

A chinesa Z.ai (anteriormente Zhipu AI) voltou a ganhar as manchetes com o lançamento de sua série GLM 4.5 de código aberto. Posicionada como uma alternativa econômica e de alto desempenho aos modelos de linguagem de grande porte existentes, a GLM-4.5 promete remodelar a economia de tokens e democratizar o acesso para startups, empresas e instituições de pesquisa. Este artigo abrangente explora as origens, a estrutura de preços e o valor real da série GLM-4.5, abordando as duas principais questões na mente de todos os stakeholders: quanto custa e vale a pena?
O que é a série GLM 4.5?
A série GLM 4.5 da Z.ai é construída sobre uma estrutura de IA "agentística", o que significa que o modelo pode decompor tarefas complexas de forma autônoma em subtarefas menores e sequenciais, aumentando a precisão e reduzindo a redundância computacional. Isso contrasta com LLMs mais monolíticos que processam solicitações em uma única etapa. De acordo com a Z.ai, o GLM 4.5 incorpora nativamente o raciocínio e o planejamento de ações em sua arquitetura central, permitindo fluxos de trabalho em várias etapas, como geração de visualização de dados ou processamento de documentos de ponta a ponta, sem orquestração externa.
A Série GLM 4.5, desenvolvida pela Z.ai, representa a última geração de modelos de linguagem de grande porte de código aberto, Mixture-of-Experts (MoE), projetados para unificar raciocínio avançado, geração de código e recursos agênticos em uma única arquitetura. Ela vem em duas versões principais: a principal GLM 4.5 (355 B parâmetros totais, 32 B ativos) e o mais leve GLM 4.5‑Ar (106 bilhões no total, 12 bilhões ativos). Ambas as variantes utilizam um mecanismo de inferência híbrido — "modo de pensamento" para raciocínio complexo e baseado em ferramentas e "modo sem pensamento" para conclusões rápidas e diretas — atendendo a um amplo espectro de casos de uso, desde desenvolvimento full-stack até fluxos de trabalho de agentes autônomos.
especificações técnicas principais:
- Parâmetros Técnicos : O GLM 4.5 apresenta 355 bilhões de parâmetros, com um subconjunto ativo de 32 bilhões envolvidos por inferência para otimizar o uso do hardware e o rendimento.
- Mistura de Especialistas (MoE):A série aproveita a arquitetura MoE, roteando tokens para sub-redes especializadas dinamicamente para maior eficiência.
- Janela de contexto: Estendido para 128 K tokens em plataformas selecionadas (por exemplo, SiliconFlow), acomodando grandes documentos e bases de código.
- Velocidade de geração: As variantes de alta velocidade excedem 100 tokens/seg, adequadas para aplicações em tempo real.
- Modos de Inferência Híbridos: Os usuários podem alternar entre o modo “pensamento” (ativação total do MoE para raciocínio profundo) e o modo “não-pensamento” (ativação mínima para respostas rápidas e instantâneas), concedendo aos desenvolvedores controle preciso sobre desempenho versus velocidade.
Quais variantes existem dentro da Série?
- GLM 4.5 (Padrão): 355 B no total / 32 B de parâmetros ativos. Projetado principalmente para desempenho equilibrado em tarefas de raciocínio, codificação e agentes.
- GLM 4.5‑Ar: Uma versão leve com 106 B no total / 12 B de parâmetros ativos, adaptada para cenários com restrições rigorosas de hardware ou latência, oferecendo precisão competitiva em sua classe.
Quanto custa a série GLM 4.5?
Quais são os preços dos tokens de entrada e saída?
De acordo com as divulgações de preços da API pública da Z.ai, o GLM 4.5 tem o seguinte preço:
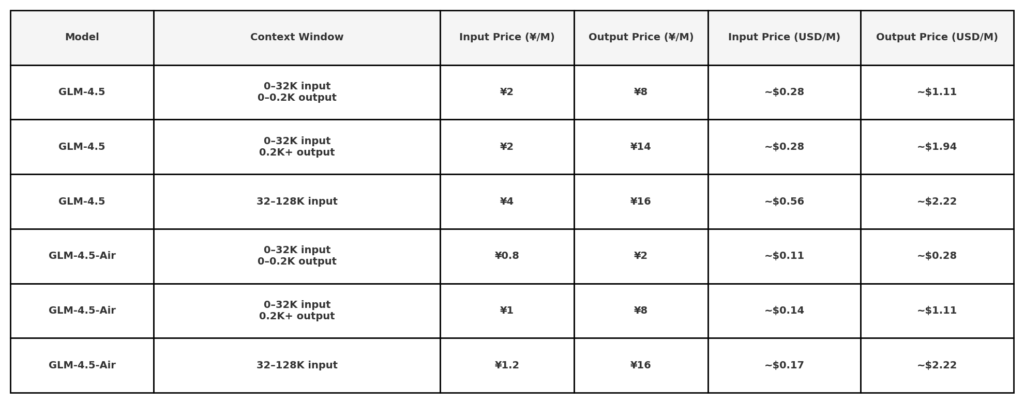
Nota: taxas muito baixas ($ 0.11 / $ 0.28) podem ser limitadas a pequenos comprimentos de token ou promoções específicas. 50% de desconto em todos os modelos por tempo limitado, válido até 31 de agosto de 2025. outros modelos consulte página de preços de escritório.
No CometAPI, a série vem com preços em camadas ligeiramente diferentes, consulte API GLM‑4.5:
| Modelo | introduzir | Preço |
glm-4.5 | Nosso modelo de raciocínio mais poderoso, com 355 bilhões de parâmetros | Tokens de entrada $ 0.48 Tokens de saída $ 1.92 |
glm-4.5-air | Desempenho leve e robusto, com boa relação custo-benefício | Tokens de entrada $ 0.16 Tokens de saída $ 1.07 |
glm-4.5-x | Alto desempenho, raciocínio forte, resposta ultrarrápida | Tokens de entrada $ 1.60 Tokens de saída $ 6.40 |
glm-4.5-airx | Desempenho leve e forte, resposta ultrarrápida | Tokens de entrada $ 0.02 Tokens de saída $ 0.06 |
glm-4.5-flash | Desempenho forte, excelente para codificação de raciocínio e agentes | Tokens de entrada $ 3.20 Tokens de saída $ 12.80 |
Como o preço do GLM 4.5 se compara ao DeepSeek e ao Western LLMs?
Na Conferência Mundial de IA de 2025, a Z.ai posicionou explicitamente o GLM 4.5 como um concorrente do DeepSeek — o líder de custo anterior na China — prometendo "uma fração do custo do token" e metade da pegada de hardware do modelo R1 do DeepSeek.
- DeepSeek R1: Aproximadamente USD 0.14 de entrada, USD 0.60 de saída por milhão de tokens.
- GLM 4.5:Alega-se que o DeepSeek custa entre 20% e 30% menos que o DeepSeek, tanto na entrada quanto na saída.
- Benchmarks ocidentais: O GPT‑4 da OpenAI e o Gemini do Google variam de US$ 3 a US$ 15 por milhão de tokens, posicionando o GLM 4.5 como uma redução de custo de ordem de grandeza.
Essa estratégia de preços reflete o modelo econômico de IA mais amplo da China: computação mais enxuta, modelos menores e preços agressivos para conquistar participação de mercado.
A série GLM 4.5 vale a pena?
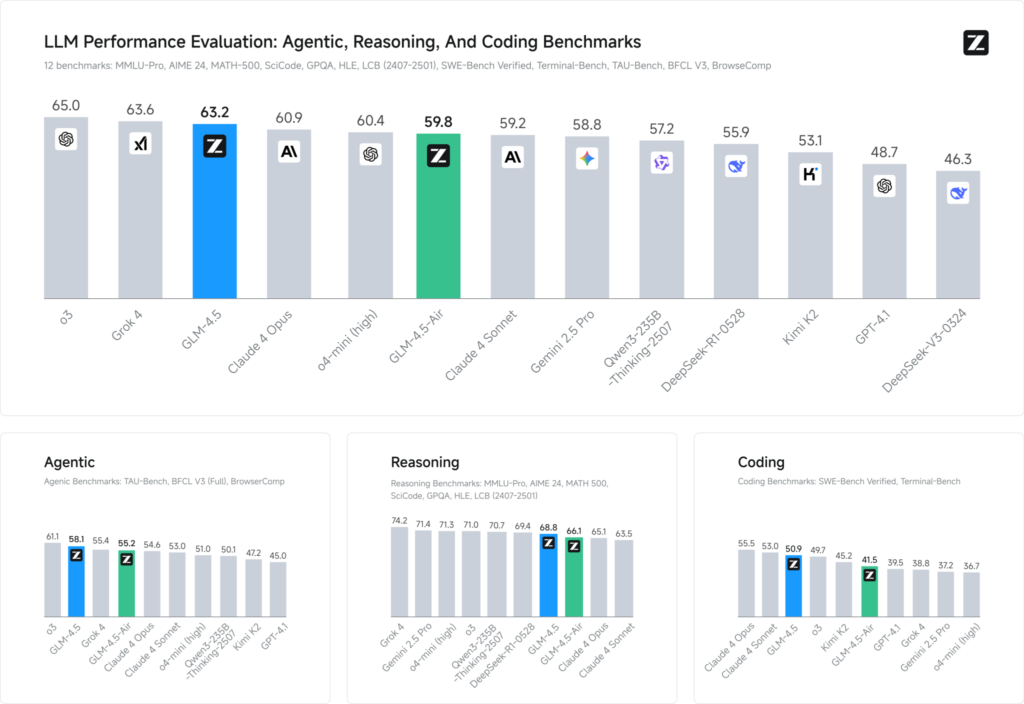
Avaliações de benchmark em 12 conjuntos de dados representativos (abrangendo MMLU Pro, MATH 500, SciCode, Terminal‑Bench e TAU‑Bench) revelam que o GLM 4.5 garante uma classificação global nº 3, atrás do Grok 4 da xAI e do o3 da OpenAI, mas ocupa o primeiro lugar entre as ofertas de código aberto.
Em tarefas de codificação (LiveCodeBench, SWE-Bench), o design Mixture-of-Experts do GLM 4.5 contribui para a qualidade de geração de código de alto nível, enquanto em raciocínio (AIME 24, MMLU Pro), seu planejamento em várias etapas proporciona precisão robusta comparável a equivalentes de código fechado. A variante Air, mais leve, mantém pontuações competitivas dentro de sua faixa de parâmetros (escala 100 B), tornando-a uma opção atraente para implantações de ponta e sistemas embarcados.
Benchmarks de desempenho
- Índice de Inteligência: Pontuação GLM 4.5 66 em um Índice de Inteligência composto (MMLU Pro, MATH 500, AIME 24), superando muitos modelos de código aberto e comerciais de nível médio.
- Latência de inferência: Médias de tempo até o primeiro token 0.89 segundos, competitivo para tarefas de raciocínio complexas, embora ligeiramente mais lento em termos de rendimento (≈45.7 tokens/s) em comparação com alguns modelos otimizados de código fechado.
- Fluxo de trabalho do Agentic: Demonstra domínio robusto do uso de ferramentas multietapas e geração dinâmica de código, com taxas de vitória frente a frente de ~54% contra Kimi K2 e 81% contra Qwen3‑Coder em avaliações de codificação independentes.
Quais casos de uso prático demonstram o ROI?
- Desenvolvimento Full-Stack: O GLM‑4.5 pode estruturar aplicativos web inteiros — desde layouts de front-end em HTML/CSS/JavaScript até esquemas de banco de dados de back-end — por meio de prompts multi-turn, reduzindo os ciclos de prototipagem de dias para horas.
- Análise Complexa de Documentos: A janela de contexto estendida de 128 K permite que empresas jurídicas, financeiras e científicas analisem contratos de várias páginas ou relatórios de pesquisa de uma só vez, reduzindo a sobrecarga de segmentação.
- Fluxos de trabalho automatizados de agentes: A inferência híbrida permite a criação de scripts autônomos (por exemplo, bots de web scraping, agentes de negociação) que raciocinam por meio de processos de várias etapas com intervenção humana mínima.
Estudos de caso quantitativos sugerem até 60 por cento redução nas horas de desenvolvimento para tarefas centradas no código e 40 por cento retorno mais rápido em análises de conteúdo de formato longo.
Quais são as possíveis desvantagens e considerações?
Nenhuma tecnologia está isenta de compensações. Os potenciais adotantes devem estar atentos a fatores regulatórios, operacionais e ecossistêmicos.
Limitações
Suporte e SLAs:Os provedores de código aberto podem não oferecer SLAs de nível empresarial ou suporte 24 horas por dia, 7 dias por semana, ao contrário de suas contrapartes comerciais.
Restrições de rendimento:Embora a janela de contexto seja enorme, as taxas de token por segundo ficam atrás de algumas contrapartes de código fechado otimizadas para inferência, afetando potencialmente aplicativos em tempo real.
Despesas Operacionais: Os modelos MoE de auto-hospedagem exigem uma orquestração cuidadosa (roteamento especializado, gerenciamento de memória) para evitar gargalos de desempenho e estouros de custo.
Quais investimentos em infraestrutura são necessários?
- Pegada de computação: Mesmo com a eficiência do MoE, hospedar a variante padrão do GLM‑4.5 exige GPUs com ≥80 GB de memória e interconexões NVLink robustas para inferência de baixa latência.
- Sobrecarga de ajuste fino: Personalizar o modelo para tarefas específicas de domínio pode exigir ciclos substanciais de GPU, aumentando os custos iniciais antes que as economias no faturamento de tokens se concretizem.
- Manutenção: Implantações no local transferem a responsabilidade por atualizações, patches de segurança e dimensionamento do fornecedor para equipes internas de DevOps.
Como você pode começar a usar o GLM‑4.5?
Embarcar em uma integração do GLM-4.5 envolve algumas etapas simples, especialmente considerando o manual de código aberto e o amplo suporte de terceiros.
Quais APIs e plataformas suportam GLM‑4.5?
- CometAPI API: Ponto de extremidade totalmente compatível com OpenAI, com SDKs em Python, JavaScript e Java.
- Ponto final direto do Z.ai: Oferece suporte oficial e recursos de acesso antecipado, como orquestração multiagente.
- Espelhos Comunitários: Host de rápido crescimento de tempos de execução de código aberto (por exemplo, Ollama, AutoGPT‑CLI) que permitem inferência local.
Onde os desenvolvedores podem encontrar ferramentas e documentação?
- Documentação oficial da Z.ai: Guias abrangentes sobre instalação, engenharia rápida e otimização de MoE.
- Repositórios GitHub: Cadernos de amostra para geração de código, geração aumentada de recuperação (RAG) e estruturas de agentes compatíveis com as principais ferramentas de orquestração.
- Fóruns da comunidade: Fóruns de discussão ativos em plataformas como Hugging Face, onde os profissionais compartilham receitas de ajustes finos, bibliotecas de prompts e benchmarks de desempenho.
Conclusão
A série GLM‑4.5 impõe uma posição ousada no cenário hipercompetitivo de IA atual: custo-benefício incomparável para desenvolvedores, empresas e instituições de pesquisa. Com preços de token a partir de US$ 0.11 por milhão de tokens de entrada e US$ 0.28 por milhão de saídas — ainda mais reduzidos por um desconto promocional de 50% — e desempenho de referência que rivaliza ou supera modelos proprietários maiores, o GLM‑4.5 oferece ROI substancial para aplicações centradas em código, compreensão de formatos longos e fluxos de trabalho agênticos.
Começando a jornada
A CometAPI é uma plataforma de API unificada que agrega mais de 500 modelos de IA de provedores líderes — como a série GPT da OpenAI, a Gemini do Google, a Claude da Anthropic, a Midjourney e a Suno, entre outros — em uma interface única e amigável ao desenvolvedor. Ao oferecer autenticação, formatação de solicitações e tratamento de respostas consistentes, a CometAPI simplifica drasticamente a integração de recursos de IA em seus aplicativos. Seja para criar chatbots, geradores de imagens, compositores musicais ou pipelines de análise baseados em dados, a CometAPI permite iterar mais rapidamente, controlar custos e permanecer independente de fornecedores — tudo isso enquanto aproveita os avanços mais recentes em todo o ecossistema de IA.
Os desenvolvedores podem acessar GLM-4.5 Air API e API GLM‑4.5 através de CometAPI, as versões mais recentes dos modelos Claude listadas são da data de publicação do artigo. Para começar, explore os recursos do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.