

Começar com o Gemini 2.5 Flash-Lite via CometAPI é uma excelente oportunidade para aproveitar um dos modelos de IA generativa mais econômicos e de baixa latência disponíveis atualmente. Este guia combina os anúncios mais recentes do Google DeepMind, especificações detalhadas da documentação do Vertex AI e etapas práticas de integração usando o CometAPI para ajudar você a começar a usar o CometAPI de forma rápida e eficaz.
O que é o Gemini 2.5 Flash-Lite e por que você deve considerá-lo?
Visão geral da família Gemini 2.5
Em meados de junho de 2025, o Google DeepMind lançou oficialmente a série Gemini 2.5, incluindo as versões GA estáveis do Gemini 2.5 Pro e do Gemini 2.5 Flash, juntamente com a prévia de um modelo totalmente novo e leve: o Gemini 2.5 Flash-Lite. Projetada para equilibrar velocidade, custo e desempenho, a série 2.5 representa o esforço do Google para atender a uma ampla gama de casos de uso — desde cargas de trabalho de pesquisa pesadas até implantações em larga escala e com custo reduzido.
Principais características do Flash-Lite
O Flash-Lite se diferencia por oferecer recursos multimodais (texto, imagens, áudio, vídeo) com latência extremamente baixa, com uma janela de contexto que suporta até um milhão de tokens e integrações de ferramentas, incluindo Pesquisa Google, execução de código e chamada de funções. Fundamentalmente, o Flash-Lite introduz o controle de "orçamento de pensamento", permitindo que os desenvolvedores equilibrem a profundidade do raciocínio com o tempo de resposta e o custo, ajustando um parâmetro interno de orçamento de tokens.
Posicionamento na linha de modelos
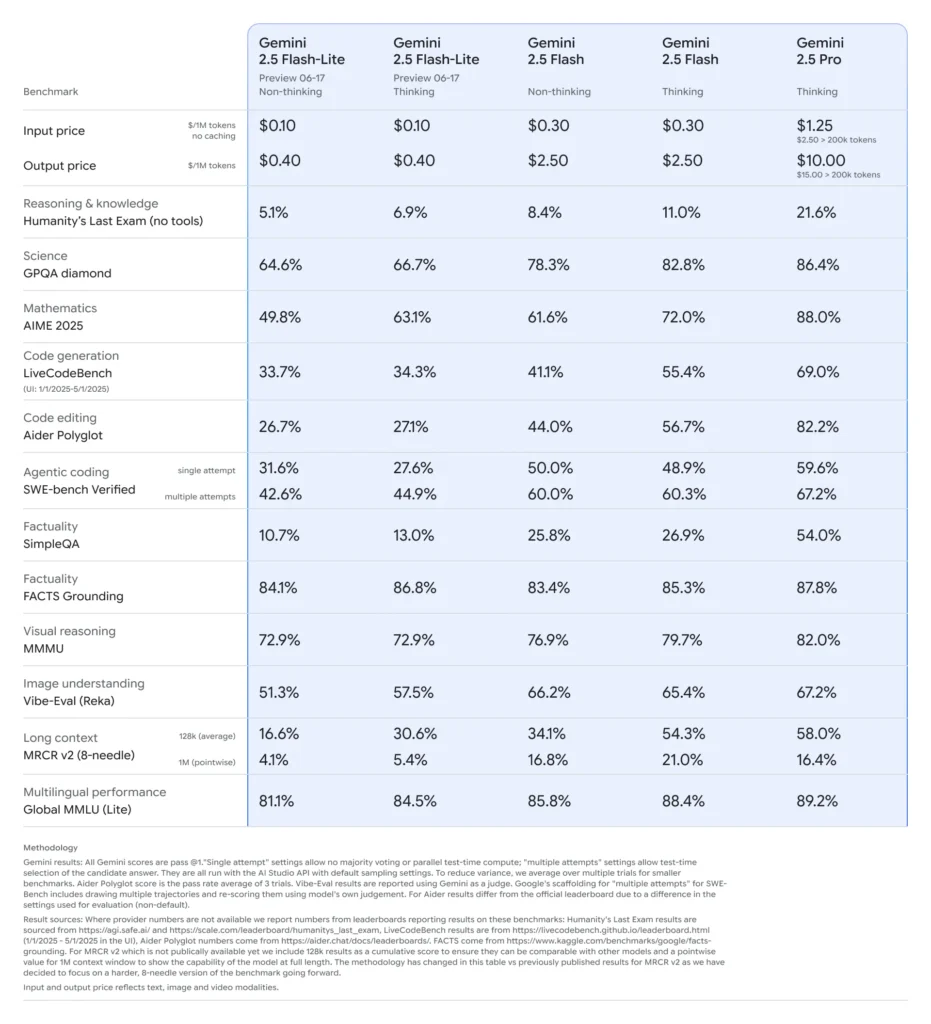
Comparado aos seus similares, o Flash-Lite situa-se na fronteira de Pareto em termos de custo-benefício: com preço aproximado de US$ 0.10 por milhão de tokens de entrada e US$ 0.40 por milhão de tokens de saída durante a pré-visualização, ele supera o Flash (US$ 0.30/US$ 2.50) e o Pro (US$ 1.25/US$ 10), mantendo a maior parte de sua capacidade multimodal e suporte a chamadas de função. Isso torna o Flash-Lite ideal para tarefas de alto volume e baixa complexidade, como sumarização, classificação e agentes conversacionais leves.
Por que os desenvolvedores devem considerar o Gemini 2.5 Flash-Lite?
Benchmarks de desempenho e testes do mundo real
Em comparações diretas, o Flash-Lite demonstrou:
- Taxa de transferência 2× mais rápida do que o Gemini 2.5 Flash em tarefas de classificação.
- 3× economia de custos para pipelines de sumarização em escala empresarial.
- Precisão competitiva em benchmarks de lógica, matemática e código, igualando ou superando as prévias anteriores do Flash-Lite.
Casos de uso ideais
- Chatbots de alto volume: Ofereça experiências de conversação consistentes e de baixa latência para milhões de usuários.
- Geração de conteúdo automatizada: Resumo de documentos em escala, tradução e criação de microcópias.
- Pipelines de pesquisa e recomendação: Aproveite a inferência rápida para personalização em tempo real.
- Processamento de dados em lote: Anote grandes conjuntos de dados com custos mínimos de computação.
Como você obtém e gerencia o acesso à API para o Gemini 2.5 Flash-Lite via CometAPI?
Por que usar o CometAPI como seu gateway?
A CometAPI agrega mais de 500 modelos de IA — incluindo a série Gemini do Google — em um endpoint REST unificado, simplificando a autenticação, a limitação de taxas e o faturamento entre provedores. Em vez de manipular várias URLs base e chaves de API, você direciona todas as solicitações para https://api.cometapi.com/v1, especifique o modelo de destino na carga útil e gerencie o uso por meio de um único painel.
Pré-requisitos e inscrição
- Faça o login no cometapi.com. Se você ainda não é nosso usuário, registre-se primeiro
- Obtenha a chave de API da credencial de acesso da interface. Clique em "Adicionar Token" no token da API no centro pessoal, obtenha a chave de token: sk-xxxxx e envie.
- Obtenha a URL deste site: https://api.cometapi.com/
Gerenciando seus tokens e cotas
O painel da CometAPI fornece cotas de token unificadas que podem ser compartilhadas entre Google, OpenAI, Anthropic e outros modelos. Use as ferramentas de monitoramento integradas para definir alertas de uso e limites de taxa para nunca exceder as alocações orçadas ou incorrer em cobranças inesperadas.
Como você configura seu ambiente de desenvolvimento para integração do CometAPI?
Instalando dependências necessárias
Para integração com o Python, instale os seguintes pacotes:
pip install openai requests pillow
- openai: SDK compatível para comunicação com CometAPI.
- pedidos: Para operações HTTP, como download de imagens.
- travesseiro: Para tratamento de imagens ao enviar entradas multimodais.
Inicializando o cliente CometAPI
Use variáveis de ambiente para manter sua chave de API fora do código-fonte:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Esta instância do cliente agora pode ter como alvo qualquer modelo suportado especificando seu ID (por exemplo, gemini-2.5-flash-lite-preview-06-17) em suas solicitações.
Configurando orçamento de pensamento e outros parâmetros
Ao enviar uma solicitação, você pode incluir parâmetros opcionais:
- temperatura/top_p: Controle a aleatoriedade na geração.
- Contagem de candidatos: Número de saídas alternativas.
- max_tokens: Limite de token de saída.
- orçamento_pensamento: Parâmetro personalizado para Flash-Lite para compensar profundidade por velocidade e custo.
Como é uma solicitação básica para o Gemini 2.5 Flash-Lite via CometAPI?
Exemplo somente de texto
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Esta chamada retorna um resumo sucinto em menos de 200 ms, ideal para chatbots ou pipelines de análise em tempo real.
Exemplo de entrada multimodal
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
O Flash-Lite processa imagens de até 7 MB e retorna descrições contextuais, tornando-o adequado para compreensão de documentos, análise de interface do usuário e relatórios automatizados.
Como você pode aproveitar recursos avançados, como streaming e chamada de função?
Respostas de streaming para aplicações em tempo real
Para interfaces de chatbot ou legendas ao vivo, use a API de streaming:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Isso fornece saídas parciais conforme elas se tornam disponíveis, reduzindo a latência percebida em interfaces de usuário interativas.
Função que chama saída de dados estruturados
Defina esquemas JSON para impor respostas estruturadas:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Essa abordagem garante saídas compatíveis com JSON, simplificando pipelines de dados downstream e integrações.
Como você otimiza o desempenho, o custo e a confiabilidade ao usar o Gemini 2.5 Flash-Lite?
Ajuste de orçamento de pensamento
O parâmetro de orçamento de pensamento do Flash-Lite permite que você ajuste a quantidade de "esforço cognitivo" que o modelo despende. Um orçamento baixo (por exemplo, 0) prioriza velocidade e custo, enquanto valores mais altos geram um raciocínio mais aprofundado em detrimento da latência e dos tokens.
Gerenciando limites de token e rendimento
- Tokens de entrada: Até 1,048,576 tokens por solicitação.
- Tokens de saída: Limite padrão de 65,536 tokens.
- Entradas multimodais: Até 500 MB em ativos de imagem, áudio e vídeo.
Implemente o processamento em lote do lado do cliente para cargas de trabalho de alto volume e aproveite o dimensionamento automático do CometAPI para lidar com tráfego intermitente sem intervenção manual.
Estratégias de eficiência de custos
- Reúna tarefas de baixa complexidade no Flash-Lite e reserve o Pro ou o Flash padrão para trabalhos pesados.
- Use limites de taxa e alertas de orçamento no painel CometAPI para evitar gastos descontrolados.
- Monitore o uso por ID do modelo para comparar o custo por solicitação e ajustar sua lógica de roteamento adequadamente.
Quais são as melhores práticas e os próximos passos após a integração inicial?
Monitoramento, registro e segurança
- Logging: Capture metadados de solicitação/resposta (registros de data e hora, latências, uso de token) para auditorias de desempenho.
- Alertas: Configure notificações de limite para taxas de erro ou estouros de custo no CometAPI.
- Segurança: Gire as chaves de API regularmente e armazene-as em cofres seguros ou variáveis de ambiente.
Padrões comuns de uso
- Chatbots: Use o Flash-Lite para consultas rápidas do usuário e recorra ao Pro para acompanhamentos complexos.
- Processamento de documentos: Análises em lote de PDF ou imagens durante a noite com um orçamento mais baixo.
- Análise em tempo real: Transmita dados financeiros ou operacionais para obter insights instantâneos por meio da API de streaming.
Explorando mais a fundo
- Experimente com prompts híbridos: combine entradas de texto e imagem para obter um contexto mais rico.
- Protótipo RAG (Retrieval-Augmented Generation) integrando ferramentas de busca vetorial com Gemini 2.5 Flash-Lite.
- Faça uma análise comparativa com ofertas concorrentes (por exemplo, GPT-4.1, Claude Sonnet 4) para validar compensações de custo e desempenho.
Escalonamento na produção
- Aproveite o nível empresarial da CometAPI para pools de cotas dedicados e garantias de SLA.
- Implemente estratégias de implantação azul-verde para testar novos prompts ou orçamentos sem interromper usuários ativos.
- Revise regularmente as métricas de uso do modelo para identificar oportunidades de maior economia de custos ou melhorias de qualidade.
Começando a jornada
A CometAPI fornece uma interface REST unificada que agrega centenas de modelos de IA — em um endpoint consistente, com gerenciamento de chaves de API, cotas de uso e painéis de faturamento integrados. Em vez de lidar com várias URLs e credenciais de fornecedores.
Os desenvolvedores podem acessar API Gemini 2.5 Flash-Lite (prévia)(Modelo: gemini-2.5-flash-lite-preview-06-17) Através CometAPI, os modelos mais recentes listados são da data de publicação do artigo. Para começar, explore as capacidades do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.
Em apenas alguns passos, você pode integrar o Gemini 2.5 Flash-Lite via CometAPI aos seus aplicativos, desbloqueando uma poderosa combinação de velocidade, acessibilidade e inteligência multimodal. Seguindo as diretrizes acima — que abrangem configuração, solicitações básicas, recursos avançados e otimização — você estará bem posicionado para oferecer experiências de IA de última geração aos seus usuários. O futuro da IA de alto rendimento e baixo custo já chegou: comece a usar o Gemini 2.5 Flash-Lite hoje mesmo.