

Claude Sonnet 4.5 da Anthropic (frequentemente abreviado para Soneto 4.5) chegou como um sucessor focado em desempenho na família Claude da Anthropic. Para equipes que decidem adotar o Claude Sonnet 4.5 para chatbots, assistentes de código ou agentes autônomos de longa duração, o custo é uma questão crucial — e não é apenas o preço por token que importa, mas como você implementa o modelo, quais recursos de economia você usa e com quais modelos concorrentes você o compara.
O que é Claude Sonnet 4.5 e por que usá-lo?
O Claude Sonnet 4.5 é o mais recente modelo emblemático da família Sonnet da Anthropic, otimizado para fluxos de trabalho agênticos de longo prazo, codificação e raciocínio complexo em várias etapas. A Anthropic posiciona o Claude Sonnet 4.5 como um modelo de "fronteira", com uma ampla janela de contexto e melhorias na execução sustentada de tarefas, edição de código e raciocínio de domínio em comparação com as versões anteriores do Sonnet.
Recursos técnicos e de uso notáveis
- Desempenho estendido de longo contexto — projetado para manter um trabalho coerente em muitas etapas (a Anthropic cita casos de uso de trabalho contínuo de várias horas).
- Primitivas de edição e execução de código aprimoradas — recursos para pontos de verificação, execução de código em algumas integrações e melhor precisão de edição em comparação com modelos anteriores do Sonnet/Opu.
- Raciocínio, codificação e desempenho de agente aprimorados — o Anthropic destaca execuções autônomas contínuas mais longas e comportamento mais confiável para fluxos de trabalho de várias etapas.
- Projetado para uso em contexto longo (as variantes do Sonnet geralmente têm como alvo grandes janelas de contexto aplicáveis a bases de código e fluxos de trabalho de vários documentos), com melhorias no nível do sistema e proteções focadas em segurança.
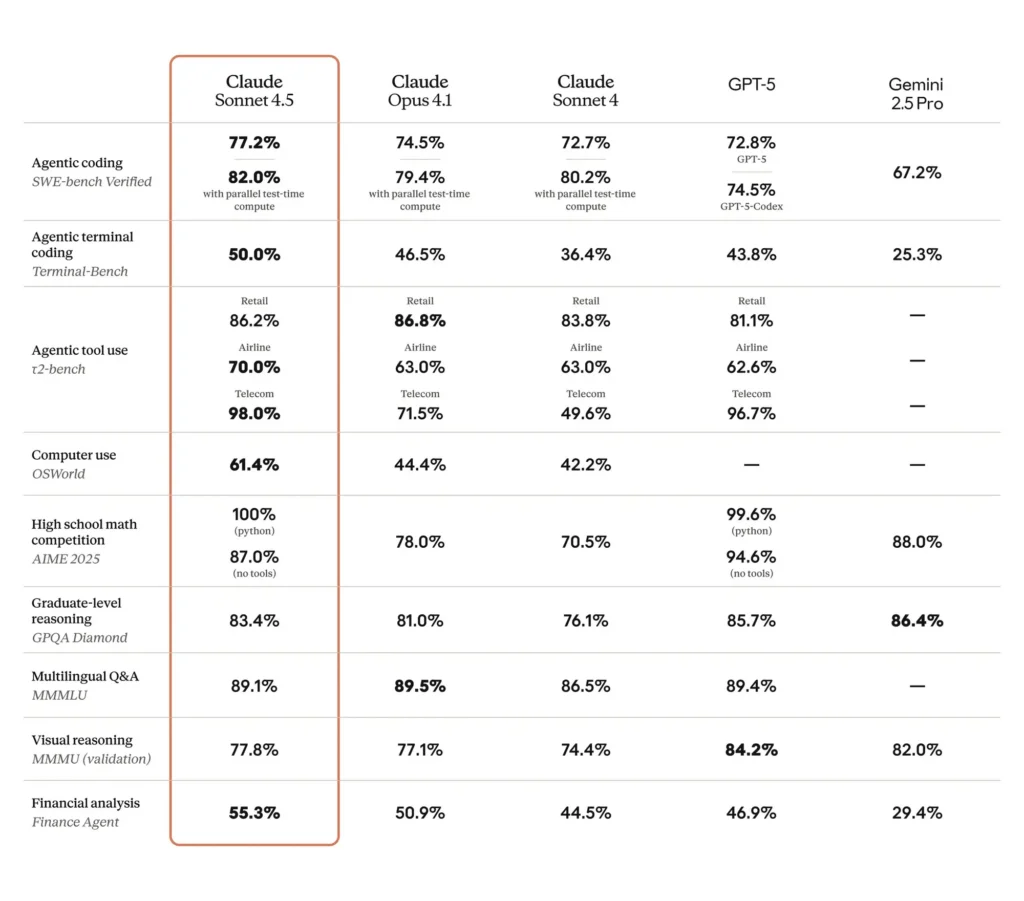
*Maior “uso do computador” e desempenho de codificação
Se seu produto ou equipe precisa de um ou mais dos seguintes itens, o Claude Sonnet 4.5 foi projetado especificamente para ser atraente:
- Execuções longas e com estado do agente (criadores de aplicativos autônomos, síntese de código de várias horas ou testes automatizados).
- Edição e refatoração de código de alta qualidade — Relatórios da Anthropic direcionam melhorias nas taxas de erros de edição de código interno em comparação com versões anteriores do Sonnet.
- Raciocínio complexo e trabalho de domínio em finanças, direito, medicina e STEM, onde um contexto mais longo e menos “lembretes” aumentam a produtividade e reduzem a orquestração manual.
Qual é o preço para usar o Claude 4.5 por meio do aplicativo Claude?
Quais são os níveis de assinatura do consumidor (web/celular)?
Os níveis de consumidor da Anthropic ainda se parecem com isso (páginas de preços públicos e documentos de back-end):
- Free — útil para uso casual; taxa de transferência de mensagens/uso limitada.
- Pro — US$ 20/mês cobrados mensalmente (com desconto para aproximadamente US$ 17/mês cobrados anualmente), destinado a usuários avançados do dia a dia e com recursos avançados de produtividade. O plano Pro aumenta os limites de sessão/uso (aproximadamente ~5x grátis durante períodos de pico).
- Plano máximo — A Anthropic anunciou planos "Max" de uso mais alto (US$ 100/mês para ~5x o uso do plano Pro, US$ 200/mês para ~20x o uso do plano Pro) para usuários avançados/profissionais que precisam de uso intenso e contínuo sem a necessidade de aquisição corporativa. Esses planos são explicitamente direcionados a pessoas que, de outra forma, atingiriam o limite máximo de sessões do plano Pro.
Quantas horas/mensagens uma assinatura compra?
Pro os usuários podem esperar algo como ~45 mensagens a cada cinco horas ou ~40–80 horas de uso semanal do Sonnet, dependendo da carga de trabalho; Max Os níveis aumentam drasticamente (máx. 5× e 20× proporcionam aumentos proporcionais). Essas são faixas de aproximação — o consumo real depende do tamanho do prompt, do tamanho dos anexos, das escolhas de modelo (Soneto vs. Opus vs. Haiku) e de recursos como o Claude Code.
Quais são os detalhes de preço da API para o Claude Sonnet 4.5?
Como o faturamento da API é medido?
Uso da API de contas antrópicas por tokens e separa tokens de entrada (o que você envia) de tokens de saída (o que o modelo retorna). Para Claude Sonnet 4.5, as taxas de referência publicadas pela Anthropic são:
- Entrada (API padrão): US$ 3.00 por 1,000,000 de tokens de entrada.
- Saída (API padrão): US$ 15.00 por 1,000,000 de tokens de saída.
Quais descontos ou modos alternativos existem?
- API de lote (processamento em massa assíncrono) carrega um ~ 50% de desconto em documentos antrópicos — comumente representados como Entrada de US$ 1.50 / M e $ 7.50 / M saída para modelos Sonnet em modo batch. O Batch é ideal para grandes cargas de trabalho offline, como análise de base de código ou sumarização em massa.
- Cache de prompt pode produzir até economias efetivas muito grandes ao chamar prompts idênticos repetidamente. Use o cache para prompts repetitivos do assistente ou planos de agente onde o mesmo prompt de origem se repete.
- canais de terceiros: CometAPI oferece 20% de desconto na API oficial e tem uma versão de API de cursor especialmente adaptada: Tokens de entrada (prompt) is US$ 2.4 por 1,000,000 (1M) de tokens de entrada; Tokens de saída (geração): US$ 12 por 1,000,000 (1M) de tokens de saída.
Observação: “cache de prompt” e “processamento em lote” são padrões de implementação que reduzem a computação repetida em prompts idênticos e amortizam o trabalho em várias chamadas — o quanto eles economizam depende inteiramente dos padrões de carga de trabalho do seu aplicativo.
Como as opções de assinatura e API se comparam em termos de custo?
Depende inteiramente de perfil de uso:
- Para a produtividade humana interativa (escrita, pesquisa, assistência ocasional com código) Pro or Max As assinaturas geralmente oferecem o melhor custo-benefício, pois combinam capacidade, recursos do aplicativo e limites de sessão mais altos por uma mensalidade previsível. O Pro da Anthropic é voltado para escritores e equipes pequenas; o Max é voltado para profissionais que precisam de muito mais horas e solicitações por mês.
- Para a programático, de alto volume ou por transação uso (webhooks, recursos do produto que chamam o modelo milhares/milhões de vezes por dia), API O pagamento conforme o uso geralmente é a escolha correta: o custo é escalonado com tokens, e você pode usar preços em lote e armazenamento em cache para reduzir tokens faturáveis.
Regra prática
Se a sua fatura mensal esperada de API (de US$ 3/US$ 15 por M) fosse substancialmente mais caro do que o espaço Pro/Max que você precisa (após converter suas horas/mensagens esperadas em tokens), compre uma assinatura ou um plano empresarial. Por outro lado, se o seu produto precisa de chamadas programáticas detalhadas, a API é a única opção prática.
Claude Sonnet 4.5 — Custos estimados por cenário de aplicação
Abaixo estão práticas, estimativas de custos mensais acionáveis para Claude Sonnet 4.5 em cenários típicos de aplicação (geração de texto, código, RAG, agentes, sumarização de documentos longos, etc.). Cada cenário mostra as premissas (tokens por chamada e chamadas/mês), base custo mensal usando as taxas publicadas pela Anthropic ($ 3 / 1M tokens de entrada, $ 15 / 1M de tokens de saída), e duas visões de otimização comuns: uma fornada desconto (50% de desconto nas taxas de token) e cache de prompt Exemplos (70% de acerto de cache e 90% de acerto de cache). Esses descontos/benefícios são comprovados pela documentação da Anthropic (lote ≈ 50% e cache instantâneo com economia de até ~90%).
Quais são as regras e premissas de cálculo?
- 1,000,000 de tokens é a unidade de cobrança.
- O custo mensal = (total_input_tokens / 1,000,000) × input_rate + (total_output_tokens / 1,000,000) × output_rate.
- Eu relato três colunas de custos: Base, Lote (50% de desconto nas taxas), Cache (duas suposições representativas de acerto de cache: 70% e 90% das chamadas atendidas pelo cache).
- Esses são modelos de estimativa — as contas reais variam de acordo com a qualidade do cache-hit, tamanhos exatos de prompts, durações de resposta e quaisquer descontos negociados ou margens de parceiros/nuvem.
Abaixo estão 9 cenários. Para cada um, listo: chamadas/mês, média de tokens de entrada (prompt/contexto) e média de tokens de saída (resposta do modelo), depois totais e custos mensais.
Guia aproximado de conversão de token para palavra: 1,000 tokens ≈ 750–900 palavras, dependendo do idioma e da formatação.
1) Conteúdo resumido (esboços de blog, postagens sociais)
Pressupostos: 1,000 chamadas/mês; 200 tokens de entrada/chamada; 1,200 tokens de saída/chamada.
Totais: 200,000 tokens de entrada; 1,200,000 tokens de saída.
| Visão de custo | Custo mensal |
|---|---|
| Base (sem descontos) | $18.60 |
| Lote (taxa de token de 50%) | $9.30 |
| 70% de acerto de cache (apenas 30% cobrados) | $5.58 |
| 90% de acerto de cache (apenas 10% cobrados) | $1.86 |
Quando isso se encaixa: pequenos criadores e agências que geram muitas peças curtas. Armazenar em cache prompts com modelos (por exemplo, modelos de estrutura de tópicos fixos) tem alto impacto.
2) Geração de artigos longos (saídas de várias páginas)
Pressupostos: 200 chamadas/mês; 500 tokens de entrada; 5,000 tokens de saída.
Totais: 100,000 tokens de entrada; 1,000,000 tokens de saída.
| Visão de custo | Custo mensal |
|---|---|
| Base | $15.30 |
| Fornada | $7.65 |
| Cache 70% | $4.59 |
| Cache 90% | $1.53 |
Quando isso se encaixa: saídas que produzem artigos longos; use lote para geração em massa programada e cache para modelos repetidos. Como os tokens de saída dominam aqui, a taxa de saída por token do Sonnet é importante, mas esses custos são modestos para volumes de artigos baixos a moderados. Para alta produtividade (centenas a milhares de artigos longos/mês), a combinação em lote + truncamento cuidadoso ainda reduz significativamente os custos.
3) Chatbot de suporte ao cliente (implantação de médio porte)
Pressupostos: 30,000 sessões/mês; 600 tokens de entrada; 800 tokens de saída.
Totais: 18,000,000 tokens de entrada; 24,000,000 tokens de saída.
| Visão de custo | Custo mensal |
|---|---|
| Base | $387.00 |
| Fornada | $193.50 |
| Cache 70% | $116.10 |
| Cache 90% | $38.70 |
Quando isso se encaixa: Suporte conversacional para aplicativos de médio porte — RAG/recuperação de conhecimento, além do armazenamento em cache de respostas prontas, reduz drasticamente os custos. Para chatbots, os tokens de saída geralmente geram custosReduzir a verbosidade (respostas direcionadas) e usar streaming/interrupção antecipada ajuda. O cache só ajuda se os mesmos prompts forem repetidos.
4) Assistente de código (integrações de IDE, edição e correções)
Pressupostos: 10,000 chamadas/mês; 1,200 tokens de entrada; 800 tokens de saída.
Totais: 12,000,000 tokens de entrada; 8,000,000 tokens de saída.
| Visão de custo | Custo mensal |
|---|---|
| Base | $258.00 |
| Fornada | $129.00 |
| Cache 70% | $77.40 |
| Cache 90% | $25.80 |
Quando isso se encaixa: Assistência por edição dentro de um IDE. Considere encaminhar tarefas de lint/formatação para modelos mais leves e escalar para o Claude Sonnet 4.5 para edições de código de maior valor. Reutilize prompts e modelos do sistema com cache ao chamar prompts de geração de código semelhantes para reduzir os custos de entrada.
5) Resumo de documentos — documentos longos (jurídicos/financeiros)
Pressupostos: 200 chamadas/mês; 150,000 tokens de entrada (documentação grande/fragmentação incluída); 5,000 tokens de saída.
Totais: 30,000,000 tokens de entrada; 1,000,000 tokens de saída.
| Visão de custo | Custo mensal |
|---|---|
| Base (≤200k entrada → taxas padrão) | $615.00 |
| Fornada | $307.50 |
| Cache 70% | $184.50 |
| Cache 90% | $61.50 |
Importante: este exemplo mantém a entrada por chamada ≤200k então taxas padrão se aplicam. Se sua entrada por chamada exceder 200 mil tokens, contexto longo o preço se aplica (veja o próximo cenário).
6) Revisão de documentos ultra longos (> 200 mil tokens por solicitação → taxas de contexto longo)
Pressupostos: 20 chamadas/mês; 600,000 tokens de entrada / chamada; 20,000 tokens de saída / chamada.
Totais: 12,000,000 tokens de entrada; 400,000 tokens de saída.
Como a entrada por solicitação é > 200 mil, as taxas premium de longo contexto da Anthropic se aplicam (exemplo: US$ 6 / 1 milhão de entrada e US$ 22.50 / 1 milhão de saída usados aqui).
| Visão de custo (tarifas de longo contexto) | Custo mensal |
|---|---|
| Base de contexto longo | $81.00 |
| (Para comparação com as taxas padrão se o contexto longo não for cobrado) | $42.00 |
Quando isso se encaixa: Análise de chamada única de conjuntos de evidências ou livros extremamente grandes. Use fragmentação + recuperação e RAG para evitar cobranças premium por chamada em contextos longos, sempre que possível.
7) RAG / perguntas e respostas empresariais (QPS muito alto)
Pressupostos: 1,000,000 chamadas/mês; 400 tokens de entrada; 200 tokens de saída.
Totais: 400,000,000 tokens de entrada; 200,000,000 tokens de saída.
| Visão de custo | Custo mensal |
|---|---|
| Base | $3,300.00 |
| Fornada | $1,650.00 |
| Cache 70% | $990.00 |
| Cache 90% | $330.00 |
Quando isso se encaixa: Controle de qualidade de documentos de alto volume. RAG + pré-filtragem + caches locais reduzem drasticamente as chamadas que devem atingir o Claude Sonnet 4.5.
8) Automação agêntica (agentes contínuos, muitos turnos)
Pressupostos: 50,000 sessões de agente/mês; 2,000 tokens de entrada; 4,000 tokens de saída.
Totais: 100,000,000 tokens de entrada; 200,000,000 tokens de saída.
| Visão de custo | Custo mensal |
|---|---|
| Base | $3,300.00 |
| Fornada | $1,650.00 |
| Cache 70% | $990.00 |
| Cache 90% | $330.00 |
Quando isso se encaixa: Agentes em segundo plano que executam muitas etapas. A arquitetura é importante: comprima o estado, resuma o histórico e armazene em cache subprompts repetidos para controlar custos.
9) Tradução em lote (trabalhos em lotes grandes)
Pressupostos: 500 trabalhos em lote/mês; 50,000 tokens de entrada; 50,000 tokens de saída.
Totais: 25,000,000 tokens de entrada; 25,000,000 tokens de saída.
| Visão de custo | Custo mensal |
|---|---|
| Base | $450.00 |
| Fornada | $225.00 |
| Cache 70% | $135.00 |
| Cache 90% | $45.00 |
Quando isso se encaixa: processamento em massa agendado — a API em lote é a maior alavanca aqui.
Como o preço do Claude Sonnet 4.5 se compara ao de outros modelos populares?
Comparação de preços de tokens (visão simples)
- Soneto de Claude 4.5: Entrada de US$ 3/1 milhão, Produção de US$ 15/1 milhão (API padrão).
- OpenAI GPT-4o (exemplos relatados): Aproximadamente Entrada de US$ 2.50/1 milhão, Produção de US$ 10/1 milhão.
- OpenAI GPT-5 (exemplo de preço público para seu carro-chefe): Aproximadamente Entrada de US$ 1.25/1 milhão, Produção de US$ 10/1 milhão (Preços de API publicados pela OpenAI quando o GPT-5 foi lançado).
Interpretação: O custo de saída do Sonnet é materialmente mais alto do que alguns preços de saída emblemáticos do OpenAI, mas o Sonnet visa compensar isso com melhor eficiência de agente (menos etapas de ida e volta porque pode manter um contexto mais longo e fazer mais internamente), e as opções de cache/lote do Anthropic podem reduzir significativamente os custos efetivos para prompts repetidos.
A capacidade por dólar importa
Se o Claude Sonnet 4.5 puder concluir uma tarefa de agente de várias horas em menos chamadas de API ou gerar saídas mais compactas e corretas que não precisam de pós-processamento, o custo real (horas de engenharia + taxas de API) podem ser menores, apesar de uma taxa de produção por token mais alta. Os custos de benchmark devem ser calculados por fluxo de trabalho, não apenas por token.
Quais estratégias de otimização de custos funcionam melhor com o Claude Sonnet 4.5?
1) Explorar agressivamente o cache de prompts
Anúncios antrópicos até% 90 Economia para prompts repetidos. Se o seu aplicativo envia frequentemente os mesmos prompts do sistema ou instruções repetidas, o cache reduz drasticamente o processamento de tokens. Implemente camadas de cache na frente da API para evitar o reenvio de prompts inalterados. ()
2) Solicitações em lote sempre que possível
Para processamento de dados ou inferência de múltiplos itens, agrupe vários itens em uma única chamada de API. A Anthropic e outros fornecedores relatam economias substanciais nos modos em lote — a economia exata depende de como o fornecedor cobra pela computação em lote. ()
3) Reduzir o volume de tokens de saída de forma proativa
- Use configurações de token máximo mais rigorosas e instrua os modelos a serem concisos quando aceitável.
- Para fluxos de interface do usuário, envie respostas parciais ou resumos em vez de saídas detalhadas completas. Como o preço de saída do Sonnet é o maior contribuinte de custo, a redução de tokens gerados gera economias consideráveis.
4) Seleção e roteamento do modelo
- Encaminhe tarefas de extração ou de baixo valor para modelos mais baratos (ou variantes menores do Claude) e reserve o Sonnet 4.5 para trabalho de código/agente de missão crítica.
- Avalie variantes “mini” menores ou modelos Claude mais antigos para tarefas em segundo plano.
5) Cache de saídas geradas para consultas repetidas
Se os usuários solicitarem frequentemente a mesma resposta (por exemplo, descrições de produtos, trechos de políticas), armazene em cache a saída do modelo e forneça respostas em cache em vez de gerá-las novamente.
6) Use embeddings + recuperação para reduzir o tamanho do prompt
Armazene documentos longos em um banco de dados vetorial e recupere apenas os trechos mais relevantes para incluir nos prompts — isso reduz os tokens de entrada e mantém o contexto restrito.
Como chamar a API do Claude Sonnet de forma mais barata?
A CometAPI é uma plataforma de API unificada que agrega mais de 500 modelos de IA de provedores líderes — como a série GPT da OpenAI, a Gemini do Google, a Claude da Anthropic, a Midjourney e a Suno, entre outros — em uma interface única e amigável ao desenvolvedor. Ao oferecer autenticação, formatação de solicitações e tratamento de respostas consistentes, a CometAPI simplifica drasticamente a integração de recursos de IA em seus aplicativos. Seja para criar chatbots, geradores de imagens, compositores musicais ou pipelines de análise baseados em dados, a CometAPI permite iterar mais rapidamente, controlar custos e permanecer independente de fornecedores — tudo isso enquanto aproveita os avanços mais recentes em todo o ecossistema de IA.
Os desenvolvedores podem acessar Claude Soneto 4.5 API através do CometAPI, a versão mais recente do modelo está sempre atualizado com o site oficial. Para começar, explore as capacidades do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.
Pronto para ir?→ Inscreva-se no CometAPI hoje mesmo !
Conclusão
Claude Sonnet 4.5 é um modelo de alta capacidade posicionado para tarefas longas, de agente e de codificação. O preço de tabela da API publicada pela Anthropic para o Sonnet 4.5 é de aproximadamente US$ 3 por milhão de tokens de entrada e US$ 15 por milhão de tokens de saída, com mecanismos de lote e cache que frequentemente reduzem os custos efetivos pela metade ou mais para a carga de trabalho certa. Os níveis de assinatura (Pro, Max) e os acordos corporativos oferecem maneiras alternativas de adquirir capacidade para cargas de trabalho interativas ou com uso intensivo de recursos humanos. Ao planejar a adoção, meça os tokens por fluxo de trabalho, teste o Sonnet nos seus fluxos mais complexos e use cache rápido, processamento em lote e seleção de modelos para otimizar a relação custo-benefício.