

Em 2025–2026, o panorama das ferramentas de IA continuou a se consolidar: as APIs de gateway (como a CometAPI) se expandiram para oferecer acesso no estilo OpenAI a centenas de modelos, enquanto os aplicativos LLM para usuários finais (como o AnythingLLM) continuaram aprimorando seu provedor “Generic OpenAI” para permitir que aplicativos desktop e local-first chamem qualquer endpoint compatível com OpenAI. Isso torna simples, hoje, rotear o tráfego do AnythingLLM pela CometAPI e obter os benefícios de escolha de modelo, roteamento por custo e faturamento unificado — enquanto ainda utiliza a interface local e os recursos de RAG/agente do AnythingLLM.
O que é o AnythingLLM e por que você gostaria de conectá-lo à CometAPI?
O que é o AnythingLLM?
AnythingLLM é um aplicativo de IA open-source, tudo-em-um, e um cliente local/em nuvem para criar assistentes de chat, fluxos de trabalho de geração aumentada por recuperação (RAG) e agentes orientados por LLM. Ele oferece uma interface elegante, uma API para desenvolvedores, recursos de workspace/agente e suporte a LLMs locais e em nuvem — projetado para ser privado por padrão e extensível via plugins. O AnythingLLM expõe um provedor Generic OpenAI que permite conversar com APIs de LLM compatíveis com OpenAI.
O que é a CometAPI?
CometAPI é uma plataforma comercial de agregação de APIs que expõe mais de 500 modelos de IA por meio de uma interface REST no estilo OpenAI e faturamento unificado. Na prática, ela permite chamar modelos de vários fornecedores (OpenAI, Anthropic, variantes do Google/Gemini, modelos de imagem/áudio etc.) pelos mesmos endpoints https://api.cometapi.com/v1 e com uma única chave de API (formato sk-xxxxx). A CometAPI oferece suporte a endpoints padrão no estilo OpenAI, como /v1/chat/completions, /v1/embeddings etc., o que facilita a adaptação de ferramentas que já oferecem suporte a APIs compatíveis com OpenAI.
Por que integrar o AnythingLLM com a CometAPI?
Três razões práticas:
- Escolha de modelo e flexibilidade de fornecedor: O AnythingLLM pode usar “qualquer” LLM compatível com OpenAI por meio do wrapper Generic OpenAI. Apontar esse wrapper para a CometAPI dá acesso imediato a centenas de modelos sem alterar a interface ou os fluxos do AnythingLLM.
- Otimização de custos/operações: Usar a CometAPI permite trocar modelos (ou mudar para opções mais baratas) de forma centralizada para controlar custos, além de manter um faturamento unificado em vez de gerenciar várias chaves de provedores.
- Experimentação mais rápida: Você pode fazer testes A/B com diferentes modelos (por exemplo,
gpt-4o,gpt-4.5, variantes do Claude ou modelos multimodais open-source) pela mesma interface do AnythingLLM — útil para agentes, respostas RAG, sumarização e tarefas multimodais.
Quais ambientes e condições você deve preparar antes da integração
Requisitos de sistema e software (alto nível)
- Desktop ou servidor executando o AnythingLLM (Windows, macOS, Linux) — instalação desktop ou instância auto-hospedada. Confirme que você está em uma versão recente que exponha as configurações LLM Preferences / AI Providers.
- Conta na CometAPI e uma chave de API (o segredo no estilo
sk-xxxxx). Você usará esse segredo no provedor Generic OpenAI do AnythingLLM. - Conectividade de rede da sua máquina para
https://api.cometapi.com(sem firewall bloqueando HTTPS de saída). - Opcional, mas recomendado: um ambiente moderno em Python ou Node para testes (Python 3.10+ ou Node 18+), curl e um cliente HTTP (Postman / HTTPie) para verificar a CometAPI antes de conectá-la ao AnythingLLM.
Condições específicas do AnythingLLM
O provedor de LLM Generic OpenAI é a rota recomendada para endpoints que imitam a superfície de API da OpenAI. A documentação do AnythingLLM alerta que esse provedor é voltado para desenvolvedores e que você deve entender os dados que fornece. Se você usar streaming ou se o endpoint não oferecer suporte a streaming, o AnythingLLM inclui uma configuração para desativar o streaming para Generic OpenAI.
Checklist de segurança e operação
- Trate a chave da CometAPI como qualquer outro segredo — não a envie para repositórios; armazene-a em keychains do sistema operacional ou variáveis de ambiente, quando possível.
- Se você pretende usar documentos sensíveis em RAG, certifique-se de que as garantias de privacidade do endpoint atendem às suas necessidades de conformidade (verifique a documentação/termos da CometAPI).
- Defina limites máximos de tokens e de janela de contexto para evitar custos fora de controle.
Como configurar o AnythingLLM para usar a CometAPI (passo a passo)?
Abaixo está uma sequência concreta de passos — seguida por exemplos de variáveis de ambiente e trechos de código para testar a conexão antes de salvar as configurações na interface do AnythingLLM.
Passo 1 — Obtenha sua chave da CometAPI
- Cadastre-se ou faça login na CometAPI.
- Vá até “API Keys” e gere uma chave — você receberá uma string com aparência de
sk-xxxxx. Mantenha-a em segredo.
Passo 2 — Verifique se a CometAPI funciona com uma requisição rápida
Use curl ou Python para chamar um endpoint simples de chat completion e confirmar a conectividade.
Exemplo com curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \
-H "Authorization: Bearer sk-xxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o",
"messages": ,
"max_tokens": 50
}'
Se isso retornar um 200 e uma resposta JSON com um array choices, sua chave e sua rede estão funcionando. (A documentação da CometAPI mostra a superfície e os endpoints no estilo OpenAI).
Exemplo em Python (requests)
import requests
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": "Bearer sk-xxxxx", "Content-Type": "application/json"}
payload = {
"model": "gpt-4o",
"messages": ,
"max_tokens": 64
}
r = requests.post(url, json=payload, headers=headers, timeout=15)
print(r.status_code, r.json())
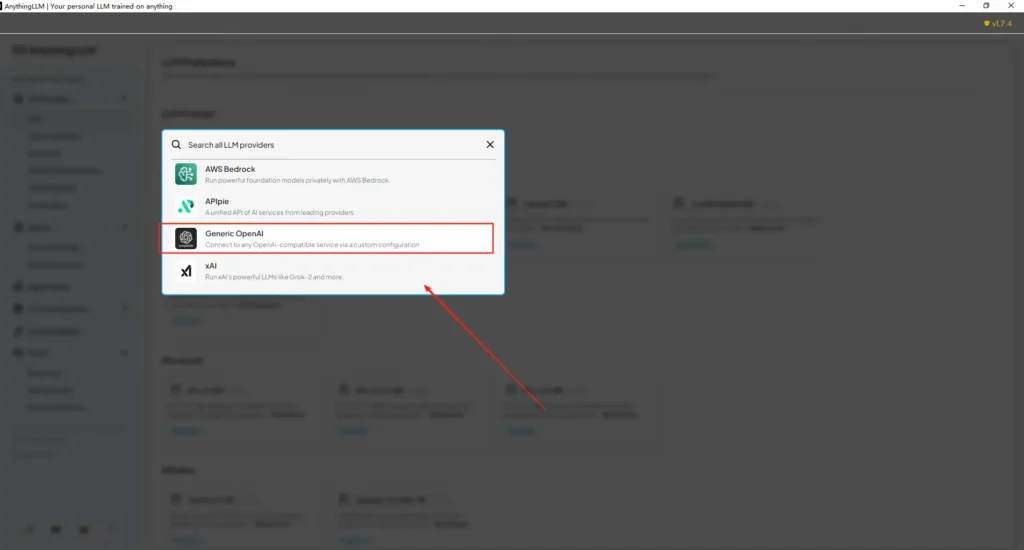
Passo 3 — Configure o AnythingLLM (UI)
Abra o AnythingLLM → Settings → AI Providers → LLM Preferences (ou caminho semelhante na sua versão). Use o provedor Generic OpenAI e preencha os campos da seguinte forma:
Configuração de API (exemplo)
• Entre no menu de configurações do AnythingLLM e localize LLM Preferences em AI Providers.
• Selecione Generic OpenAI como provedor de modelo e insirahttps://api.cometapi.com/v1no campo de URL.
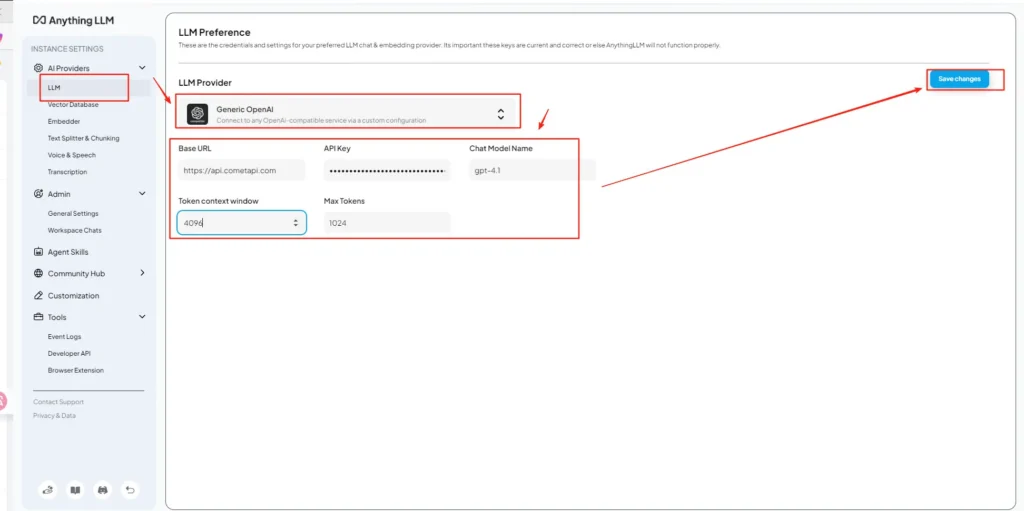
• Cole osk-xxxxxda CometAPI na caixa de entrada da chave de API. Preencha Token context window e Max Tokens de acordo com o modelo real. Você também pode personalizar os nomes dos modelos nesta página, como adicionar o modelogpt-4o.
Isso está alinhado com a orientação de “Generic OpenAI” do AnythingLLM (wrapper para desenvolvedores) e com a abordagem de URL base compatível com OpenAI da CometAPI.
Passo 4 — Defina nomes de modelos e limites de tokens
Na mesma tela de configurações, adicione ou personalize os nomes dos modelos exatamente como a CometAPI os publica (por exemplo, gpt-4o, minimax-m2, kimi-k2-thinking), para que a interface do AnythingLLM possa apresentar esses modelos aos usuários. A CometAPI publica strings de modelo para cada fornecedor.
Passo 5 — Teste no AnythingLLM
Inicie um novo chat ou use um workspace existente, selecione o provedor Generic OpenAI (se você tiver vários provedores), escolha um dos nomes de modelo da CometAPI que você adicionou e execute um prompt simples. Se você obtiver respostas coerentes, a integração está concluída.
Como o AnythingLLM usa essas configurações internamente
O wrapper Generic OpenAI do AnythingLLM constrói requisições no estilo OpenAI (/v1/chat/completions, /v1/embeddings), portanto, assim que você apontar a URL base e fornecer a chave da CometAPI, o AnythingLLM roteará chats, chamadas de agente e requisições de embeddings pela CometAPI de forma transparente. Se você usar agentes do AnythingLLM (os fluxos @agent), eles herdarão o mesmo provedor.
Quais são as melhores práticas e possíveis armadilhas?
Melhores práticas
- Use configurações de contexto adequadas ao modelo: Ajuste a Token Context Window e o Max Tokens do AnythingLLM ao modelo escolhido na CometAPI. Incompatibilidades levam a truncamento inesperado ou falhas nas chamadas.
- Proteja suas chaves de API: Armazene chaves da CometAPI em variáveis de ambiente e/ou em Kubernetes/gerenciadores de segredos; nunca as envie para o git. O AnythingLLM armazenará chaves em suas configurações locais se você inseri-las na interface — trate o armazenamento do host como sensível.
- Comece com modelos menores/mais baratos para fluxos de experimento: Use a CometAPI para testar modelos de menor custo no desenvolvimento e reserve modelos premium para produção. A CometAPI anuncia explicitamente troca por custo e faturamento unificado.
- Monitore o uso e configure alertas: A CometAPI oferece painéis de uso — defina orçamentos/alertas para evitar cobranças inesperadas.
- Teste agentes e ferramentas isoladamente: Agentes do AnythingLLM podem disparar ações; teste-os com prompts seguros e em instâncias de staging primeiro.
Armadilhas comuns
- Conflitos entre UI e
.env: Ao auto-hospedar, as configurações da interface podem sobrescrever alterações no.env(e vice-versa). Verifique o/app/server/.envgerado se as coisas voltarem ao estado anterior após reiniciar. Problemas relatados pela comunidade mencionam redefinições deLLM_PROVIDER. - Incompatibilidade de nomes de modelos: Usar um nome de modelo não disponível na CometAPI causará um 400/404 do gateway. Sempre confirme os modelos disponíveis na lista de modelos da CometAPI.
- Limites de tokens e streaming: Se você precisar de respostas em streaming, verifique se o modelo da CometAPI oferece suporte a streaming (e se a versão da interface do AnythingLLM oferece suporte a isso). Alguns provedores diferem na semântica de streaming.
Quais casos de uso reais essa integração viabiliza?
Retrieval-Augmented Generation (RAG)
Use os carregadores de documentos + banco de dados vetorial do AnythingLLM com LLMs da CometAPI para gerar respostas contextualizadas. Você pode experimentar embeddings baratos + modelos de chat caros, ou manter tudo na CometAPI para faturamento unificado. Os fluxos de RAG do AnythingLLM são um recurso principal nativo.
Automação com agentes
O AnythingLLM oferece suporte a fluxos @agent (navegar por páginas, chamar ferramentas, executar automações). Roteando as chamadas LLM dos agentes pela CometAPI, você ganha liberdade de escolha de modelos para etapas de controle/interpretação sem modificar o código do agente.
Testes A/B multimodelo e otimização de custos
Troque modelos por workspace ou recurso (por exemplo, gpt-4o para respostas de produção, gpt-4o-mini para desenvolvimento). A CometAPI torna as trocas de modelo triviais e centraliza os custos.
Pipelines multimodais
A CometAPI oferece modelos de imagem, áudio e especializados. O suporte multimodal do AnythingLLM (via provedores), combinado com os modelos da CometAPI, permite fluxos de legendagem de imagens, sumarização multimodal ou transcrição de áudio pela mesma interface.
Conclusão
A CometAPI continua a se posicionar como um gateway multimodelo (mais de 500 modelos, API no estilo OpenAI) — o que a torna uma parceira natural para aplicativos como o AnythingLLM, que já oferecem suporte a um provedor Generic OpenAI. Da mesma forma, o provedor Generic do AnythingLLM e suas opções recentes de configuração tornam simples a conexão com esse tipo de gateway. Essa convergência simplifica a experimentação e a migração para produção no fim de 2025.
Como começar a usar a Comet API
CometAPI é uma plataforma de API unificada que agrega mais de 500 modelos de IA de provedores líderes — como a série GPT da OpenAI, Gemini do Google, Claude da Anthropic, Midjourney, Suno e outros — em uma única interface amigável para desenvolvedores. Ao oferecer autenticação consistente, formatação de requisições e tratamento de respostas padronizados, a CometAPI simplifica drasticamente a integração de recursos de IA em seus aplicativos. Quer você esteja criando chatbots, geradores de imagens, compositores de música ou pipelines analíticos orientados por dados, a CometAPI permite iterar mais rapidamente, controlar custos e permanecer independente de fornecedor — tudo isso enquanto aproveita os avanços mais recentes em todo o ecossistema de IA.
Para começar, explore os recursos dos modelos da CometAPI no Playground e consulte o guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login na CometAPI e obtido a chave de API. A CometAPI oferece um preço muito inferior ao preço oficial para ajudar na sua integração.
Pronto para começar?→ Cadastre-se na CometAPI hoje !
Se você quiser saber mais dicas, guias e notícias sobre IA, siga-nos no VK, X e Discord!