

O Claude Opus 4.6 da Anthropic chegou em fevereiro de 2026 como um avanço direcionado a agentes de nível empresarial, trabalho de conhecimento com contexto longo e codificação autônoma mais robusta. O lançamento combina engenharia ambiciosa (um modo beta com contexto de um milhão de tokens, uma capacidade de “raciocínio adaptativo” e recursos de trabalho em equipe entre agentes) com uma decisão comercial pragmática: a Anthropic manteve os preços da API consistentes com seus modelos anteriores da família Opus. Essa combinação — capacidades materialmente aprimoradas sem um aumento imediato de preço — é o principal destaque.
Afinal, o que é o Claude Opus 4.6?
O Claude Opus 4.6 é o carro-chefe da Anthropic na linha Opus: um modelo de IA generativa em grande escala, voltado para empresas, otimizado para fluxos de trabalho baseados em agentes, codificação e trabalho de conhecimento de longo prazo. A Anthropic posiciona o Opus 4.6 como seu modelo mais inteligente para construir agentes e automações — algo projetado não apenas para responder perguntas, mas para planejar, chamar ferramentas, coordenar subagentes e seguir tarefas de múltiplas etapas em grandes bases de código e corpora de documentos.
Diferente de chatbots voltados ao consumidor, o Opus 4.6 mira integrações empresariais: está disponível pela interface do claude.ai da Anthropic, pela API do Claude e via CometAPI. O ponto forte do Opus 4.6 são as tarefas de codificação baseadas em agentes e a chamada de ferramentas. Para as empresas, isso significa que o Opus 4.6 se posiciona como uma atualização plug‑and‑play para assistentes agentivos, ferramentas de migração de código, pipelines de revisão de documentos e fluxos analíticos que precisam de um contexto mais amplo do que sessões típicas de chat oferecem.
Análise detalhada dos principais novos recursos do Opus 4.6
Contexto de um milhão de tokens (e modos práticos)
O Opus 4.6 oferece uma janela de contexto padrão ampliada (anunciada em 200 mil tokens, com uma janela de 1 milhão de tokens disponível em beta). Uma janela de um milhão de tokens é transformadora no papel: ela permite ao modelo manter repositórios de código inteiros, longos memoriais jurídicos, arquivos de e-mails de vários anos ou grandes tabelas de dados em uma única conversa, reduzindo a necessidade de estruturas externas de recuperação. A Anthropic combina a janela de contexto bruta com ferramentas de “compactação de contexto” que ajudam a comprimir informações relevantes e reduzir custos de tokens. Em resumo: o Opus pode trabalhar de forma legítima com artefatos muito grandes sem cortá-los em fragmentos, o que simplifica a criação de agentes de longa duração.
Por que isso importa: para refatoração de código, revisão jurídica/financeira ou projetos de pesquisa que exigem raciocínio entre documentos, a janela maior reduz a sobrecarga de engenharia (menos recuperações, menos gerenciamento de estado) e melhora a coerência ao longo de cadeias de raciocínio muito longas.
Raciocínio adaptativo e controles de raciocínio estendido
O Opus 4.6 introduz o que a Anthropic chama de “raciocínio adaptativo” (uma evolução das ideias anteriores de “raciocínio estendido” da empresa). Isso é tanto uma capacidade interna quanto um controle de API: desenvolvedores podem ajustar os “níveis de esforço” do modelo e a profundidade do planejamento, permitindo que ele dedique mais computação a planejamentos complexos ou mantenha respostas curtas e rápidas para tarefas triviais.
Por que isso importa: fluxos de trabalho baseados em agentes são onde melhorias marginais de qualidade se compõem: melhor planejamento + coordenação significam menos correções humanas e uma execução autônoma mais confiável.
O que é “equipes de agentes” e orquestração agentiva?
O Opus 4.6 introduz suporte aprimorado para fluxos de trabalho agentivos: a capacidade de criar, coordenar e supervisionar múltiplos subagentes que dividem e conquistam tarefas. Os materiais da Anthropic (e relatos iniciais de parceiros) destacam que o Opus pode, de forma pró-ativa, criar subagentes, atribuir subtarefas, monitorar seu progresso e encerrar ou mudar estratégias conforme necessário — atuando efetivamente como um orquestrador leve para trabalhos complexos, de múltiplas etapas, de engenharia ou análise. Essa integração estreita entre planejamento, uso de ferramentas e correção de erros é um diferencial central para equipes com forte foco em automação.
Melhorias de API e ferramentas para integração empresarial
A Anthropic expandiu controles de API para compactação, persistência e chamada de ferramentas. O modelo suporta limites de saída maiores (a Anthropic menciona até 128K tokens de saída), semântica de recuperação mais refinada e integrações empresariais com Microsoft 365 e ambientes de desenvolvimento. O resultado prático é menos código de integração ao conectar o Opus a planilhas, apresentações e cadeias de ferramentas internas. A Anthropic integrou o Opus 4.6 a ferramentas de nível superior como o Claude Cowork (interfaces no-code) e atualizações do Claude Code que permitem a usuários não técnicos acessarem automação.
Como o Opus 4.6 se sai em benchmarks?
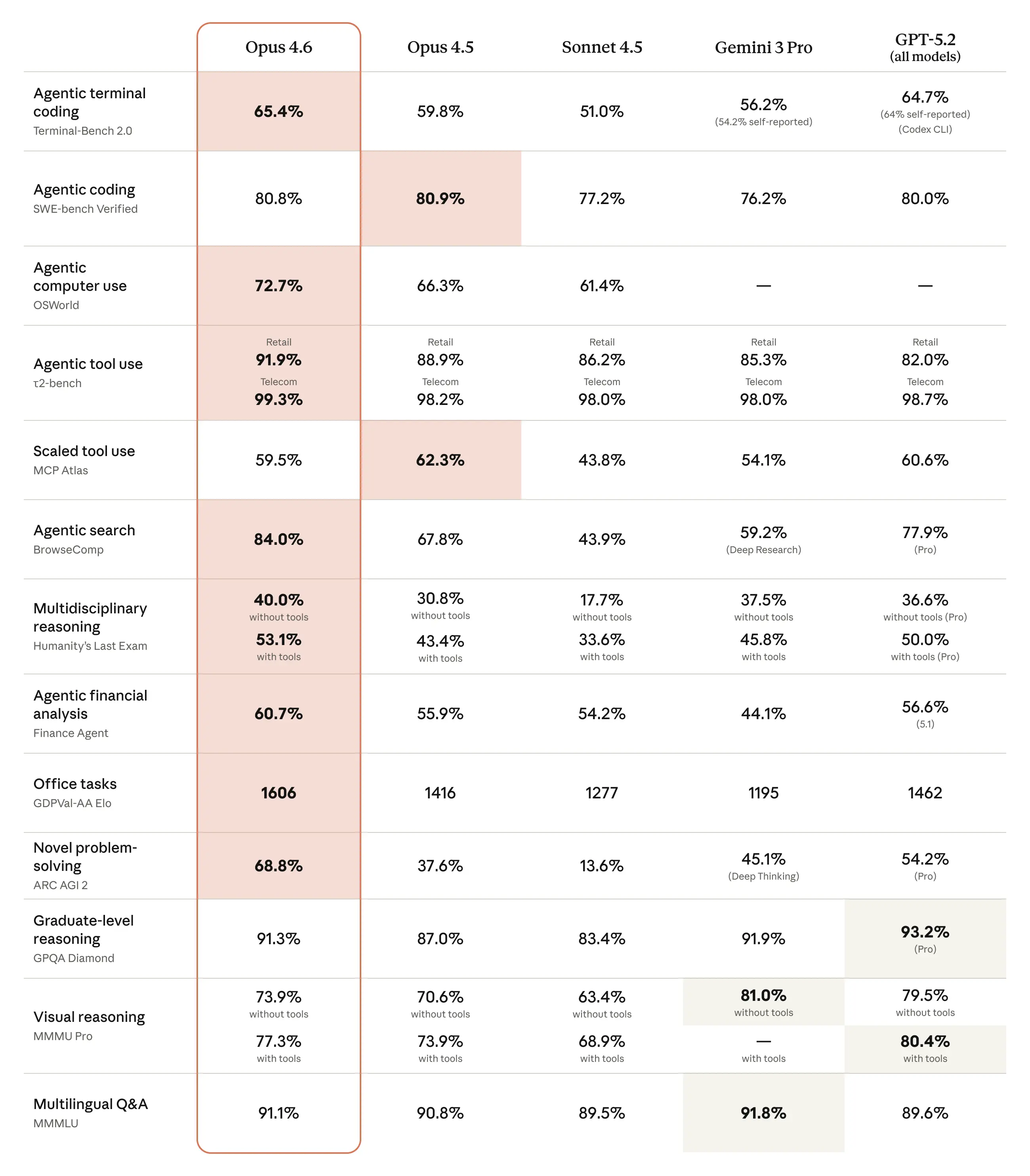
O Opus 4.6 traz ganhos em relação ao Opus 4.5 e mostra colocações competitivas frente a modelos recentes da OpenAI e do Google em um mix de suítes de codificação, raciocínio e domínio específico. Exemplos relatados, em resumo:
- BigLaw Bench: o Opus 4.6 alcançou ~90,2% no BigLaw Bench (raciocínio jurídico) da Anthropic.
- Terminal-Bench 2.0 / métricas GDPval: coberturas independentes listam pontuações do Terminal-Bench 2.0 e classificações Elo do GDPval-AA que colocam o Opus 4.6 à frente do Opus 4.5 e competitivo com alguns lançamentos recentes de rivais. Um relatório listou uma pontuação de 65,4% no Terminal-Bench 2.0 e Elo GDPval-AA ~1,606.
A Anthropic relata grandes ganhos em tarefas de codificação agentiva, com melhor planejamento, menos iterações e desempenho mais forte em enormes bases de código — incluindo alegações de planejar e executar migrações em repositórios com milhões de linhas em menos tempo. A capacidade aprimorada do modelo de “captar” os próprios erros e sustentar o raciocínio ao longo de muitos passos é enfatizada.
Quanto custa o Opus 4.6?
Resposta curta — preços por token
- Padrão (prompts ≤ 200K tokens): $5 / 1M tokens de entrada e $25 / 1M tokens de saída.
- Prompts grandes (prompts > 200K tokens): $10 / 1M de entrada e $37,50 / 1M de saída.
- Modo rápido (prévia de pesquisa): um nível premium — $30 / 1M de entrada e $150 / 1M de saída (inferência mais rápida).
Considerações práticas de custo:
- Fluxos agentivos tendem a ser caros em tokens. Planejamento em múltiplas etapas, chamadas de ferramentas e saídas longas aumentam os tokens de saída; uso cuidadoso de compactação e leituras de cache é importante para controlar a cobrança.
- Processamento em lote economiza dinheiro. Se sua carga de trabalho se adapta a processamento assíncrono em lote, os preços da API de lote da Anthropic podem reduzir materialmente o custo por token.
- Contexto premium é mais caro. Se você depende com frequência do beta de 1M tokens, planeje cobranças por token mais altas. Muitas organizações vão mesclar modos: contextos grandes apenas quando absolutamente necessários e sessões enxutas no restante.
Buscando soluções mais baratas para usar a Claude API
A CometAPI é uma boa escolha. A API do Opus 4.6 também vem da Anthropic, mas sua precificação de API é 20% do preço oficial, e isso não muda com alterações no comprimento de contexto.
Como o Opus 4.6 se compara ao GPT-5.3 e ao Google Gemini 3?
Opus 4.6 vs GPT-5.3 da OpenAI
O recente GPT-5.3 da OpenAI (com a marca “Codex” para tarefas de codificação/agentes) é explicitamente ajustado para codificação profunda e fluxos de trabalho ao estilo de agentes e reivindica pontuações líderes da indústria em vários benchmarks de engenharia (SWE-Bench Pro, Terminal-Bench). Coberturas iniciais sugerem que o GPT-5.3-Codex eleva o estado da arte em benchmarks de engenharia de software e planejamento agentivo, posicionando-o como o rival direto mais próximo do Opus 4.6 em tarefas puras de codificação e agentes. O Opus 4.6 — em contraste — enfatiza contexto extremamente longo e orquestração multiagente como diferenciais. Em suma: o GPT-5.3 parece otimizado para profundidade de engenharia bruta e domínio de benchmarks em testes voltados a desenvolvedores; o Opus 4.6 enfatiza amplitude em fluxos de trabalho empresariais de longo contexto e raciocínio de domínio.
Opus 4.6 vs Google Gemini 3?
O Gemini 3 do Google (e as variantes Gemini 3 Pro / Deep Think) foi destacado por forte desempenho em raciocínio abstrato, solução de problemas visuais e certos benchmarks de QA científica; também levou o raciocínio multimodal avançado além de seus predecessores. As coberturas posicionam o Gemini 3 como particularmente forte em suítes de raciocínio científico e visual, enquanto a vantagem do Opus 4.6 está em código de longo contexto e trabalho jurídico/empresarial. Para organizações que precisam de raciocínio científico multimodal ou tarefas avançadas de lógica visual, o Gemini 3 pode ter vantagem; para trabalho sustentado de conhecimento com contexto longo e automação multiagente, o Opus 4.6 faz sua aposta.
Quem “vence” em confrontos diretos?
Nenhum fornecedor “vence” universalmente: a escolha depende do fluxo de trabalho que importa para você. Comparações independentes iniciais mostram o Opus 4.6 superando o Opus 4.5 por uma margem significativa em tarefas de longo horizonte e de domínio, enquanto o GPT-5.3 e o Gemini 3 mantêm vantagens em certos testbeds de codificação e multimodais. Como em qualquer geração em rápida evolução, o vencedor é o cliente que mapeia os pontos fortes do modelo para cargas de trabalho reais e integração de ferramentas, não o modelo com o maior benchmark isolado.
Vale a pena o Claude Opus 4.6?
Resposta curta: Sim — se seus principais problemas são raciocínio de longo contexto, fluxos de trabalho com agentes autônomos ou compliance empresarial. As forças do Opus 4.6 são reais e relevantes: as janelas de 200K (e beta de 1M), o raciocínio adaptativo, as equipes de agentes e as integrações empresariais são upgrades tangíveis que reduzem a complexidade de engenharia de produto e ampliam a classe de problemas que você pode automatizar.
Se, em vez disso, sua carga de trabalho é predominantemente composta por microtarefas curtas e altamente repetitivas em que custo unitário e latência são primordiais, o Opus 4.6 pode ser exagero comparado a um modelo especializado de curto horizonte (por exemplo, GPT-5.3 Codex) — a menos que você planeje combiná-los e rotear as tarefas adequadamente.
A CometAPI é uma plataforma agregadora “one‑stop” para APIs de grandes modelos, oferecendo integração e gerenciamento contínuos de serviços de API. Ela suporta a chamada de diversos modelos de IA mainstream. Isso inclui geração de imagens, geração de vídeo, chat, TTS e STT de IA, tudo em uma única plataforma.
Você também pode escolher o modelo desejado com base no custo e nas capacidades do modelo, e alternar entre eles a qualquer momento, como Gemini 3 Flash, GPT 5.3 ou Opus 4.6. Antes de acessar, verifique se você fez login na CometAPI e obteve a chave de API. A CometAPI oferece um preço muito inferior ao oficial para ajudar na sua integração.
Pronto para começar?→ Inscreva-se para programar hoje
Se você quiser saber mais dicas, guias e novidades sobre IA, siga-nos no VK, X e Discord!