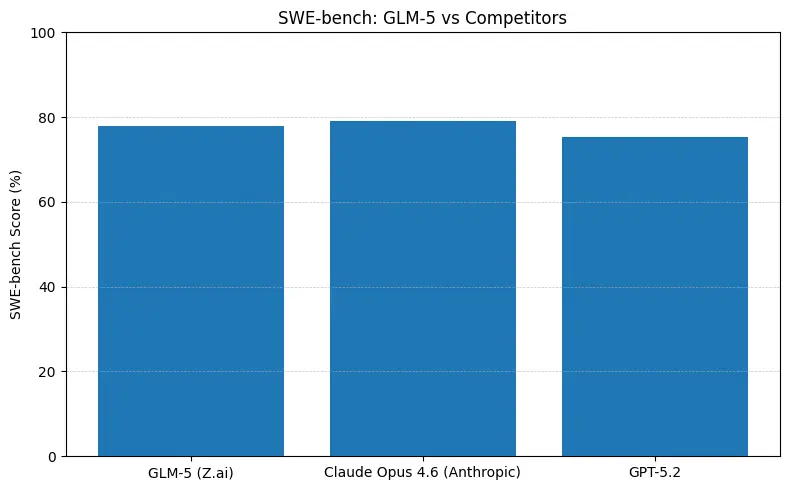
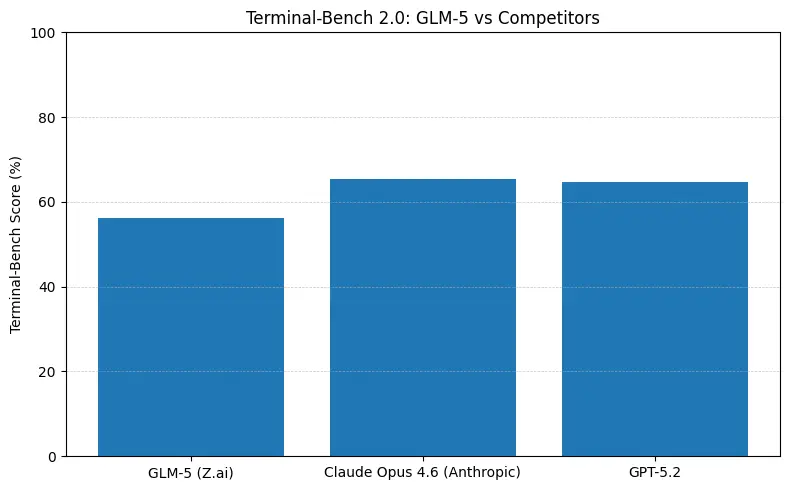
O GLM-5 reporta desempenho de ponta no código aberto em benchmarks de engenharia de software (SWE-bench e suítes aplicadas de código + agentes). No SWE-bench-Verified, reporta ~77,8%; em testes de agentes em estilo terminal (Terminal-Bench 2.0), as pontuações se agrupam em meados dos 50 — evidência de habilidade prática em programação aproximando-se dos modelos proprietários de fronteira. Essas métricas significam que o GLM-5 é adequado para tarefas como geração de código, refatoração automatizada, raciocínio em múltiplos arquivos e cenários de assistente de CI/CD.
Compromissos de custo/eficiência
Como o GLM-5 usa MoE e inovações de atenção “esparsa”, ele visa reduzir o custo de inferência por unidade de capacidade em comparação com o escalonamento denso por força bruta. CometAPI oferece pontos de preço competitivos que tornam o GLM-5 atraente para cargas de trabalho agentic de alto throughput.
Como usar a API do GLM-5 via CometAPI?
Resposta curta: trate a CometAPI como um gateway compatível com OpenAI — defina sua URL base e chave de API, escolha glm-5 como o modelo e, em seguida, chame o endpoint de chat/completions. A CometAPI fornece uma superfície REST no estilo OpenAI (endpoints como /v1/chat/completions) além de SDKs e projetos de exemplo que tornam a migração trivial.
Abaixo está um roteiro prático orientado à produção: autenticação, chamada básica de chat, streaming, chamada de função/ferramenta e tratamento de custo/resposta.
As etapas básicas para acessar o GLM-5 via CometAPI são:
- Cadastre-se na CometAPI, obtenha uma chave de API.
- Encontre o id exato do modelo para o GLM-5 no catálogo da CometAPI (
"glm-5"dependendo da listagem). - Envie uma requisição POST autenticada para o endpoint de chat/completions da CometAPI (estilo OpenAI).
Detalhes base (padrões da CometAPI): a plataforma suporta caminhos no estilo OpenAI como https://api.cometapi.com/v1/chat/completions, autenticação Bearer, parâmetro model, mensagens de sistema/usuário, streaming e exemplos de curl/python na documentação.
Exemplo: Python rápido (requests) chat completion com GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Exemplo: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Respostas em streaming (padrão prático)
A CometAPI suporta streaming no estilo OpenAI (SSE / chunked). A abordagem mais simples em Python é solicitar "stream": true e iterar sobre os dados da resposta conforme chegam. Isso é importante quando você precisa de saída parcial de baixa latência (construir assistentes de desenvolvimento em tempo real, UIs com streaming).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Referência: streaming no estilo OpenAI e documentação de compatibilidade da CometAPI.
Chamada de função/ferramenta (como chamar uma ferramenta externa)
O GLM-5 suporta padrões de chamada de função ou ferramenta compatíveis com convenções do OpenAI/aggregators (o gateway passa chamadas de função estruturadas na resposta do modelo). Exemplo de caso de uso: pedir ao GLM-5 para chamar uma ferramenta local “run_tests”; o modelo retorna uma instrução estruturada que você pode analisar e executar.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Quando o modelo retorna um payload function_call, execute a ferramenta no lado do servidor e então alimente o resultado da ferramenta de volta como uma mensagem com o papel "tool" e retome a conversa. Esse padrão habilita invocação segura de ferramentas e fluxos de agentes com estado. Veja a documentação e os exemplos da CometAPI para utilitários de SDK concretos.
Parâmetros práticos e ajuste
function_call: use para habilitar invocação estruturada de ferramentas e fluxos de execução mais seguros.
temperature: 0–0.3 para saídas determinísticas de nível de sistema (código, infraestrutura), maior para ideação.
max_tokens: defina para o comprimento esperado da saída; o GLM-5 suporta saídas muito longas quando hospedado (os limites de fornecedores variam).
top_p / nucleus sampling: útil para limitar caudas improváveis.
stream: true para UIs interativas.
GLM-5 comparado ao Claude Opus da Anthropic e outros modelos de ponta
Resposta curta: o GLM-5 reduz a distância em relação aos modelos fechados de fronteira em benchmarks agentic e de programação, oferecendo implantação com pesos abertos e, muitas vezes, melhor custo por token quando hospedado por agregadores. A nuance: em alguns benchmarks absolutos de programação (SWE-bench, variantes do Terminal-Bench), o Claude Opus (4.5/4.6) da Anthropic ainda lidera por alguns pontos em muitos rankings publicados — mas o GLM-5 é altamente competitivo e supera muitos outros modelos abertos.
O que os números significam na prática
- SWE-bench (~correção de código / engenharia): o Claude Opus mostra liderança marginal (≈79% vs GLM-5 ≈77,8%) em rankings publicados; para muitas tarefas reais, essa diferença se traduzirá em menos edições manuais, mas não necessariamente em uma escolha de arquitetura diferente para prototipagem ou fluxos de trabalho agentic em escala.
- Terminal-Bench (tarefas agentic em linha de comando): Opus 4.6 lidera (≈65,4% vs GLM-5 ≈56,2%) — se você precisa de automação de terminal robusta e máxima confiabilidade em operações de shell fora de distribuição, o Opus costuma ser melhor na margem.
- Agentic e longo horizonte: o GLM-5 performa extremamente bem em simulações de negócios de longo horizonte (Vending-Bench 2 saldo $4,432 reportado) e mostra forte coerência de planejamento para fluxos de trabalho em múltiplas etapas. Se seu produto é um agente de longa execução (finanças, operações), o GLM-5 é forte.
Como projetar prompts e sistemas para obter saídas confiáveis do GLM-5?
Mensagens de sistema e restrições explícitas
Dê ao GLM-5 um papel e restrições estritas, especialmente para tarefas de código ou chamadas de ferramentas. Exemplo:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Peça testes e raciocínio curto para cada mudança não trivial.
Decomponha tarefas complexas
Em vez de “escreva o produto completo”, peça:
- esboço de design,
- assinaturas de interface,
- implementação e testes,
- script de integração final.
Essa decomposição em etapas reduz alucinações e oferece pontos de controle determinísticos que você pode validar.
Use baixa temperatura para código determinístico
Ao pedir código, defina temperature = 0–0,2 e max_tokens para um limite superior seguro. Para escrita criativa ou brainstorming de design, aumente a temperatura.
Boas práticas ao integrar o GLM-5 (via CometAPI ou hosts diretos)
Engenharia de prompts e prompts de sistema
- Use instruções de sistema explícitas que definam papéis de agentes, políticas de acesso a ferramentas e restrições de segurança. Exemplo: “Você é um arquiteto de sistemas: só proponha mudanças quando os testes unitários passarem localmente; liste os comandos exatos de CLI a serem executados.”
- Para tarefas de código, forneça contexto do repositório (listas de arquivos, trechos de código-chave) e anexe saídas de testes unitários, se disponíveis. O tratamento de longo contexto do GLM-5 ajuda — mas sempre mantenha o contexto essencial primeiro (papel, tarefa) e depois artefatos de suporte.
Gerenciamento de sessão e estado
- Use IDs de sessão para conversas longas de agentes e mantenha uma “memória” compactada de etapas anteriores (sumários) para evitar inchaço de contexto. A CometAPI e gateways similares fornecem auxiliares de sessão/estado — mas a compactação de estado em nível de aplicação é essencial para agentes de longa execução.
Ferramentas e chamadas de função (segurança + confiabilidade)
- Exponha um conjunto estreito e auditável de ferramentas. Não permita execução arbitrária de shell sem supervisão humana. Use definições de função estruturadas e valide seus argumentos no lado do servidor.
- Sempre registre chamadas de ferramentas e respostas do modelo para rastreabilidade e depuração pós-mortem.
Controle de custo e processamento em lote
- Para agentes de alto volume, direcione processamento em segundo plano para variantes de modelo mais baratas quando os trade-offs de qualidade forem aceitáveis (a CometAPI permite trocar modelos por nome). Agrupe requisições semelhantes e reduza
max_tokensquando possível. Monitore a razão de tokens de entrada versus saída — tokens de saída são frequentemente mais caros.
Engenharia de latência e vazão
- Use streaming para sessões interativas. Para trabalhos de agentes em segundo plano, prefira runtimes assíncronos, filas de workers e limitadores de taxa. Se você autohospedar (pesos abertos), ajuste sua topologia de aceleradores à arquitetura MoE — opções de FPGA / Ascend / silício especializado podem gerar ganhos de custo.
Notas finais
O GLM-5 representa um passo prático, de pesos abertos, rumo à engenharia orientada a agentes: janelas de contexto grandes, capacidades de planejamento e forte desempenho em código o tornam atraente para ferramentas de desenvolvedor, orquestração de agentes e automação de nível de sistema. Use a CometAPI para integração rápida ou um jardim de modelos em nuvem para hospedagem gerenciada; sempre valide em sua carga de trabalho e instrumente amplamente para controle de custos e alucinações.
Desenvolvedores podem acessar GLM-5 via CometAPI agora. Para começar, explore as capacidades do modelo no Playground e consulte o guia da API para instruções detalhadas. Antes de acessar, certifique-se de ter feito login na CometAPI e obtido a chave de API. A CometAPI oferece um preço muito inferior ao preço oficial para ajudar você a integrar.
Pronto para começar?→ Sign up fo M2.5 today !
Se quiser saber mais dicas, guias e novidades sobre IA, siga-nos no VK, X e Discord!