

O Kling O1 — lançado como parte da semana de lançamento "Omni" da Kling AI — se posiciona como um modelo único e unificado de base de vídeo multimodal que aceita texto, imagens e vídeos na mesma solicitação e pode gerar e editar vídeos em fluxos de trabalho iterativos de nível de diretor. A equipe da Kling anuncia o O1 como o "primeiro modelo unificado de vídeo multimodal em larga escala do mundo". Testes internos da Kling apontam vantagens significativas em relação ao Veo 3.1 do Google e ao Runway Aleph.
O que é Kling O1?
Kling O1 (frequentemente comercializado como Vídeo O1 or Omni UmO Kling O1 é um modelo de vídeo recém-lançado pela Kling AI que unifica a geração e a edição de texto, imagens e vídeo em uma única estrutura orientada por comandos. Em vez de tratar a conversão de texto em vídeo, de imagem em vídeo e a edição de vídeo como fluxos de trabalho separados, o Kling O1 aceita entradas mistas (texto + múltiplas imagens + vídeo de referência opcional) em um único comando, processa-as e produz clipes curtos coerentes ou edita filmagens existentes com controle preciso. A empresa posicionou o lançamento como parte de um "Lançamento Omni" e descreve o O1 como um "mecanismo de vídeo multimodal" construído em torno de um paradigma de Linguagem Visual Multimodal (MVL) e um caminho de raciocínio de Cadeia de Pensamento (CoT) para interpretar instruções criativas complexas e multipartes.
A mensagem de Kling enfatiza três fluxos de trabalho práticos: (1) geração de texto → vídeo, (2) imagem/elemento → vídeo (composição e troca de sujeito/objeto usando referências explícitas) e (3) edição de vídeo/continuação de tomada (reestilização, adição/remoção de objetos, controle de quadro inicial/final). O modelo suporta prompts com múltiplos elementos (incluindo uma sintaxe “@” para direcionar imagens de referência específicas) e apresenta controles no estilo de diretor, como ancoragem de quadro inicial/final e continuação de vídeo para criar sequências com múltiplas tomadas.
5 principais destaques do Kling O1
1) Entrada multimodal unificada verdadeira (MVL)
A principal funcionalidade do Kling O1 é processar texto, imagens estáticas (com múltiplas referências) e vídeo como entradas simultâneas de alta qualidade. Os usuários podem fornecer diversas imagens de referência (ou um pequeno clipe de referência). e Uma instrução em linguagem natural; o modelo analisará todas as entradas em conjunto para produzir ou editar uma saída coerente. Isso reduz o atrito na cadeia de ferramentas e possibilita fluxos de trabalho como "usar sujeito de". @image1, coloque-os no ambiente de @image2, combinar movimento com ref_video.mp4e aplicar a correção de cor cinematográfica X.” Essa estrutura de “Linguagem Visual Multimodal” (MVL) é fundamental para a proposta de Kling.
Por que isso é importante: Fluxos de trabalho criativos reais frequentemente exigem a combinação de referências: um personagem de um recurso, um movimento de câmera de outro e uma instrução narrativa em texto. Unificar essas entradas permite a geração em uma única passagem e reduz as etapas de composição manual.
2) Edição + geração em um único modelo (modo multi-elementos)
A maioria dos sistemas anteriores separava a geração (texto→vídeo) da edição com precisão de quadros. O1 combina-as intencionalmente: o mesmo modelo que cria um clipe do zero também pode editar imagens existentes — trocando objetos, remodelando roupas, removendo adereços ou estendendo uma cena — tudo por meio de instruções em linguagem natural. Essa convergência simplifica significativamente o fluxo de trabalho das equipes de produção.
O modelo O1 alcança uma integração profunda de múltiplas tarefas de vídeo em seu núcleo:
- Geração de texto para vídeo
- Geração de referência de imagem/assunto
- Edição e preenchimento de vídeo
- Reestilização de vídeo
- Geração de disparo seguinte/anterior
- Geração de vídeo com restrição de quadros-chave
A maior importância deste projeto reside no seguinte: processos complexos que antes exigiam múltiplos modelos ou ferramentas independentes agora podem ser concluídos em um único mecanismo. Isso não apenas reduz significativamente os custos de criação e computação, mas também estabelece as bases para o desenvolvimento de um “modelo unificado de compreensão e geração de vídeo”.
3) A coerência da geração de vídeo
Consistência de identidade: O modelo O1 aprimora os recursos de modelagem de consistência intermodal, mantendo a estabilidade da estrutura, do material, da iluminação e do estilo do objeto de referência durante o processo de geração:
- Suporta imagens de referência com múltiplas vistas para modelagem do sujeito;
- Isso garante consistência de assunto entre planos (características de personagem, objeto e cena permanecem contínuas em diferentes planos);
- Suporta referências híbridas com múltiplos sujeitos, permitindo a geração de retratos em grupo e a construção interativa de cenas.
Esse mecanismo melhora significativamente a coerência e a “consistência de identidade” da geração de vídeo, tornando-o adequado para cenários com requisitos de consistência extremamente altos, como publicidade e geração de cenas em nível cinematográfico.
Memória aprimorada: O modelo O1 também possui “memória”, impedindo que seu estilo de saída se torne instável devido a contextos longos ou instruções variáveis. Ele pode até:
- Memorizar vários caracteres simultaneamente;
- Permitir que diferentes personagens interajam no vídeo;
- Manter consistência no estilo, vestuário e postura.
4) Composição precisa com sintaxe “@” e controle de início/fim de quadro
Kling introduziu uma abreviação de composição (reportada como um sistema de menção “@”) para que você possa referenciar imagens específicas no prompt (por exemplo, @image1, @image2) para atribuir funções aos ativos de forma confiável. Combinado com a especificação explícita dos quadros de início e fim, isso permite que o diretor controle como os elementos fazem a transição, se movem ou se transformam ao longo do clipe gerado — um conjunto de recursos voltado para a produção que diferencia o O1 de muitos geradores voltados para o consumidor.
5) Saídas de alta fidelidade e duração relativamente longa, além de empilhamento de múltiplas tarefas.
O Kling O1 é capaz de produzir vídeos cinematográficos em 1080p (30fps) e — com base nas versões anteriores do Kling — a empresa destaca a geração de clipes mais longos (com relatos de até 2 minutos em análises recentes do produto). Ele também suporta a execução de múltiplas tarefas criativas em uma única solicitação (gerar, adicionar um objeto, alterar a iluminação e editar a composição). Essas características o tornam competitivo com os mecanismos de conversão de texto em vídeo de nível superior.
Por que isso é importante: Clipes mais longos e de alta fidelidade, juntamente com a capacidade de combinar edições, reduzem a necessidade de juntar muitos clipes curtos e simplificam a produção de ponta a ponta.
Como é arquitetada a Kling O1 e quais são os mecanismos subjacentes?
O1 em torno de um Linguagem Visual Multimodal (MVL) Núcleo: um modelo que aprende representações conjuntas para linguagem + imagens + sinais de movimento (quadros de vídeo e características de fluxo óptico) e, em seguida, aplica decodificadores baseados em difusão ou transformadores para sintetizar quadros temporalmente coerentes. O modelo é descrito como realizando condicionamento com base em múltiplas referências (texto; imagens de um para muitos; videoclipes curtos) para produzir uma representação de vídeo latente que é então decodificada em imagens por quadro, preservando a consistência temporal por meio de atenção entre quadros ou módulos temporais especializados.
1. Transformador Multimodal + Arquitetura de Contexto Longo
O modelo O1 emprega a arquitetura Transformer multimodal desenvolvida por Keling, integrando sinais de texto, imagem e vídeo, e suportando memória de contexto temporal de longo prazo (Multimodal Long Context).
Isso permite que o modelo compreenda a continuidade temporal e a consistência espacial durante a geração de vídeo.
2. MVL: Linguagem Visual Multimodal
MVL é a principal inovação dessa arquitetura.
Alinha profundamente os sinais linguísticos e visuais dentro do Transformer por meio de uma camada intermediária semântica unificada, da seguinte forma:
- Permitir que uma única caixa de entrada misture instruções multimodais;
- Aprimorar a capacidade do modelo de compreender com precisão as descrições em linguagem natural;
- Suporte para geração de vídeo interativo altamente flexível.
A introdução do MVL marca uma mudança na geração de vídeo, passando de uma abordagem "orientada por texto" para uma abordagem "coorientada semântico-visual".
3. Mecanismo de Inferência em Cadeia de Pensamento
O modelo O1 introduz um caminho de inferência de "Cadeia de Pensamento" durante a fase de geração de vídeo.
Esse mecanismo permite que o modelo execute a lógica de eventos e a dedução de tempo antes da geração, mantendo assim uma conexão natural entre ações e eventos dentro do vídeo.
Pipelines de inferência e edição
- Geração: Feed: (texto + referências de imagem opcionais + referências de vídeo opcionais + configurações de geração) → o modelo produz quadros de vídeo latentes → decodificação em quadros → pós-processamento opcional de cor/temporal.
- Edição baseada em instruções: Feed: (vídeo original + instrução em texto + referências de imagem opcionais) → o modelo mapeia internamente a edição solicitada para um conjunto de transformações no espaço de pixels e, em seguida, sintetiza os quadros editados, preservando o conteúdo inalterado. Como tudo está em um único modelo, os mesmos módulos de condicionamento e temporais são usados tanto para a criação quanto para a edição.
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
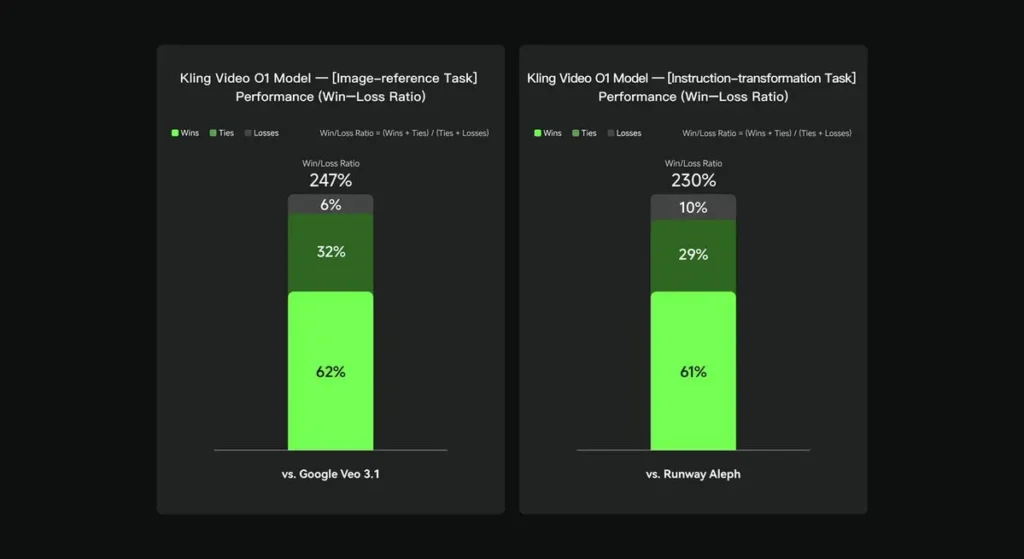
Em avaliações internas, o Keling Video O1 superou significativamente seus concorrentes internacionais em diversas dimensões-chave. Resultados de desempenho (com base no conjunto de avaliação próprio da Keling AI):
- Tarefa “Referência de Imagem”: O O1 supera o Google Veo 3.1 no geral, com uma taxa de sucesso de 247%;
- Tarefa "Transformação de Instruções": O1 supera Runway Aleph, com uma taxa de sucesso de 230%.
Visão geral da concorrência (comparação em nível de funcionalidade)
| Capacidade / Modelo | Kling O1 | Google Veo 3.1 | Pista (Aleph / Gen-4.5) |
|---|---|---|---|
| Prompt multimodal unificado (texto + imagens + vídeo) | **Sim (principal argumento de venda)**Fluxos multimodais de solicitação única. | Parcial — texto→vídeo + referências existem; menos ênfase em um MVL único e unificado. | O modo Runway foca na geração e edição, mas frequentemente em modos separados; a versão mais recente, Gen-4.5, reduz essa diferença. |
| Edições de pixels conversacionais/baseadas em texto | Sim — “editar como uma conversa” (sem máscaras). | Parcial — a edição existe, mas os fluxos de trabalho com máscara/quadro-chave ainda são comuns. | O Runway possui ferramentas de edição robustas; o Runway afirma oferecer transformações de instruções avançadas (varia conforme a versão). |
| Controle de início/fim de quadro e referência da câmera | Sim — Descrição explícita dos movimentos da câmera de início/fim e de referência. | Limitado/em evolução | Pista de pouso: controles aprimorados; experiência do usuário não exatamente a mesma. |
| Geração de clipes longos (alta fidelidade) | até ~2 minutos (1080p, 30fps) em materiais de produtos e publicações da comunidade; | Veo 3.1: forte coerência, mas versões anteriores tinham valores padrão mais curtos; varia conforme o modelo/configuração. | Runway Gen-4.5: visa alta qualidade; duração/fidelidade varia. |
Conclusão:
O que tornou Kling O1 famoso publicamente é unificação do fluxo de trabalho: atribuir a um único modelo a capacidade de compreender texto, imagens e vídeo, e de realizar tanto a geração quanto a edição avançada baseada em instruções, tudo dentro do mesmo sistema semântico. Para criadores e equipes que transitam frequentemente entre as etapas de "criar", "editar" e "estender", essa consolidação pode simplificar drasticamente a velocidade de iteração e a complexidade das ferramentas. Aprimoramentos na consistência temporal, controle de quadros de início e fim e integrações pragmáticas com plataformas tornam a solução acessível aos criadores.
A API Kling Video o1 estará disponível em breve na CometAPI.
Os desenvolvedores podem acessar Turbina Kling 2.5 e API do Veo 3.1 através de CometAPI, os modelos mais recentes listados são da data de publicação do artigo. Para começar, explore as capacidades do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.
Pronto para ir?→ Inscreva-se no CometAPI hoje mesmo !
Se você quiser saber mais dicas, guias e novidades sobre IA, siga-nos em VK, X e Discord!