

MiniMax-M2.5 é um novo modelo de linguagem de grande porte, com foco em produtividade, da MiniMax, otimizado para programação, uso de ferramentas orientado a agentes e fluxos de trabalho de escritório. Você pode chamá-lo por meio da plataforma nativa MiniMax ou por agregadores de API como o CometAPI. Você só precisa obter a chave de API do CometAPI para usar a API, já que o Minimax-M2.5 também oferece suporte ao formato de chat.
O que é o MiniMax-M2.5?
MiniMax-M2.5 é o mais recente grande lançamento de modelo da MiniMax: uma evolução da família M2 que a empresa posiciona como um modelo de uso geral, com capacidade de agentes e desempenho particularmente forte em geração de código, uso de ferramentas e raciocínio em múltiplas etapas. A família M2.5 foi anunciada como um lançamento de fevereiro de 2026 e inclui as variantes padrão M2.5 e “highspeed”, otimizadas para menor latência mantendo as mesmas capacidades centrais. A família M2.5 melhorou as pontuações de benchmark em avaliações de engenharia de software e apresentou melhor comportamento ao interagir com ferramentas externas (busca, agentes, etc.).
O fornecedor posiciona o M2.5 como um avanço em relação às versões M2.x anteriores, com raciocínio mais forte, melhor geração de código e confiabilidade aprimorada nas chamadas de ferramentas. As notas públicas de lançamento da MiniMax do início de fevereiro de 2026 destacaram o M2.5 como um marco: ajuste de instruções refinado, compreensão de código mais robusta e ganhos mensuráveis em vários benchmarks focados em código. O lançamento inclui:
- Um modelo M2.5 padrão (com ênfase em precisão e raciocínio).
- Uma variante M2.5-highspeed com menor latência para fluxos de trabalho interativos de desenvolvimento.
- Diretrizes explícitas e opções de cobrança para um “Coding Plan” voltado para uso intensivo de geração de código.
Principais destaques técnicos
- Arquitetura: MoE (grande contagem total de parâmetros com um conjunto ativo muito menor durante a inferência), possibilitando um ponto de equilíbrio custo/desempenho para tarefas pesadas.
- Pontos fortes: desempenho de codificação de última geração, raciocínio multi-turn, tratamento de contexto longo e integrações com agentes/ferramentas.
- Variações: a MiniMax publica variantes (por exemplo,
MiniMax-M2.5eM2.5-highspeed) ajustadas para throughput vs. latência.
Por que isso importa hoje: muitas equipes que constroem ferramentas para desenvolvedores, assistentes de programação e automações orientadas a agentes valorizam um modelo que consegue raciocinar em múltiplas voltas, chamar ferramentas com segurança e produzir código de alta qualidade. O M2.5 — em virtude da arquitetura e das escolhas de treinamento — é explicitamente comercializado para esses cenários.
Benchmarking do MiniMax-M2.5
Onde o M2.5 se posiciona em benchmarks específicos de codificação
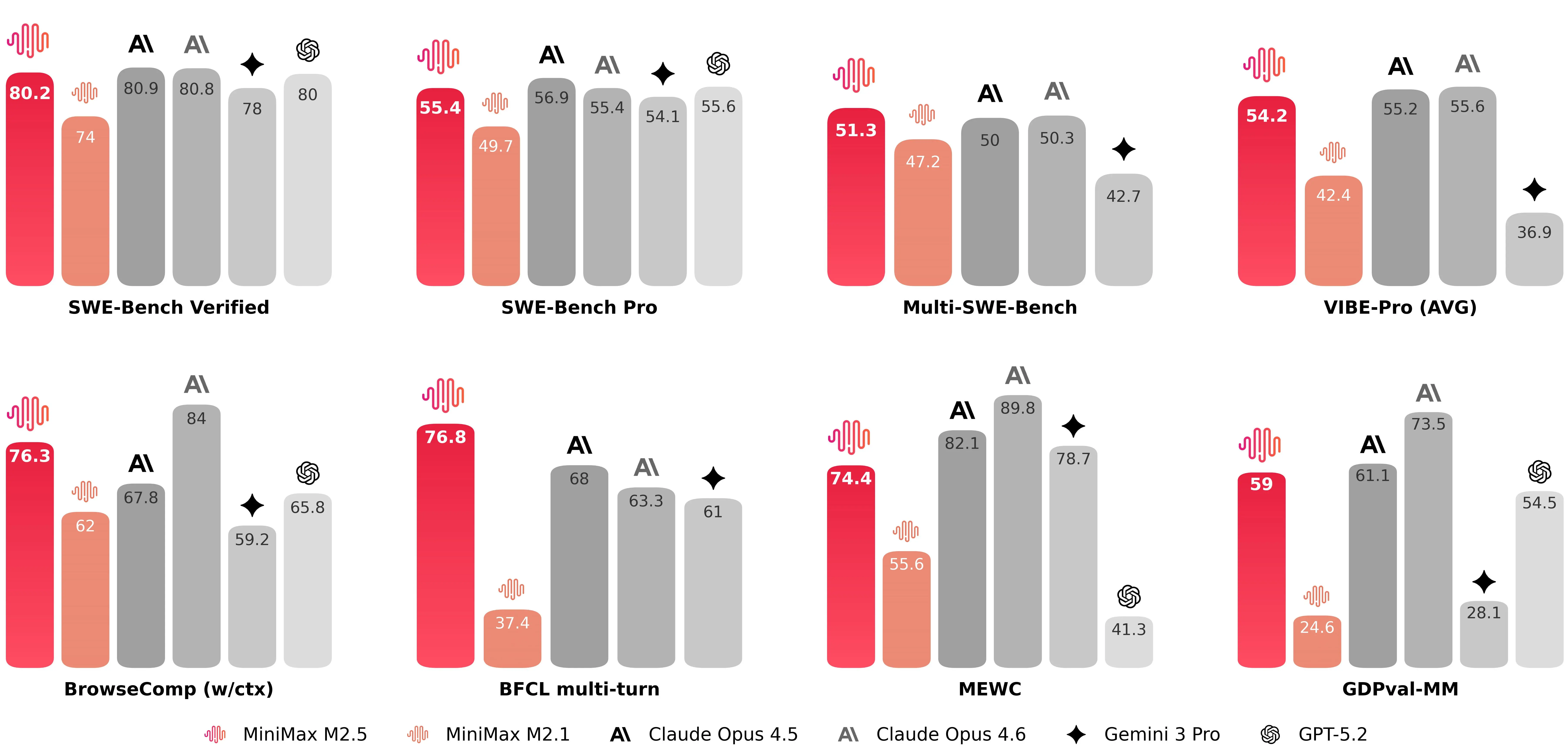
MiniMax-M2.5 obteve pontuação de 80,2% no SWE-Bench Verified, junto com marcas fortes em benchmarks de codificação multitarefa e com navegação aumentada (números notáveis divulgados pela empresa incluem 51,3% no Multi-SWE-Bench e 76,3% no BrowseComp quando o gerenciamento de contexto está ativado). Esses números posicionam o M2.5 entre os modelos publicamente disponíveis com maior desempenho em geração de código e resolução de problemas no lançamento. O lançamento do MiniMax-M2.5 corrobora que o M2.5 está competindo com o nível superior de modelos de codificação.
Para desenvolvedores, o benefício é duplo:
- Maior taxa de sucesso na primeira tentativa: menos rodadas de correções, menos depuração humana e menor sobrecarga de “supervisão” para agentes de codificação autônomos.
- Melhor cobertura full-stack: o M2.5 é descrito como compatível com fluxos de trabalho full-stack em aplicativos desktop, mobile e cadeias de ferramentas multiplataforma, o que significa que ele busca gerar não apenas trechos, mas soluções coerentes de múltiplos arquivos e scripts de build.
Feito para fluxos orientados a agentes
O M2.5 é descrito como “projetado nativamente para cenários de Agente”. Na prática, isso significa que a arquitetura e o regime de treinamento priorizam:
- Fidelidade na invocação de ferramentas: emitir chamadas de API ou executar comandos de shell/SQL com a sintaxe e parâmetros corretos.
- Troca de contexto e memória: continuar uma operação multietapas interrompida sem perder o estado previamente computado.
- Manipulação de arquivos: produzir e editar formatos comuns de escritório de forma programática (por exemplo, gerar um PowerPoint e depois revisá-lo com base em um pedido de acompanhamento).
Busca e navegação aumentadas
Quando o M2.5 é pareado com camadas de navegação ou recuperação, a MiniMax relata pontuações marcadamente melhores em benchmarks de navegação, refletindo desempenho mais forte na integração de informações externas e citações nas saídas. Isso torna o M2.5 adequado para ferramentas que precisam buscar conteúdo atualizado, conferir resultados de API ou aumentar a geração de código com dados do mundo real (por exemplo, buscar a documentação mais recente do SDK e usá-la corretamente durante a geração de código). Essas capacidades importam para equipes que constroem recursos “orientados a agentes”, como QA automatizado, cadeias de CI ou assistentes dirigidos a documentos.

Como posso usar a API do MiniMax-2.5 (via CometAPI)?
CometAPI é uma plataforma agregadora de APIs que expõe centenas de modelos por meio de uma única superfície REST compatível com OpenAI. Como a interface do CometAPI espelha os endpoints de chat/completions da OpenAI, você frequentemente pode reutilizar clientes no estilo OpenAI apenas trocando o api_base e a chave de API. Se preferir não integrar diretamente com a plataforma MiniMax (por motivos como faturamento unificado, A/B testing multi-modelo ou abstração do fornecedor), você pode chamar o MiniMax-M2.5 pela superfície de “chat” do CometAPI. A plataforma CometAPI fornece um formato de requisição consistente, um SDK e um playground web — e expõe nomes e parâmetros por modelo (para que você selecione a string exata de provedor/modelo ao chamar).
Abaixo está um guia conciso e prático para chamar o MiniMax-M2.5 via CometAPI, com exemplos em curl e Python.
Quais são as etapas básicas para começar?
- Cadastre-se em uma conta CometAPI e obtenha uma chave de API. (O CometAPI fornece um playground e SDKs para testar modelos.)
- Verifique a lista de modelos do CometAPI ou o playground do CometAPI para encontrar o nome exato do modelo para MiniMax-M2.5.
- Faça uma requisição POST autenticada com o parâmetro
modeldefinido para o modelo MiniMax selecionado e um payload seguindo o esquema de chat/completion do CometAPI. - Ajuste parâmetros (temperature, max_tokens, mensagens de sistema, streaming) conforme seu fluxo de trabalho.
Autenticação e noções básicas de endpoint
- Base URL:
https://api.cometapi.com/v1(caminhos no estilo OpenAI, como/chat/completions, são suportados). - Header:
Authorization: Bearer YOUR_COMETAPI_KEY - Content-Type:
application/json - Campo de modelo: use a string exata do modelo do catálogo do CometAPI (exemplos:
"minimax-m2.5")
Exemplo 1 — curl rápido (REST, estilo OpenAI)
# Replace $COMETAPI_KEY with your CometAPI key
curl -s -X POST "https://api.cometapi.com/v1/chat/completions" \
-H "Authorization: Bearer $COMETAPI_KEY" \
-H "Content-Type: "application/json" \
-d '{
"model": "minimax-m2.5",
"messages": [
{"role":"system","content":"You are a concise, safety-conscious coding assistant."},
{"role":"user","content":"Refactor this synchronous Python function to async and add basic error handling:\n\n```\ndef fetch(user_id):\n resp = http_get(f\"https://api.example.com/users/{user_id}\")\n return resp.json()\n```"}
],
"max_tokens": 800,
"temperature": 0.0,
"stream": false
}'
Observações:
- Use a string do modelo exatamente como mostrado no catálogo do CometAPI; s.
stream: trueé suportado para streaming de saídas (lidar com Server-Sent Events ou respostas em blocos se você quiser tokens parciais).
Exemplo 2 — Python (requests) para um chat completion
import os, requests
COMET_KEY = os.environ.get("COMETAPI_KEY") # recommended
URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {COMET_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": "minimax-m2.5", # or "minimax/minimax-m2.5" — verify Comet's model page
"messages": [
{"role": "system", "content": "You are a helpful engineer who returns clear, tested code."},
{"role": "user", "content": "Write a pytest for the following function that asserts edge cases..."}
],
"temperature": 0.1,
"max_tokens": 1000,
}
r = requests.post(URL, json=payload, headers=headers, timeout=120)
r.raise_for_status()
out = r.json()
print(out["choices"][0]["message"]["content"])
Exemplo 3 — Usando litellm / integração com CometAPI (camada de conveniência em Python)
O CometAPI é suportado por vários SDKs e adaptadores da comunidade. A documentação do liteLLM mostra um fluxo compacto em que você define COMETAPI_KEY e chama o modelo pelo nome. Isso é ótimo para prototipagem:
import os
from litellm import completion
os.environ["COMETAPI_KEY"] = "your_cometapi_key_here"
messages = [{"role":"user", "content":"Explain async/await in Python in 3 bullets."}]
resp = completion(model="minimax-m2.5", messages=messages)
print(resp.choices[0].message.content)
As integrações Litellm / Comet fornecem utilitários úteis (streaming, async, parâmetro explícito api_key) que espelham muitos padrões dos SDKs da OpenAI.
Como você deve projetar prompts e mensagens de sistema para o M2.5
Seja explícito sobre a função e as restrições
Dê ao M2.5 um papel claro ao pedir código. Exemplo:
{"role": "system","content": "You are MiniMax M2.5, an assistant specialized in robust, readable, and well-documented code. Use Python 3.11 conventions, include type hints, and provide brief unit tests."}
Use decomposição em etapas para problemas complexos
Ao pedir que o M2.5 implemente recursos complexos, use uma decomposição curta:
- Peça um esboço de design.
- Solicite assinaturas de interfaces.
- Peça implementação e testes.
Isso reduz o risco de alucinações e gera saídas modulares e revisáveis.
Temperature, max_tokens e segurança
- Para código determinístico: defina
temperaturepróximo de 0.0. - Para design exploratório:
temperatureentre 0,2–0,5 pode trazer abordagens criativas. - Mantenha
max_tokensgeneroso para grandes refatorações ou suítes de teste longas.
Peça testes unitários e explicação
Ao solicitar código, peça também testes unitários e uma explicação curta do algoritmo. Isso ajuda você a detectar bugs sutis e obter artefatos executáveis na primeira tentativa.
Inferência de tarefas longas e rastreamento de estado
O modelo M2.5 conta com um excelente mecanismo de rastreamento de estado, garantindo efetivamente a continuidade e a direcionalidade do pensamento ao longo de longas sequências de tempo, concentrando-se em um número limitado de objetivos de cada vez em vez de processar tudo em paralelo. O M2.5 possui funcionalidades com reconhecimento de contexto, possibilitando execução eficiente de tarefas e gerenciamento otimizado de contexto.
Dicas práticas de uso do M2.5 em produção
MiniMax-M2.5 é ajustado para ferramentas multietapas e código. Abaixo estão dicas práticas, baseadas em experiência, para obter os melhores resultados em produção.
Engenharia de prompts e mensagens de sistema
- Use mensagens de sistema explícitas para papel e restrições. Para tarefas de código, inclua o runtime/frameworks de teste exigidos (por exemplo, “Retorne um pytest compatível com Python 3.11”).
- Forneça contexto: para trabalhos orientados a agentes ou multietapas, inclua metadados de etapas e descrições de ferramentas como JSON estruturado ou listas com marcadores. O M2.5 responde bem a entradas estruturadas porque é otimizado para uso de ferramentas.
Chamada de função/ferramenta
- Se estiver usando o CometAPI como gateway para chamadas de ferramentas, garanta que seus campos extras (por exemplo,
function_callno estilo OpenAI) correspondam às expectativas do CometAPI/modelo. Confirme o suporte do modelo na página do Comet, pois a semântica de ferramentas pode variar por provedor. - Para orquestração robusta, divida grandes tarefas em chamadas menores e mantenha checkpoints determinísticos. O M2.5 é forte em seguir instruções multietapas, mas você obterá o comportamento mais confiável validando após cada etapa.
Temperature, max_tokens e controle de custos
- Para geração ou refatoração de código, defina
temperaturebaixa (0,0–0,2) e usemax_tokensdimensionado ao tamanho esperado da saída. - Para prompts exploratórios, aumente
temperature, mas monitore o uso de tokens. Ao rotear via CometAPI, compare o preço do provedor e regras de fallback — o CometAPI lista preços por token por instância de modelo em seu catálogo.
Janela de contexto e documentos longos
- As variantes do M2.5 frequentemente suportam contextos longos (verifique a especificação do modelo para o comprimento do contexto). Para documentos muito longos, faça chunking e resumos — e então forneça os resumos mais os trechos relevantes, em vez de enviar arquivos inteiros em uma única chamada.
Segurança, conteúdo tóxico e mitigação de alucinações
- Use guardrails: mensagens de sistema, validadores externos e suítes de teste (por exemplo, testes unitários para código gerado) reduzem o risco.
- Valide referências externas: se o modelo citar fatos ou código da web, verifique programaticamente antes de confiar ou publicar esses resultados.
Quais são armadilhas comuns e como evitá-las
Armadilha: confiar demais em uma única saída do modelo
Mitigação: Execute testes, verificações estáticas e, para lógica crítica, solicite múltiplas conclusões independentes e compare. O CometAPI permite alternar entre diversos modelos, e você pode alternar entre eles a qualquer momento usando o formato de chat da OpenAI.
Armadilha: usar alta temperature para código de produção
Mitigação: Mantenha temperature baixa; se precisar de alternativas criativas, solicite múltiplas variações com baixa temperature ou peça ao modelo para explicar as diferenças.
Armadilha: ignorar versionamento de modelo
Mitigação: Acompanhe nomes de modelo e strings de provedor nos manifestos de implantação. Ao trocar de MiniMax-M2.5 para MiniMax-M2.5-highspeed ou para outro provedor, trate como uma mudança de release e execute testes de regressão.
Recomendações finais e expectativas realistas
MiniMax-M2.5 é um avanço notável para LLMs centrados em código e orientados a agentes — ele promete forte geração de código, raciocínio multi-turn e comportamento seguro no uso de ferramentas. Se as prioridades da sua equipe são construir ferramentas robustas para desenvolvedores, frameworks de agentes ou assistentes de código, o M2.5 merece um lugar na sua matriz de comparação. Usar o CometAPI como um gateway unificado pode acelerar a experimentação e permitir trocar de provedores ou fazer A/B de modelos sem reescrever toda a integração.
Alguns pontos pragmáticos:
- Prototipe rapidamente usando o playground do CometAPI e, depois, fixe os identificadores de modelo no código.
- Use baixa
temperature, peça testes e explicações, e sempre execute validação automatizada. - Trate o modelo como um poderoso co-desenvolvedor — não como infalível: aplique revisão humana, pipelines de CI e telemetria.
Desenvolvedores podem acessar MInimax-M2.5 via CometAPI agora. Para começar, explore as capacidades do modelo no Playground e consulte o guia da API para instruções detalhadas. Antes de acessar, certifique-se de que você fez login no CometAPI e obteve a chave de API. O CometAPI oferece um preço muito inferior ao oficial para ajudar na sua integração.
Pronto para começar?→ Inscreva-se no M2.5 hoje!
Se você quiser saber mais dicas, guias e notícias sobre IA, siga-nos no VK, X e Discord!